本页面介绍了敏感数据发现服务。此服务可帮助您确定组织中的敏感数据和高风险数据所在的位置。
概览
借助发现服务,您可以通过识别敏感和高风险数据所在位置来保护整个组织中的数据。创建发现扫描配置后,Sensitive Data Protection 会扫描您的资源,以确定要进行分析的数据范围。然后,它会生成数据分析文件。只要发现配置处于活跃状态,Sensitive Data Protection 就会自动分析您添加和修改的数据。您可以生成整个组织、单个文件夹和单个项目的数据剖析。
每个数据剖析文件都是发现服务通过扫描受支持的资源而收集的一组数据洞见和元数据。分析洞见包括预测的 infoTypes 以及计算出的数据风险和敏感度级别。使用这些数据洞见来就如何保护、共享和使用您的数据做出明智的决策。
系统会生成不同详细程度的数据分析文件。例如,在分析 BigQuery 数据时,系统会在项目、表和列级别生成剖析文件。
下图显示了列级数据剖析文件的列表。点击图片可放大。

如需查看每个数据剖析文件中包含的数据洞见和元数据列表,请参阅指标参考文档。
如需详细了解 Google Cloud 资源层次结构,请参阅资源层次结构。
生成数据剖析文件
如需开始生成数据分析文件,您需要创建发现扫描配置(也称为数据分析文件配置)。此扫描配置用于设置发现操作的范围以及要分析的数据类型。在扫描配置中,您可以设置过滤条件来指定要分析或跳过的数据子集。您还可以设置分析时间表。
创建扫描配置时,您还需要设置要使用的检查模板。您可以在检查模板中指定 Sensitive Data Protection 必须扫描的敏感数据类型(也称为 infoTypes)。
Sensitive Data Protection 创建数据剖析文件后,会根据您的扫描配置和检查模板分析数据。
Sensitive Data Protection 会按照生成数据分析文件的频率中所述的方式重新分析数据。您可以通过创建时间表,在扫描配置中自定义分析频率。如需强制发现服务重新分析您的数据,请参阅强制执行重新分析操作。
发现类型
本部分介绍了您可以执行的发现操作类型以及支持的数据资源。
BigQuery 和 BigLake 的发现功能
对 BigQuery 数据进行分析时,系统会在项目、表和列级别生成数据剖析文件。对 BigQuery 表进行分析后,您可以执行深度检查,进一步调查分析结果。
敏感数据保护功能可剖析 BigQuery Storage Read API 支持的表,包括以下表:
- 标准 BigQuery 表
- 表快照
- 存储在 Cloud Storage 中的 BigLake 表
不支持:
- BigQuery Omni 表。
- 单个行的序列化数据大小超过 BigQuery Storage Read API 支持的最大序列化数据大小(128 MB)的表。
- 非 BigLake 外部表,例如 Google 表格。
如需了解如何剖析 BigQuery 数据,请参阅以下内容:
如需详细了解 BigQuery,请参阅 BigQuery 文档。
Cloud SQL 的 Discovery
对 Cloud SQL 数据进行分析时,系统会在项目、表和列级别生成数据剖析文件。在开始发现之前,您需要为要进行分析的每个 Cloud SQL 实例提供连接详细信息。
如需了解如何分析 Cloud SQL 数据,请参阅以下内容:
如需详细了解 Cloud SQL,请参阅 Cloud SQL 文档。
Cloud Storage 发现
对 Cloud Storage 数据进行分析时,系统会在存储桶级别生成数据分析文件。Sensitive Data Protection 会将检测到的文件分组为文件集群,并为每个集群提供摘要。
