Auf dieser Seite finden Sie empfohlene Strategien zum Identifizieren und Beheben von Datenrisiken in Ihrer Organisation.
Der Schutz Ihrer Daten beginnt damit, dass Sie wissen, welche Daten Sie verarbeiten, wo sich sensible Daten befinden und wie diese Daten geschützt und verwendet werden. Wenn Sie einen umfassenden Überblick über Ihre Daten und deren Sicherheitsstatus haben, können Sie die entsprechenden Maßnahmen ergreifen, um sie zu schützen und kontinuierlich auf Compliance und Risiken zu überwachen.
Auf dieser Seite wird davon ausgegangen, dass Sie mit den Discovery- und Inspektionsdiensten und ihren Unterschieden vertraut sind.
Erkennung sensibler Daten aktivieren
Wenn Sie ermitteln möchten, wo sich sensible Daten in Ihrem Unternehmen befinden, konfigurieren Sie die Erkennung auf Organisations-, Ordner- oder Projektebene. Mit diesem Dienst werden Datenprofile mit Messwerten und Statistiken zu Ihren Daten generiert, einschließlich ihrer Vertraulichkeits- und Datenrisikostufen.
Als Dienst fungiert Discovery als Single Source of Truth für Ihre Daten-Assets und kann automatisch Messwerte für Prüfberichte generieren. Außerdem kann Discovery eine Verbindung zu anderen Google Cloud Diensten wie Security Command Center, Google Security Operations und Dataplex Universal Catalog herstellen, um Sicherheitsvorgänge und Datenverwaltung zu optimieren.
Der Erkennungsdienst wird kontinuierlich ausgeführt und erkennt neue Daten, wenn Ihr Unternehmen wächst. Wenn beispielsweise jemand in Ihrer Organisation ein neues Projekt erstellt und eine große Menge neuer Daten hochlädt, kann der Discovery-Dienst die neuen Daten automatisch erkennen, klassifizieren und Berichte dazu erstellen.
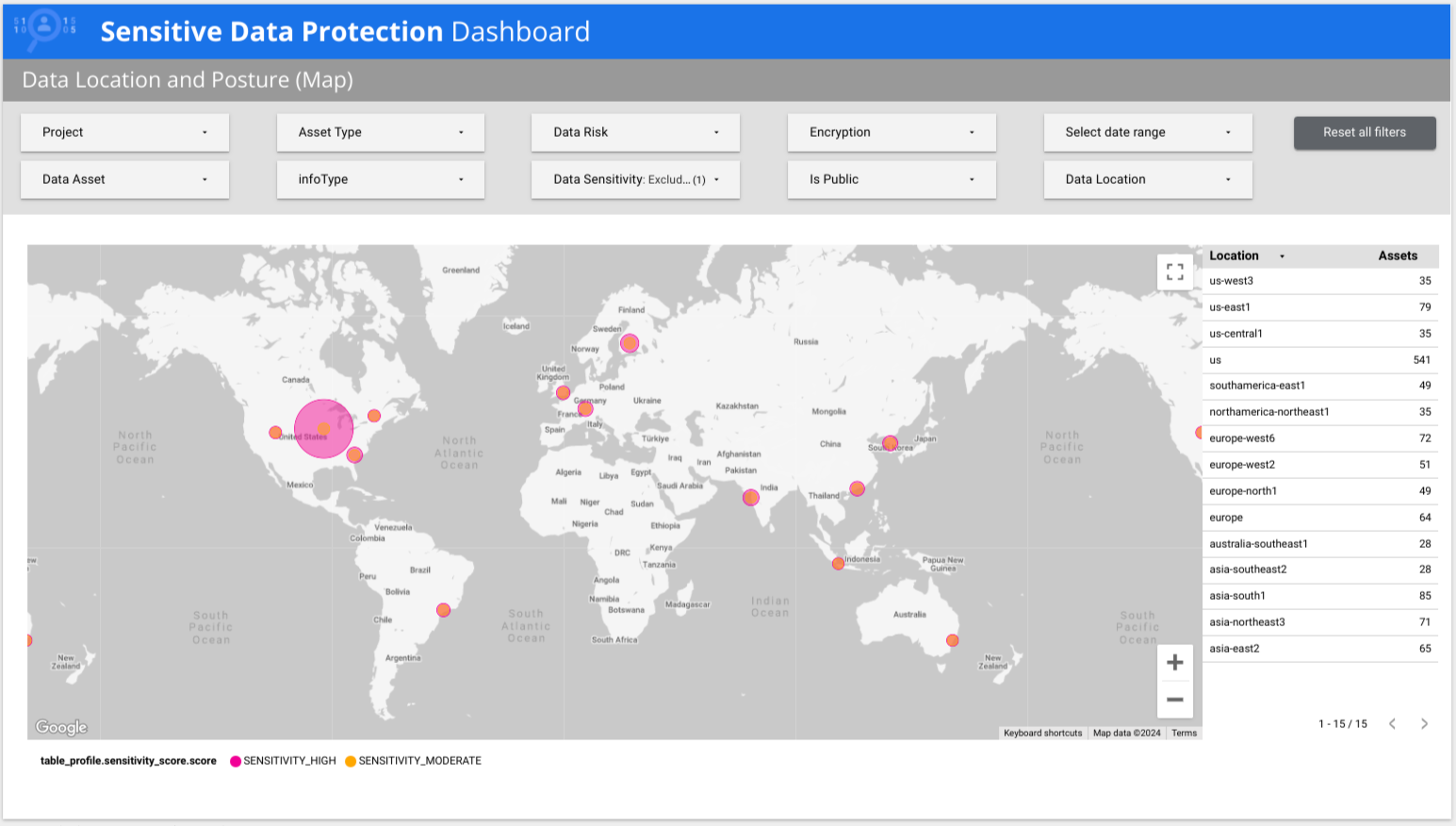
Sensitive Data Protection bietet einen vorgefertigten mehrseitigen Looker-Bericht, der Ihnen einen allgemeinen Überblick über Ihre Daten gibt, einschließlich Aufschlüsselungen nach Risiko, infoType und Standort. Im folgenden Beispiel ist zu sehen, dass Daten mit niedriger und hoher Sensibilität in mehreren Ländern weltweit vorhanden sind.
