K-anonymity è una proprietà di un set di dati che indica la reidentificabilità dei suoi record. Un set di dati è k-anonymous se i quasi-identificatori per ogni persona nel set di dati sono identici ad almeno k – 1 altre persone nel set di dati.
Puoi calcolare il valore di k-anonymity in base a una o più colonne o campi di un set di dati. Questo argomento mostra come calcolare i valori di k-anonimato per un set di dati utilizzando Sensitive Data Protection. Per saperne di più su k-anonimità o sull'analisi del rischio in generale, consulta l'argomento Concetto di analisi del rischio prima di continuare.
Prima di iniziare
Prima di continuare, assicurati di aver fatto quanto segue:
- Accedi al tuo Account Google.
- Nella console Google Cloud , nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud . Vai al selettore dei progetti
- Verifica che la fatturazione sia attivata per il tuo progetto Google Cloud . Scopri come verificare che la fatturazione sia attivata per il tuo progetto.
- Abilita Sensitive Data Protection. Abilita Sensitive Data Protection
- Seleziona un set di dati BigQuery da analizzare. Sensitive Data Protection calcola la metrica di k-anonimato eseguendo la scansione di una tabella BigQuery.
- Determina un identificatore (se applicabile) e almeno un quasi-identificatore nel set di dati. Per maggiori informazioni, consulta Termini e tecniche di analisi del rischio.
Calcola k-anonymity
Sensitive Data Protection esegue l'analisi del rischio ogni volta che viene eseguito un job di analisi del rischio. Devi prima creare il job utilizzando la consoleGoogle Cloud , inviando una richiesta API DLP o utilizzando una libreria client Sensitive Data Protection.
Console
Nella console Google Cloud , vai alla pagina Crea analisi del rischio.
Nella sezione Scegli dati di input, specifica la tabella BigQuery da analizzare inserendo l'ID progetto del progetto contenente la tabella, l'ID set di dati della tabella e il nome della tabella.
Nella sezione Metrica di privacy da calcolare, seleziona k-anonimato.
Nella sezione ID job, puoi facoltativamente assegnare al job un identificatore personalizzato e selezionare una località della risorsa in cui Sensitive Data Protection elaborerà i tuoi dati. Quando hai finito, fai clic su Continua.
Nella sezione Definisci campi, specifica identificatori e quasi-identificatori per il job di rischio di k-anonimato. Sensitive Data Protection accede ai metadati della tabella BigQuery specificata nel passaggio precedente e tenta di compilare l'elenco dei campi.
- Seleziona la casella di controllo appropriata per specificare un campo come identificatore (ID) o quasi-identificatore (QI). Devi selezionare 0 o 1 identificatore e almeno 1 quasi-identificatore.
- Se Sensitive Data Protection non è in grado di compilare i campi, fai clic su Inserisci nome campo per inserire manualmente uno o più campi e impostare ciascuno come identificatore o quasi-identificatore. Al termine, fai clic su Continua.
Nella sezione Aggiungi azioni, puoi aggiungere azioni facoltative da eseguire al termine del job di rischio. Le opzioni disponibili sono:
- Salva in BigQuery: salva i risultati della scansione di analisi del rischio in una tabella BigQuery.
Pubblica in Pub/Sub: pubblica una notifica in un argomento Pub/Sub.
Notifica via email: ti invia un'email con i risultati. Al termine, fai clic su Crea.
Il job di analisi del rischio di k-anonimizzazione viene avviato immediatamente.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
REST
Per eseguire un nuovo job di analisi del rischio per calcolare l'anonimizzazione k, invia una richiesta alla risorsa
projects.dlpJobs, dove PROJECT_ID indica l'identificatore del progetto:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
La richiesta contiene un oggetto
RiskAnalysisJobConfig
composto da quanto segue:
Un oggetto
PrivacyMetric. Qui specifichi che stai calcolando la k-anonymity includendo un oggettoKAnonymityConfig.Un oggetto
BigQueryTable. Specifica la tabella BigQuery da analizzare includendo tutti i seguenti elementi:projectId: l'ID progetto del progetto contenente la tabella.datasetId: l'ID set di dati della tabella.tableId: il nome della tabella.
Un insieme di uno o più oggetti
Actionche rappresentano le azioni da eseguire, nell'ordine indicato, al termine del job. Ogni oggettoActionpuò contenere una delle seguenti azioni:SaveFindingsobject: salva i risultati della scansione di analisi del rischio in una tabella BigQuery.PublishToPubSuboggetto: Pubblica una notifica in un argomento Pub/Sub.JobNotificationEmailsobject: Ti invia un'email con i risultati.
