BigQuery への推奨事項のエクスポート
概要
BigQuery へのエクスポートでは、組織に対する推奨事項の日次スナップショットを表示できます。これは、BigQuery Data Transfer Service を使用して行います。現在 BigQuery Export に含まれている Recommender を確認するには、こちらのドキュメントをご覧ください。
始める前に
推奨事項用のデータ転送を作成する前に、次の手順を実施します。
- データ転送を管理するために BigQuery Data Transfer Service 権限を付与します。BigQuery ウェブ UI を使用して転送を作成する場合は、ブラウザで
console.cloud.google.comからのポップアップを許可して権限を表示できるようにする必要があります。詳細については、BigQuery Data Transfer Service の有効化をご覧ください。 - データを保存する BigQuery データセットを作成します。
- データ転送では、データセットを作成するリージョンと同じリージョンが使用されます。データセットと転送が作成された後は、このロケーションは変更できません。
- データセットには、世界中のあらゆるリージョンからの分析情報と推奨事項が含まれます。したがって、このオペレーションでは、処理中にそれらすべてのデータをグローバル リージョンに集約することになります。データ レジデンシーに関する懸念がある場合は、Google Cloud カスタマーケアをご覧ください。
- データセットのロケーションが新しく開始された場合、最初のエクスポート データが利用可能になるまでに時間がかかることがあります。
料金
BigQuery への推奨事項のエクスポートは、Recommender をご利用のすべてのお客様が Recommender の料金階層に基づいて行うことができます。
必要な権限
データ転送を設定する際は、データ転送を作成するプロジェクト レベルで次の権限が必要です。
bigquery.transfers.update- 転送を作成できます。bigquery.datasets.update- ターゲット データセットに対するアクションを更新できます。resourcemanager.projects.update- エクスポート データを保存するプロジェクトを選択できますpubsub.topics.list- エクスポートに関する通知を受け取るために Pub/Sub トピックを選択できます。
組織レベルで次の権限が必要です。この組織は、エクスポートが設定されている組織に対応しています。
recommender.resources.export- 推奨事項を BigQuery にエクスポートできます。
費用削減の推奨事項で交渉価格をエクスポートするには、次の権限が必要です。
billing.resourceCosts.get at project level- プロジェクト レベルの推奨事項で交渉価格をエクスポートできます。billing.accounts.getSpendingInformation at billing account level- 請求先アカウント レベルの推奨事項で交渉価格をエクスポートできます。
