Generalisasi adalah proses pengambilan nilai yang membedakan dan mengabstraksikannya menjadi nilai yang lebih umum dan kurang membedakan. Generalisasi berupaya mempertahankan utilitas data sekaligus mengurangi identifikasi data.
Ada banyak tingkat generalisasi, bergantung pada jenis data. Seberapa banyak generalisasi yang diperlukan adalah sesuatu yang dapat Anda ukur di seluruh set data atau populasi dunia nyata menggunakan teknik seperti yang disertakan dalam analisis risiko Sensitive Data Protection.
Salah satu teknik generalisasi umum yang didukung Sensitive Data Protection adalah pengelompokan. Dengan pengelompokan, Anda mengelompokkan data ke dalam kelompok yang lebih kecil dalam upaya meminimalkan risiko penyerang mengaitkan informasi sensitif dengan informasi identitas. Tindakan ini dapat mempertahankan makna dan kegunaan, tetapi juga akan menyamarkan nilai individual yang memiliki terlalu sedikit peserta.
Skenario pengelompokan 1
Pertimbangkan skenario pengelompokan numerik ini: Database menyimpan skor kepuasan pengguna, yang berkisar dari 0 hingga 100. Database akan terlihat seperti berikut:
| user_id | skor |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | ... |
Setelah memindai data, Anda menyadari bahwa beberapa nilai jarang digunakan oleh pengguna. Bahkan, ada beberapa skor yang hanya dipetakan ke satu pengguna. Misalnya, sebagian besar pengguna memilih 0, 25, 50, 75, atau 100. Namun, lima pengguna memilih 95, dan hanya satu pengguna yang memilih 92. Daripada menyimpan data mentah, Anda dapat menggeneralisasi nilai ini ke dalam grup dan menghilangkan grup yang memiliki terlalu sedikit peserta. Bergantung pada cara data digunakan, menggeneralisasi data dengan cara ini dapat membantu mencegah identifikasi ulang.
Anda dapat memilih untuk menghapus baris data pencilan ini, atau Anda dapat mencoba mempertahankan kegunaannya dengan menggunakan pengelompokan. Untuk contoh ini, mari kelompokkan semua nilai menurut hal berikut:
- 0 hingga 25: "Rendah"
- 26-75: "Sedang"
- 76-100: "Tinggi"
Pengelompokan dalam Perlindungan Data Sensitif adalah salah satu dari banyak transformasi
dasar yang tersedia untuk de-identifikasi. Konfigurasi JSON
berikut menunjukkan cara menerapkan skenario pengelompokan ini di
DLP API. JSON ini dapat disertakan dalam permintaan ke metode
content.deidentify:
C#
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Go
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Java
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Node.js
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
PHP
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk mempelajari cara menginstal dan menggunakan library klien untuk Sensitive Data Protection, lihat library klien Sensitive Data Protection.
Untuk melakukan autentikasi ke Sensitive Data Protection, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
Skenario pengelompokan 2
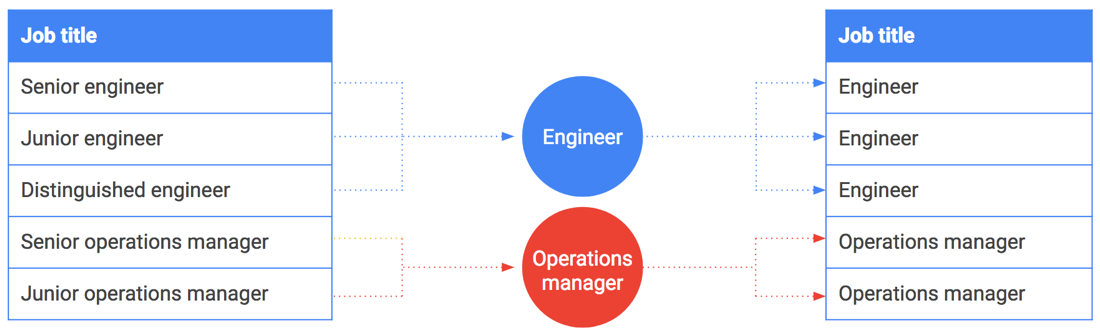
Pengelompokan juga dapat digunakan pada string atau nilai terhitung. Misalnya, Anda ingin membagikan data gaji dan menyertakan jabatan. Namun, beberapa jabatan, seperti CEO atau engineer terkemuka, dapat dikaitkan dengan satu orang atau sekelompok kecil orang. Judul pekerjaan tersebut dapat dengan mudah dicocokkan dengan karyawan yang memegangnya.
Pengelompokan juga dapat membantu di sini. Daripada menyertakan jabatan yang persis sama, kelompokkan dan buat jabatan tersebut menjadi lebih umum. Misalnya, "Senior Engineer", "Junior Engineer", dan "Distinguished Engineer" menjadi umum dan dikelompokkan hanya menjadi "Engineer". Tabel berikut menggambarkan pengelompokan judul pekerjaan tertentu ke dalam kelompok judul pekerjaan.
Skenario lainnya
Dalam contoh ini, kita telah menerapkan transformasi pada data terstruktur. Pengelompokan juga dapat digunakan pada contoh tidak terstruktur, selama nilainya dapat diklasifikasikan dengan infoType standar atau kustom. Berikut beberapa contoh skenario:
- Mengklasifikasikan tanggal dan mengelompokkannya ke dalam rentang tahun
- Mengklasifikasikan nama dan mengelompokkannya ke dalam grup berdasarkan huruf pertama (A-M, N-Z)
Resource
Untuk mempelajari lebih lanjut generalisasi dan pengelompokan, lihat Melakukan De-identifikasi Data Sensitif dalam Konten Teks.
Untuk dokumentasi API, lihat:
- Metode
projects.content.deidentify BucketingConfigtransformasi: Mengelompokkan nilai berdasarkan rentang kustom.FixedSizeBucketingConfigtransformasi: Mengelompokkan nilai berdasarkan rentang ukuran tetap.