如需了解如何分析 Cloud Storage 数据,请参阅以下内容:
如需详细了解 Cloud Storage,请参阅 Cloud Storage 文档。
Discovery for Vertex AI
对 Vertex AI 数据集进行分析时,Sensitive Data Protection 会生成文件存储区数据剖析结果或表格数据剖析结果,具体取决于训练数据的存储位置:Cloud Storage 或 BigQuery。
详情请参阅以下内容:
如需详细了解 Vertex AI,请参阅 Vertex AI 文档。
其他云服务提供商的发现
对 S3 数据进行分析时,系统会在存储桶级层生成数据分析。对 Azure Blob Storage 数据进行分析时,系统会在容器级别生成数据分析。
在这两种情况下,敏感数据保护功能都会将检测到的文件分组到文件集群中,并为每个集群提供摘要。
详情请参阅以下内容:
Cloud Run 环境变量
发现服务可以检测 Cloud Run functions 函数和 Cloud Run 服务修订版本环境变量中是否存在密钥,并将所有发现结果发送到 Security Command Center。未生成任何数据分析文件。
如需了解详情,请参阅向 Security Command Center 报告环境变量中的 Secret。
配置和查看数据剖析文件所需的角色
以下各部分列出了所需的用户角色(根据其用途进行分类)。您可以根据组织的设置方式,让不同人员执行不同的任务。例如,配置数据剖析文件的人员可能与定期监控数据剖析文件的人员不同。
在组织或文件夹级层使用数据剖析文件所需的角色
这些角色可让您在组织或文件夹级层配置和查看数据剖析文件。
确保在组织级层向适当的人员授予这些角色。或者,您的 Google Cloud 管理员可以创建自定义角色,使他们仅具有相关权限。
| 用途 | 预定义角色 | 相关权限 |
|---|---|---|
| 创建发现扫描配置并查看数据剖析文件 | DLP Administrator (roles/dlp.admin)
|
|
| 创建要用作服务代理容器的项目1 | Project Creator (roles/resourcemanager.projectCreator) |
|
| 授予发现访问权限2 | 下列其中一项:
|
|
| 查看数据剖析文件(只读) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
DLP Reader (roles/dlp.reader) |
|
1 如果您没有 Project Creator (roles/resourcemanager.projectCreator) 角色,您仍然可以创建扫描配置,但您使用的服务代理容器必须是现有项目。
2 如果您没有组织管理员 (roles/resourcemanager.organizationAdmin) 或 Security Admin (roles/iam.securityAdmin) 角色,您仍然可以创建扫描配置。创建扫描配置后,您组织中拥有以下任一角色的人员必须向服务代理授予发现权限。
在项目级层使用数据剖析文件所需的角色
这些角色使您可以在项目级层配置和查看数据剖析文件。
确保在项目级层向这些人员授予这些角色。或者,您的 Google Cloud 管理员可以创建自定义角色,使他们仅具有相关权限。
| 用途 | 预定义角色 | 相关权限 |
|---|---|---|
| 配置和查看数据剖析文件 | DLP Administrator (roles/dlp.admin)
|
|
| 查看数据剖析文件(只读) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