Auf Grundlage der Ergebnisse der Erkennung Maßnahmen ergreifen
Nachdem Sie sich einen Überblick über Ihre Datensicherheit verschafft haben, können Sie alle gefundenen Probleme beheben. Im Allgemeinen fallen Discovery-Ergebnisse in eines der folgenden Szenarien:
- Szenario 1: In einem Arbeitslast wurde eine sensible Datei gefunden, in der sie erwartet wird und die ordnungsgemäß geschützt ist.
- Szenario 2: In einer Arbeitslast wurden vertrauliche Daten gefunden, in der sie nicht erwartet wurden oder für die keine geeigneten Kontrollen vorhanden sind.
- Szenario 3: Es wurden vertrauliche Daten gefunden, die jedoch noch genauer untersucht werden müssen.
Szenario 1: Es wurden sensible Daten gefunden und sie sind ordnungsgemäß geschützt.
In diesem Fall ist keine bestimmte Aktion erforderlich. Sie sollten die Datenprofile jedoch in Ihre Prüfberichte und Sicherheitsanalyse-Workflows aufnehmen und weiterhin nach Änderungen suchen, die Ihre Daten gefährden könnten.
Wir empfehlen Folgendes:
Veröffentlichen Sie die Datenprofile in Tools, mit denen Sie Ihr Sicherheitsverhalten überwachen und Cyberbedrohungen untersuchen können. Mithilfe von Datenprofilen können Sie den Schweregrad einer Sicherheitsbedrohung oder ‑lücke ermitteln, die Ihre vertraulichen Daten gefährden könnte. Sie können Datenprofile automatisch in die folgenden Produkte exportieren:
Veröffentlichen Sie die Datenprofile in Dataplex Universal Catalog oder einem Inventarsystem, um die Messwerte für Datenprofile zusammen mit anderen relevanten Geschäftsmetadaten zu erfassen. Informationen zum automatischen Exportieren von Datenprofilen in Dataplex Universal Catalog finden Sie unter Dataplex Universal Catalog-Aspekte basierend auf Statistiken aus Datenprofilen hinzufügen.
Szenario 2: Es wurden sensible Daten gefunden, die nicht richtig geschützt sind
Wenn bei der Ermittlung sensible Daten in einer Ressource gefunden werden, die nicht durch Zugriffssteuerungen geschützt sind, sollten Sie die Empfehlungen in diesem Abschnitt berücksichtigen.
Nachdem Sie die richtigen Kontrollen und den richtigen Datensicherheitsstatus für Ihre Daten eingerichtet haben, sollten Sie auf Änderungen achten, die Ihre Daten gefährden könnten. Empfehlungen für Szenario 1
Allgemeine Empfehlungen
Sie können Folgendes tun:
Erstellen Sie eine anonymisierte Kopie Ihrer Daten, um die vertraulichen Spalten zu maskieren oder zu tokenisieren. So können Ihre Datenanalysten und ‑entwickler weiterhin mit Ihren Daten arbeiten, ohne Rohdaten und vertrauliche Kennungen wie personenidentifizierbare Informationen preiszugeben.
Für Cloud Storage-Daten können Sie eine integrierte Funktion in Sensitive Data Protection verwenden, um anonymisierte Kopien zu erstellen.
Wenn Sie die Daten nicht benötigen, sollten Sie sie löschen.
Empfehlungen zum Schutz von BigQuery-Daten
- Berechtigungen auf Tabellenebene mit IAM anpassen
Detaillierte Zugriffssteuerungen auf Spaltenebene mit BigQuery-Richtlinien-Tags festlegen, um den Zugriff auf vertrauliche und risikoreiche Spalten einzuschränken. Mit dieser Funktion können Sie diese Spalten schützen und gleichzeitig den Zugriff auf den Rest der Tabelle zulassen.
Sie können auch Richtlinien-Tags verwenden, um die automatische Datenmaskierung zu aktivieren. Dadurch erhalten Nutzer teilweise verschleierte Daten.