All'interno dell'oggetto
KAnonymityConfig, specifica quanto segue:quasiIds[]: uno o più quasi-identificatori (oggettiFieldId) da scansionare e utilizzare per calcolare l'anonimato k. Quando specifichi più quasi-identificatori, vengono considerati una singola chiave composita. I tipi di dati struct e ripetuti non sono supportati, ma i campi nidificati sono supportati a condizione che non siano struct stessi o nidificati all'interno di un campo ripetuto.entityId: valore identificatore facoltativo che, se impostato, indica che tutte le righe corrispondenti a ognientityIddistinto devono essere raggruppate per il calcolo dell'k-anonimato. In genere, unentityIdè una colonna che rappresenta un utente unico, ad esempio un ID cliente o un ID utente. Quando unentityIdviene visualizzato in più righe con valori di quasi-identificatore diversi, queste righe vengono unite per formare un multiset che verrà utilizzato come quasi-identificatori per l'entità. Per saperne di più sugli ID entità, consulta ID entità e calcolo di k-anonimato nell'argomento concettuale Analisi del rischio.
Non appena invii una richiesta all'API DLP, viene avviato il job di analisi del rischio.
Elenca i job di analisi del rischio completati
Puoi visualizzare un elenco dei job di analisi del rischio eseguiti nel progetto attuale.
Console
Per elencare i job di analisi del rischio in esecuzione e quelli eseguiti in precedenza nella consoleGoogle Cloud :
Nella console Google Cloud , apri Sensitive Data Protection.
Fai clic sulla scheda Job e trigger dei job nella parte superiore della pagina.
Fai clic sulla scheda Lavori a rischio.
Viene visualizzata l'offerta di lavoro a rischio.
Protocollo
Per elencare i job di analisi del rischio in esecuzione e quelli eseguiti in precedenza, invia una richiesta GET alla risorsa
projects.dlpJobs. L'aggiunta di un filtro per il tipo di job (?type=RISK_ANALYSIS_JOB) restringe la
risposta ai soli job di analisi del rischio.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
La risposta che ricevi contiene una rappresentazione JSON di tutti i job di analisi del rischio attuali e precedenti.
Visualizzare i risultati del job k-anonymity