DLP Reader (roles/dlp.reader) |
|
发现扫描配置
发现扫描配置(有时称为发现配置或扫描配置)用于指定 Sensitive Data Protection 应如何分析您的数据。其中包括以下设置:
- 发现操作的范围(组织、文件夹或项目)
- 要分析的资源类型
- 检查模板
- 扫描频率
- 应在发现中包含或排除的特定数据子集
- 您希望 Sensitive Data Protection 在发现后采取的操作,例如要将剖析文件发布到哪些 Google Cloud 服务
- 用于发现操作的服务代理
如需了解如何创建发现扫描配置,请参阅以下页面:
BigQuery 数据探索
Cloud SQL 数据发现
Cloud Storage 数据的发现
Vertex AI 数据探索
向 Security Command Center 报告 Cloud Run 环境变量中的 Secret(不生成配置文件)
扫描配置范围
您可以在以下级别创建扫描配置:
- 组织
- 文件夹
- 项目
- 单个数据资源
在组织级层和文件夹级层,如果两个或多个活跃扫描配置在其范围内具有相同的项目,则 Sensitive Data Protection 会确定哪个扫描配置可以为该项目生成分析文件。如需了解详情,请参阅本页面上的替换扫描配置。
项目级扫描配置始终可对目标项目进行数据分析,并且不会与父文件夹或组织级层的其他配置发生冲突。
单资源扫描配置旨在帮助您探索和测试单个数据资源的分析。
扫描配置位置
首次创建扫描配置时,您可以指定其在 Sensitive Data Protection 中的存储位置。您创建的所有后续扫描配置都存储在这个区域中。
例如,如果您为文件夹 A 创建了一个扫描配置并将其存储在 us-west1 区域中,则您后续为任何其他资源创建的所有扫描配置也都会存储在该区域中。
要进行分析的数据的元数据会复制到与扫描配置相同的区域,但数据本身不会移动或复制。如需了解详情,请参阅数据驻留注意事项。
检查模板
检查模板指定 Sensitive Data Protection 在扫描数据时要查找的信息类型(或 infoType)。在这里,您可以结合使用内置信息类型和可选的自定义信息类型。
您还可以提供可能性级别,以缩小 Sensitive Data Protection 认为匹配的范围。您可以添加规则集以排除不需要的发现结果或添加其他发现结果。
默认情况下,如果您更改扫描配置使用的检查模板,所做的更改仅会应用于将来的扫描。您的操作不会对数据进行重新分析。
如果您希望检查模板更改触发对受影响数据的重新分析操作,请在扫描配置中添加或更新时间表,并开启“在检查模板更改时重新分析数据”选项。如需了解详情,请参阅生成数据剖析文件的频率。
您必须在每个包含要剖析的数据的区域中都有一个检查模板。如果您想在多个区域中使用单个模板,可以使用存储在 global 区域中的模板。如果组织政策禁止您在 global 区域中创建检查模板,则您必须为每个区域设置专用检查模板。如需了解详情,请参阅数据驻留注意事项。
检查模板是 Sensitive Data Protection 平台的核心组件。数据剖析文件使用您可以在所有 Sensitive Data Protection 服务中使用的检查模板。如需详细了解检查模板,请参阅模板。
服务代理容器和服务代理
为组织或文件夹创建扫描配置时,Sensitive Data Protection 会要求您提供服务代理容器。服务代理容器是 Sensitive Data Protection 用于跟踪与组织级和文件夹级分析操作相关的账单费用的 Google Cloud 项目。