Mit der Sicherheit auf Zeilenebene von BigQuery können Sie bestimmte Datenzeilen ausblenden oder anzeigen, je nachdem, ob ein Nutzer oder eine Gruppe in einer Zulassungsliste enthalten ist.
BigQuery-Daten zum Zeitpunkt der Abfrage mit Remote-Funktionen (UDF) de-identifizieren
Empfehlungen zum Schutz von Cloud Storage-Daten
Szenario 3: Es wurden sensible Daten gefunden, die jedoch noch genauer untersucht werden müssen
In einigen Fällen erhalten Sie möglicherweise Ergebnisse, die weitere Untersuchungen erfordern. In einem Datenprofil kann beispielsweise angegeben werden, dass eine Spalte einen hohen Wert für freien Text mit Hinweisen auf vertrauliche Daten hat. Ein hoher Wert für freien Text deutet darauf hin, dass die Daten keine vorhersehbare Struktur haben und möglicherweise zeitweise sensible Daten enthalten. Das kann beispielsweise eine Spalte mit Notizen sein, in der bestimmte Zeilen personenbezogene Daten wie Namen, Kontaktdaten oder von der Regierung ausgestellte Kennungen enthalten. In diesem Fall empfehlen wir, zusätzliche Zugriffssteuerungen für die Tabelle festzulegen und andere Maßnahmen zu ergreifen, die in Szenario 2 beschrieben sind. Außerdem empfehlen wir, eine detailliertere, gezielte Prüfung durchzuführen, um das Ausmaß des Risikos zu ermitteln.
Mit dem Prüfdienst können Sie eine einzelne Ressource, z. B. eine einzelne BigQuery-Tabelle oder einen Cloud Storage-Bucket, gründlich scannen. Bei Datenquellen, die vom Prüfdienst nicht direkt unterstützt werden, können Sie die Daten in einen Cloud Storage-Bucket oder eine BigQuery-Tabelle exportieren und einen Prüfjob für diese Ressource ausführen. Wenn Sie beispielsweise Daten haben, die Sie in einer Cloud SQL-Datenbank prüfen müssen, können Sie diese Daten in eine CSV- oder AVRO-Datei in Cloud Storage exportieren und einen Prüfjob ausführen.
Bei einem Inspektionsjob werden einzelne Instanzen sensibler Daten gefunden, z. B. eine Kreditkartennummer in der Mitte eines Satzes in einer Tabellenzelle. Mit diesem Detaillierungsgrad können Sie nachvollziehen, welche Art von Daten in unstrukturierten Spalten oder in Datenobjekten wie Textdateien, PDFs, Bildern und anderen Rich-Dokumentformaten vorhanden ist. Anschließend können Sie die Probleme mithilfe der Empfehlungen in Szenario 2 beheben.
Zusätzlich zu den in Szenario 2 empfohlenen Maßnahmen sollten Sie auch Maßnahmen ergreifen, um zu verhindern, dass vertrauliche Informationen in Ihren Backend-Datenspeicher gelangen.
Die content-Methoden der Cloud Data Loss Prevention API können Daten aus jeder Arbeitslast oder Anwendung für die Prüfung und Maskierung von Daten während der Übertragung akzeptieren. Ihre Anwendung kann beispielsweise Folgendes tun:
- Einen vom Nutzer bereitgestellten Kommentar akzeptieren
- Führen Sie
content.deidentifyaus, um alle sensiblen Daten aus diesem String zu de-identifizieren. - Speichern Sie die anonymisierte Zeichenfolge in Ihrem Backend-Speicher anstelle der ursprünglichen Zeichenfolge.
Zusammenfassung der Best Practices
In der folgenden Tabelle sind die Best Practices zusammengefasst, die in diesem Dokument empfohlen werden:
| Herausforderung | Aktion |
|---|---|
| Sie möchten wissen, welche Art von Daten Ihre Organisation speichert. | Führen Sie die Ermittlung auf Organisations-, Ordner- oder Projektebene aus. |
| Sie haben sensible Daten in einer Ressource gefunden, die bereits geschützt ist. | Ressourcen kontinuierlich überwachen, indem Sie die Erkennung ausführen und Profile automatisch in Security Command Center, Google SecOps und Dataplex Universal Catalog exportieren. |
| Sie haben sensible Daten in einer Ressource gefunden, die nicht geschützt ist. | Daten je nach Betrachter ausblenden oder einblenden – mit IAM, Sicherheit auf Spaltenebene oder Sicherheit auf Zeilenebene. Sie können auch die Tools zur De-Identifikation von Sensitive Data Protection verwenden, um die sensiblen Elemente zu transformieren oder zu entfernen. |
| Sie haben sensible Daten gefunden und müssen weitere Untersuchungen anstellen, um das Ausmaß des Datenrisikos zu ermitteln. | Führen Sie einen Inspektionsjob für die Ressource aus. Sie können auch proaktiv verhindern, dass sensible Daten in Ihren Backend-Speicher gelangen. Verwenden Sie dazu die synchronen content-Methoden der DLP API, mit denen Daten nahezu in Echtzeit verarbeitet werden. |