Sensitive Data Protection nella console Google Cloud offre visualizzazioni integrate per i job di k-anonymity completati. Dopo aver seguito le istruzioni nella sezione precedente, seleziona il job per cui vuoi visualizzare i risultati dall'elenco dei job di analisi del rischio. Supponendo che il job sia stato eseguito correttamente, la parte superiore della pagina Dettagli analisi del rischio ha il seguente aspetto:
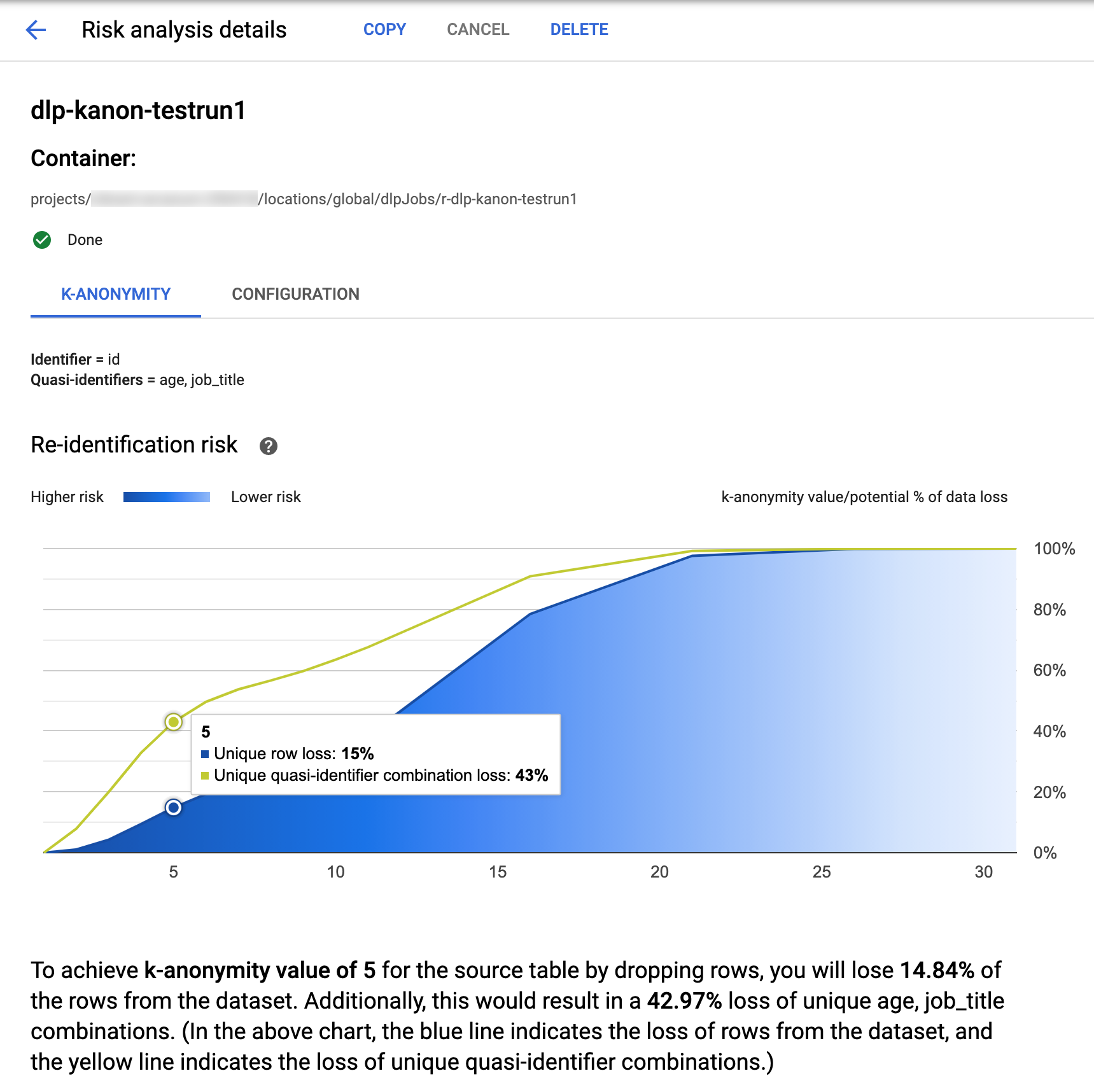
Nella parte superiore della pagina sono riportate le informazioni sul job di rischio di k-anonimità, inclusi l'ID job e, nella sezione Contenitore, la posizione della risorsa.
Per visualizzare i risultati del calcolo di k-anonymity, fai clic sulla scheda k-anonymity. Per visualizzare la configurazione del job di analisi del rischio, fai clic sulla scheda Configurazione.
La scheda K-anonymity elenca innanzitutto l'ID entità (se presente) e i quasi-identificatori utilizzati per calcolare la k-anonymity.
Grafico dei rischi
Il grafico Rischio di reidentificazione traccia, sull'asse y, la potenziale percentuale di perdita di dati sia per le righe univoche sia per le combinazioni univoche di quasi-identificatori per ottenere, sull'asse x, un valore di anonimizzazione k. Il colore del grafico indica anche il potenziale di rischio. Le tonalità di blu più scure indicano un rischio maggiore, mentre quelle più chiare indicano un rischio minore.
Valori di k-anonymity più elevati indicano un rischio di reidentificazione inferiore. Per ottenere valori di k-anonimizzazione più elevati, tuttavia, dovresti rimuovere percentuali più elevate del totale delle righe e combinazioni di quasi-identificatori univoci più elevate, il che potrebbe ridurre l'utilità dei dati. Per visualizzare un valore percentuale potenziale specifico per un determinato valore di k-anonymity, passa il cursore sopra il grafico. Come mostrato nello screenshot, nel grafico viene visualizzata una descrizione comando.
Per visualizzare maggiori dettagli su un valore di k-anonymity specifico, fai clic sul punto dati corrispondente. Sotto il grafico viene mostrata una spiegazione dettagliata e più in basso nella pagina viene visualizzata una tabella di dati di esempio.
Tabella dei dati di esempio sul rischio
Il secondo componente della pagina dei risultati del job di analisi del rischio è la tabella dei dati di esempio. Mostra le combinazioni di quasi-identificatori per un determinato valore di k-anonymity di destinazione.