服务代理容器包含一个服务代理,Sensitive Data Protection 会使用该代理代表您分析数据。您需要服务代理来向 Sensitive Data Protection 和其他 API 进行身份验证。您的服务代理必须具有访问和剖析数据所需的所有权限。服务代理的 ID 采用以下格式:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
其中,PROJECT_NUMBER 是服务代理容器的数字标识符。
设置服务代理容器时,您可以选择现有项目。如果您选择的项目包含服务代理,Sensitive Data Protection 会向该服务代理授予必需的 IAM 权限。如果项目没有服务代理,Sensitive Data Protection 会创建一个服务代理并自动向其授予数据剖析访问权限。
或者,您可以选择让 Sensitive Data Protection 自动创建服务代理容器和服务代理。Sensitive Data Protection 会自动向服务代理授予数据剖析访问权限。
在这两种情况下,如果 Sensitive Data Protection 未能向服务代理授予数据剖析访问权限,当您查看扫描配置详细信息时,Sensitive Data Protection 会显示错误。
对于项目级层扫描配置,您不需要服务代理容器。您进行数据分析的项目会充当服务代理容器。为了运行分析操作,敏感数据保护功能会使用相应项目自己的服务代理。
组织或文件夹级层的数据剖析访问权限
当您在组织或文件夹级层配置剖析时,敏感数据保护会尝试自动向您的服务代理授予数据剖析访问权限。但是,如果您没有授予 IAM 角色的权限,则 Sensitive Data Protection 无法代表您执行此操作。您的组织中具有这些权限的人员(例如 Google Cloud 管理员)必须向您的服务代理授予数据剖析访问权限。
数据剖析文件的生成频率
为特定资源创建发现扫描配置后,Sensitive Data Protection 会执行初始扫描,并剖析扫描配置范围内的所有数据。
初始扫描完成后,Sensitive Data Protection 会持续监控已分析的资源。资源中添加的数据会在添加后不久自动进行分析。
默认重新分析频率
默认重新分析频率因扫描配置的发现类型而异:
- BigQuery 分析:对于每个表,等待 30 天,然后重新分析该表(如果其架构、表行或检查模板发生了更改)。
- Cloud SQL 分析:对于每个表,等待 30 天,然后重新分析架构或检查模板发生更改的表。
- Vertex AI 分析:对于每个数据集,等待 30 天,然后重新分析数据集(如果检查模板有更改)。
文件存储空间分析:对于 Google Cloud 或其他云中的每个文件存储空间,等待 30 天,然后重新分析文件存储空间(如果检查模板有更改)。
Sensitive Data Protection 使用“文件存储区”一词来指代文件存储桶或容器。
自定义重新分析频率
在扫描配置中,您可以为不同的数据子集创建一个或多个时间表,从而自定义重新分析频率。
以下重新分析频率可供选择:
- 不重新分析:在生成初始配置文件后,绝不重新分析。
- 每日重新分析:等待 24 小时,然后再重新分析。
- 每周重新分析:等待 7 天后再重新分析。
- 每月重新分析:等待 30 天,然后重新分析。
按时间表重新分析
在扫描配置中,您可以指定是否应定期重新分析部分数据,无论这些数据是否发生过更改。您设置的频率指定了两次分析操作之间必须经过的时间。例如,如果您将频次设置为“每周”,Sensitive Data Protection 会在上次分析数据资源后的 7 天再次分析该资源。
更新时重新配置
在扫描配置中,您可以指定可触发重新分析操作的事件。此类事件的示例包括检查模板更新。
选择这些事件后,您设置的安排将指定敏感数据保护功能在重新分析数据之前等待更新累积的最长时间。如果在指定的时间段内未发生任何适用的更改(例如架构更改或检查模板更改),系统不会重新分析数据。当下次发生适用的更改时,系统会在下次机会出现时重新分析受影响的数据,而下次机会取决于多种因素(例如可用的机器容量或购买的订阅单位数)。然后,Sensitive Data Protection 会开始等待再次根据您设置的安排累积更新。
例如,假设您的扫描配置设置为在架构发生更改时每月重新分析一次。数据分析文件最初是在第 0 天创建的。第 30 天之前未发生任何架构更改,因此不会重新分析任何数据。在第 35 天,首次发生架构更改。Sensitive Data Protection 会在下次有机会时重新分析更新后的数据。然后,系统会再等待 30 天,以便累积架构更新,然后再重新分析任何更新的数据。
从重新配置开始到操作完成,最长可能需要 24 小时。如果延迟时间超过 24 小时,并且您处于订阅价格模式,请确认您是否还有当月的剩余容量。
如需查看示例场景,请参阅数据剖析价格示例。
如需强制发现服务重新分析您的数据,请参阅强制执行重新分析操作。
分析性能
分析数据所需的时间因多种因素而异,包括但不限于以下因素:
- 正在分析的数据资源数量
- 数据资源的大小
- 对于表,列数
- 对于表格,列中的数据类型
因此,Sensitive Data Protection 在之前的检查或分析任务中的表现并不能表明它在未来的分析任务中的表现。
数据剖析文件的保留期限
Sensitive Data Protection 会将最新版本的数据剖析文件保留 13 个月。当 Sensitive Data Protection 重新分析数据资源时,系统会将该数据资源的现有剖析文件替换为新的剖析文件。
在以下示例场景中,假设 BigQuery 的默认分析频率处于有效状态:
在 1 月 1 日,Sensitive Data Protection 会分析表 A。表 A 有一年多没有变化,因此不再进行分析。在这种情况下,敏感数据保护会将表 A 的数据剖析文件保留 13 个月,然后才删除它们。
在 1 月 1 日,Sensitive Data Protection 会分析表 A。一个月内,您组织中的某个人更新了该表的架构。由于此更改,下个月,Sensitive Data Protection 会自动重新剖析表 A。新生成的数据剖析文件会覆盖 1 月创建的剖析文件。
如需了解 Sensitive Data Protection 如何针对数据剖析收费,请参阅 Discovery 价格。
如果您想要无限期保留数据剖析文件或保留其更改记录,请考虑在配置数据剖析时将数据剖析文件保存到 BigQuery。您需要选择将要保存剖析文件的 BigQuery 数据集,并控制该数据集的表过期时间政策。
替换扫描配置
对于每种范围和发现类型组合,您只能创建一个扫描配置。例如,您只能为 BigQuery 数据分析文件创建一项组织级扫描配置,并为密钥发现创建一项组织级扫描配置。同样,您只能为 BigQuery 数据分析创建一个项目级扫描配置,为密文发现创建一个项目级扫描配置。
如果两个或多个活跃扫描配置范围包含同一项目和发现类型,则以下规则适用:
- 在组织级层和文件夹级层扫描配置中,最接近项目的配置将能够为该项目运行发现操作。即使存在具有相同发现类型的项目级扫描配置,此规则也适用。
- Sensitive Data Protection 会独立于组织级层和文件夹级层配置,对项目级层扫描配置进行处理。您在项目级层创建的扫描配置不会覆盖您为父文件夹或组织创建的扫描配置。