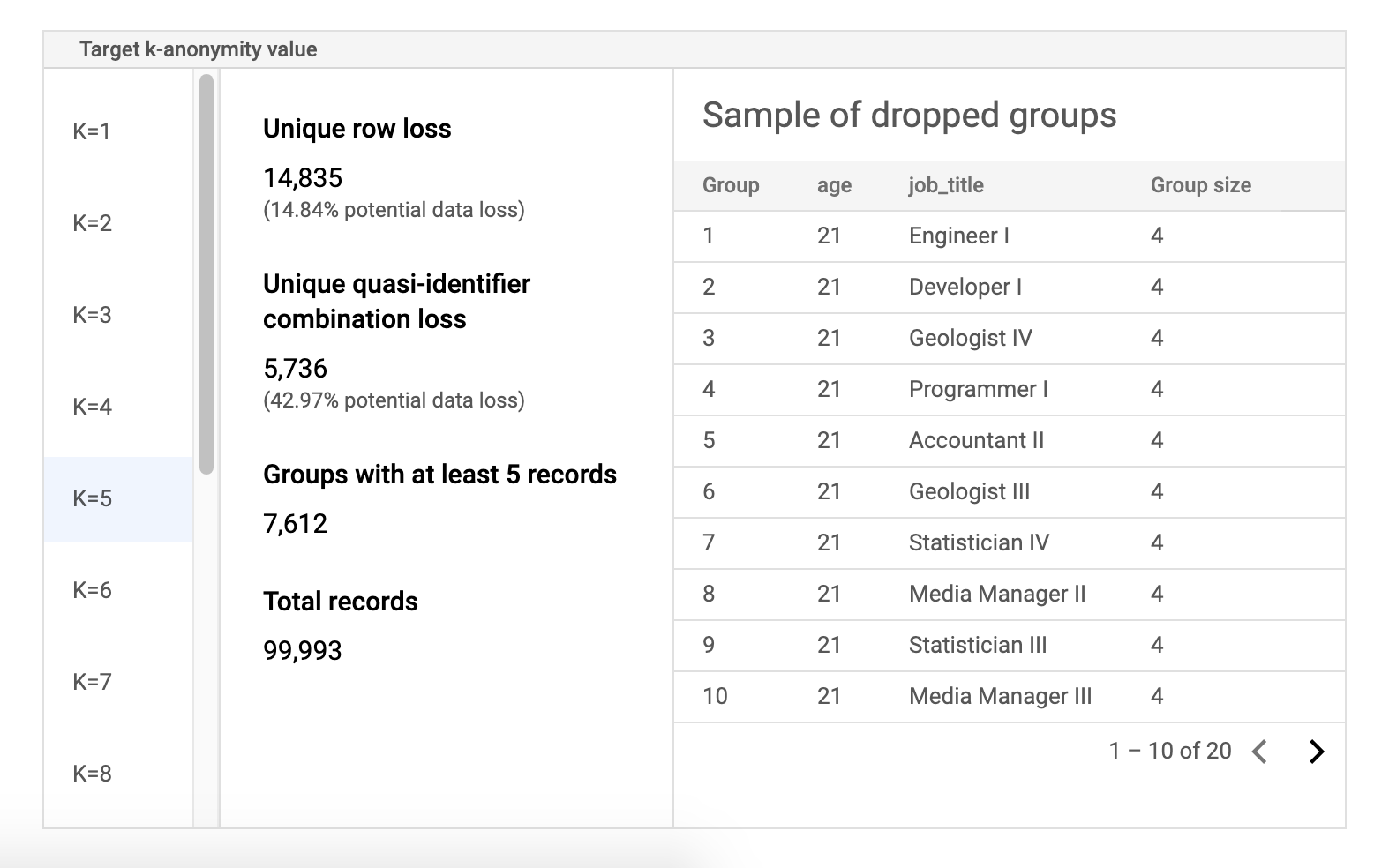
La prima colonna della tabella elenca i valori di k-anonimato. Fai clic su un valore di k-anonymity per visualizzare i dati di esempio corrispondenti che dovrebbero essere eliminati per raggiungere quel valore.
La seconda colonna mostra la potenziale perdita di dati rispettiva di righe univoche e combinazioni di quasi-identificatori, nonché il numero di gruppi con almeno k record e il numero totale di record.
L'ultima colonna mostra un campione di gruppi che condividono una combinazione di quasi-identificatori, insieme al numero di record esistenti per quella combinazione.
Recuperare i dettagli del job utilizzando REST
Per recuperare i risultati del job di analisi del rischio di anonimizzazione k utilizzando l'API REST, invia la seguente richiesta GET alla risorsa projects.dlpJobs. Sostituisci PROJECT_ID con l'ID progetto e
JOB_ID con l'identificatore del job per cui vuoi ottenere i risultati.
L'ID job è stato restituito all'avvio del job e può essere recuperato anche
elencando tutti i job.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
La richiesta restituisce un oggetto JSON contenente un'istanza del job. I risultati
dell'analisi si trovano all'interno della chiave "riskDetails", in un
oggetto
AnalyzeDataSourceRiskDetails. Per saperne di più, consulta il riferimento API per la risorsa
DlpJob.
Esempio di codice: calcolo di k-anonymity con un ID entità
Questo esempio crea un job di analisi del rischio che calcola la k-anonimità con un ID entità.
Per saperne di più sugli ID entità, consulta ID entità e calcolo k-anonimato.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta la sezione Librerie client Sensitive Data Protection.
Per eseguire l'autenticazione in Sensitive Data Protection, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Passaggi successivi
- Scopri come calcolare il valore di l-diversity per un set di dati.
- Scopri come calcolare il valore di k-map per un set di dati.
- Scopri come calcolare il valore di δ-presence per un set di dati.