请参阅以下示例,其中包含三个活跃扫描配置。 假设所有这些扫描配置都是针对 BigQuery 数据分析的。
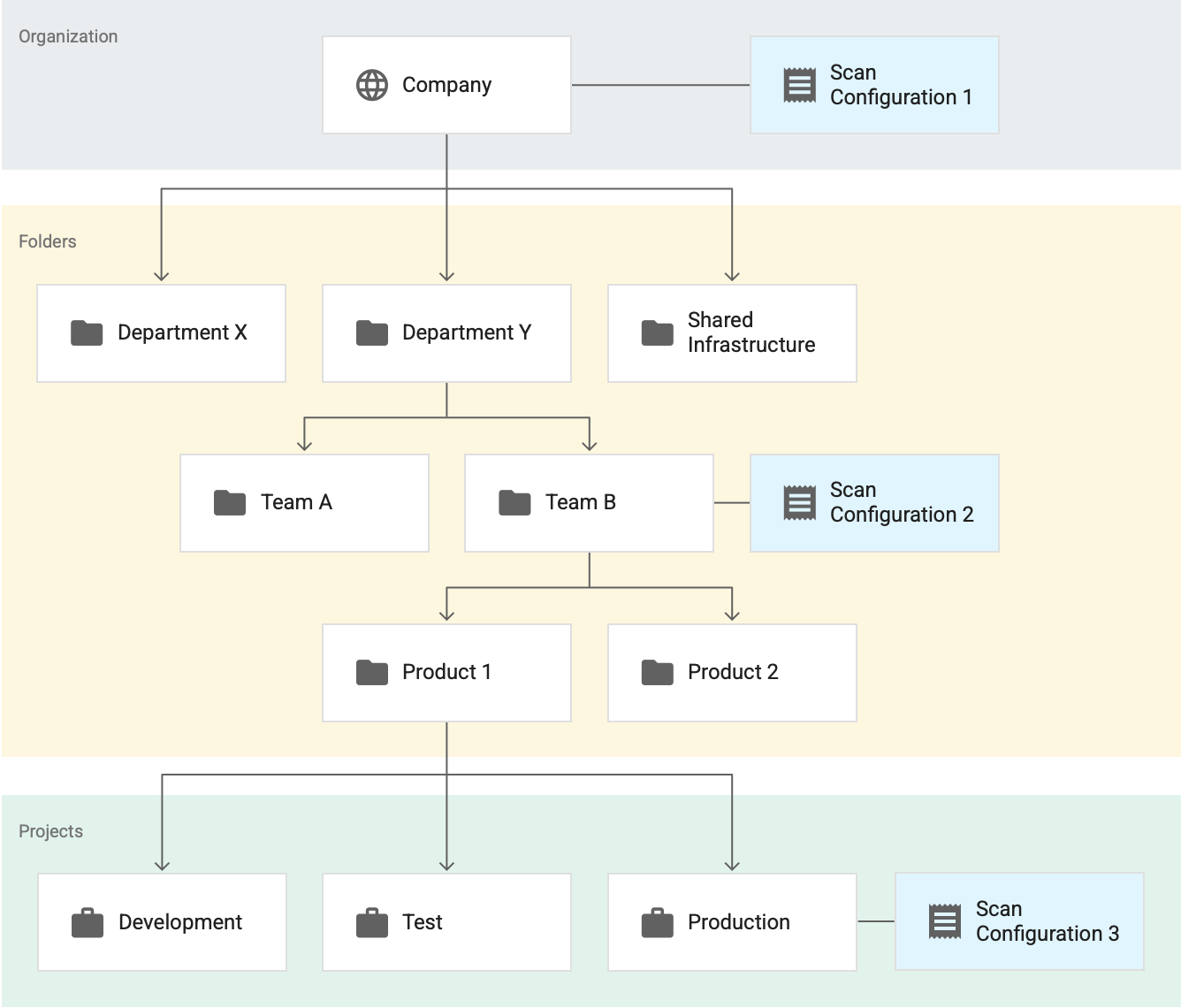
在这里,扫描配置 1 应用于整个组织、扫描配置 2 应用于 Team B 文件夹、扫描配置 3 则应用于 Production 项目。在此示例中:
- 敏感数据保护会根据扫描配置 1 对非 Team B 文件夹下的项目中的所有表进行数据分析。
- 敏感数据保护会根据扫描配置 2 对 Team B 文件夹下的项目(包括 Production 项目)中的所有表进行数据分析。
- Sensitive Data Protection 会根据扫描配置 3 对 Production 项目中的所有表进行数据分析。
在此示例中,Sensitive Data Protection 会为 Production 项目生成两组数据分析文件,以下每种扫描配置对应一组数据分析文件:
- 扫描配置 2
- 扫描配置 3
但是,即使同一项目有两组数据分析文件,您也不会在信息中心中同时看到它们。您只能看到当前所查看资源(组织、文件夹或项目)和区域中生成的数据剖析文件。
如需详细了解 Google Cloud的资源层次结构,请参阅资源层次结构。
数据剖析文件快照
每个数据剖析文件都包含扫描配置的快照以及用于生成此配置的检查模板。您可以使用此快照来检查用于生成特定数据剖析文件的设置。
数据驻留注意事项
数据驻留注意事项因您扫描的是Google Cloud 数据还是来自其他云服务提供商的数据而异。
Google Cloud 数据的数据驻留注意事项
本部分仅适用于 Google Cloud资源的敏感数据发现。如需了解与来自其他云服务提供商的资源相关的数据驻留注意事项,请参阅本页面上的来自其他云服务提供商的数据的数据驻留注意事项。
Sensitive Data Protection 旨在支持数据驻留。如果您必须遵守数据驻留要求,请考虑以下几点:
区域级检查模板
本部分仅适用于 Google Cloud资源的敏感数据发现。如需了解与来自其他云服务提供商的资源相关的数据驻留注意事项,请参阅本页面上的来自其他云服务提供商的数据的数据驻留注意事项。
Sensitive Data Protection 会在存储数据的同一区域处理数据。也就是说,您的数据不会离开其当前区域。
此外,检查模板只能用于剖析与该模板位于同一区域的数据。例如,如果您将发现功能配置为使用存储在 us-west1 区域的检查模板,则 Sensitive Data Protection 只能剖析该区域中的数据。
您可以为存储了数据的每个区域设置专用检查模板。
如果您提供的检查模板存储在 global 区域,则敏感数据保护功能会使用该模板来检查没有专用检查模板的区域中的数据。
下表提供了示例场景:
| 情况 | 支持 |
|---|---|
使用 us 区域中的检查模板扫描 us 区域中的数据。 |
支持 |
使用 us 区域中的检查模板扫描 global 区域中的数据。 |
不支持 |
使用 global 区域中的检查模板扫描 us 区域中的数据。 |
支持 |
使用 us-east1 区域中的检查模板扫描 us 区域中的数据。 |
不支持 |
使用 us 区域中的检查模板扫描 us-east1 区域中的数据。 |
不支持 |
使用 asia 区域中的检查模板扫描 us 区域中的数据。 |
不支持 |
数据剖析文件配置
本部分仅适用于 Google Cloud资源的敏感数据发现。如需了解与来自其他云服务提供商的资源相关的数据驻留注意事项,请参阅本页面上的来自其他云服务提供商的数据的数据驻留注意事项。
Sensitive Data Protection 创建数据剖析文件后,它会截取您的扫描配置和检查模板的快照,并将其存储在每个表数据剖析文件或文件存储区数据剖析文件中。如果您将发现功能配置为使用 global 区域中的检查模板,则 Sensitive Data Protection 会将该模板复制到包含要剖析的数据的任何区域。同样,它会将扫描配置复制到这些区域。
假设此示例:项目 A 包含表 1。表 1 位于 us-west1 区域;扫描配置位于 us-west2 区域;检查模板位于 global 区域。
当 Sensitive Data Protection 扫描项目 A 时,它会为表 1 创建数据剖析文件并将其存储在 us-west1 区域。表 1 的表数据剖析文件包含扫描配置的副本以及剖析操作中使用的检查模板。
如果您不希望将您的检查模板复制到其他区域,请不要将敏感数据保护功能配置为扫描这些区域中的数据。
数据剖析文件的区域存储
本部分仅适用于 Google Cloud资源的敏感数据发现。如需了解与来自其他云服务提供商的资源相关的数据驻留注意事项,请参阅本页面上的来自其他云服务提供商的数据的数据驻留注意事项。
敏感数据保护功能会在数据所在的区域或多区域中处理数据,并将生成的数据分析结果存储在同一区域或多区域中。
如需在 Google Cloud 控制台中查看数据剖析文件,您必须先选择它们所在的区域。如果您在多个区域中有数据,则必须切换区域才能查看每组剖析文件。
不支持的区域
本部分仅适用于 Google Cloud资源的敏感数据发现。如需了解与来自其他云服务提供商的资源相关的数据驻留注意事项,请参阅本页面上的来自其他云服务提供商的数据的数据驻留注意事项。
如果您的数据位于 Sensitive Data Protection 不支持的区域,则发现服务会跳过这些数据资源,并在您查看数据剖析文件时显示错误。
多区域
Sensitive Data Protection 将多区域视为一个区域,而不是区域的集合。例如,就数据驻留而言,us 多区域和 us-west1 区域被视为两个单独的区域。
可用区级资源
Sensitive Data Protection 是一项区域级和多区域级服务,不会区分可用区。对于受支持的可用区级资源(例如 Cloud SQL 实例),数据会在其当前区域中处理,但不一定在其当前可用区中处理。例如,如果 Cloud SQL 实例存储在 us-central1-a 可用区中,Sensitive Data Protection 会在 us-central1 区域中处理和存储数据剖析。
如需简要了解 Google Cloud 位置,请参阅地理位置和区域。
来自其他云提供商的数据的数据驻留注意事项
如果您计划分析来自其他云提供商的数据,请考虑以下事项:
- 数据分析文件与发现扫描配置一起存储。相比之下,当您对 Google Cloud 数据进行剖析时,剖析文件会存储在要剖析的数据所在的同一区域中。
- 如果您将检查模板存储在
global区域,系统会在您存储发现扫描配置的区域中读取该模板的内存中副本。 - 您的数据不会被修改。系统会在您存储发现扫描配置的区域中读取数据的内存中副本。不过,Sensitive Data Protection 无法保证数据在到达公共互联网后会通过哪些位置。数据通过 SSL 加密。
合规性
如需了解 Sensitive Data Protection 如何处理您的数据以及如何帮助您满足合规性要求,请参阅数据安全。
后续步骤
阅读身份验证和安全博文使用敏感数据保护功能自动管理 BigQuery 的数据风险。
了解如何估算数据分析费用。
了解 Sensitive Data Protection 如何在分析数据时计算数据风险和敏感度等级。
了解如何修复发现结果。
了解如何使用数据性能分析器排查问题。