これらの権限がない場合、費用削減の推奨事項は交渉価格ではなく標準価格でエクスポートされます。
権限を付与する
次のロールは、データ転送を作成するプロジェクトに付与する必要があります。
- BigQuery 管理者ロール -
roles/bigquery.admin - プロジェクト オーナーロール -
roles/owner - プロジェクト オーナーロール -
roles/owner - プロジェクト閲覧者ロール -
roles/viewer - プロジェクト編集者ロール -
roles/editor - 請求先アカウント管理者ロール -
roles/billing.admin - 請求先アカウント費用管理者ロール -
roles/billing.costsManager - 請求先アカウント閲覧者ロール -
roles/billing.viewer
ターゲット データセットに対して転送と更新のアクションを作成するには、次のロールを付与する必要があります。
エクスポート データの保存と、通知を受け取る Pub/Sub トピックの選択のためのプロジェクトを選択する権限を含むロールは複数あります。これらの権限をどちらも使用できるようにするには、次のロールを付与します。
費用削減のプロジェクト レベルの推奨事項で交渉価格をエクスポートするには、billing.resourceCosts.get 権限を含むロールが複数あり、次のいずれかを付与できます。
費用削減の請求先アカウント レベルの推奨事項で交渉価格をエクスポートするには、billing.accounts.getSpendingInformation 権限を含むロールが複数あり、次のいずれかを付与できます。
組織レベルで次のロールを付与する必要があります。
- Google Cloud コンソールでの推奨事項エクスポータ(
roles/recommender.exporter)ロール。
推奨事項用のデータ転送を作成する
Google Cloud コンソールにログインします。
ホーム画面で、[推奨事項] タブをクリックします。
[エクスポート] をクリックして BigQuery エクスポート フォームを表示します。
推奨事項データを保存する宛先プロジェクトを選択し、[次へ] をクリックします。
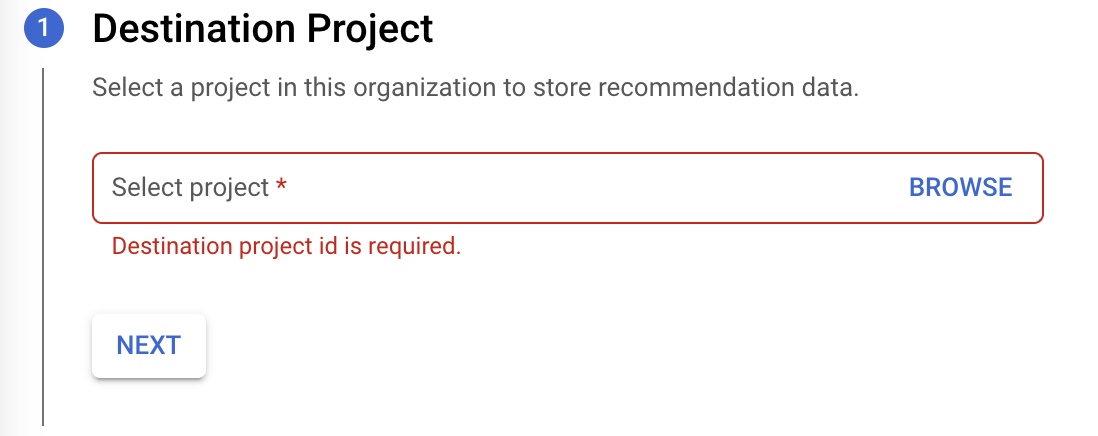
[API を有効にする] をクリックして、エクスポート用の BigQuery API を有効にします。完了には、数秒かかることがあります。設定が完了したら、[続行] をクリックします。
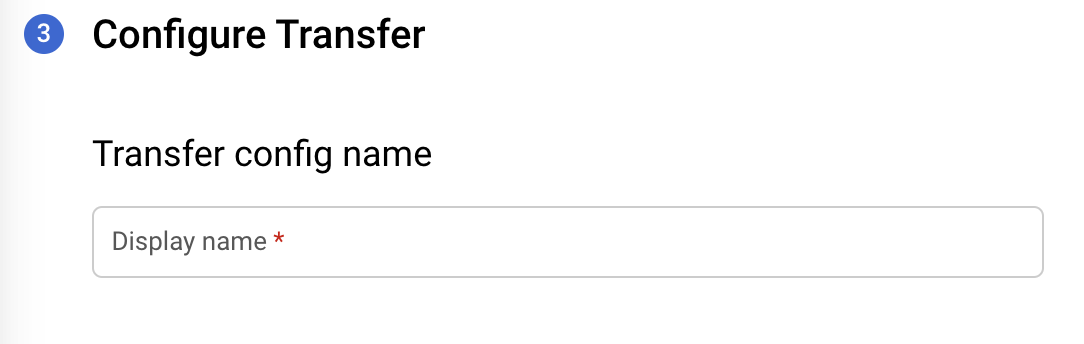
[Configure Transfer] フォームに以下の詳細情報を入力します。
[転送構成名] セクションの [表示名] に、転送名を入力します。転送名には、後で修正が必要になった場合に簡単に識別できる任意の名前を使用できます。
[スケジュール オプション] セクションで、スケジュールはデフォルト値([すぐに開始可能])のままにするか、[設定した時間に開始] をクリックします。
[繰り返しの頻度] で、転送を実行する頻度のオプションを選択します。
- 毎日(デフォルト)
- 毎週
- 毎月
- カスタム
- オンデマンド
[開始日と実行時間] に、転送を開始する日付と時刻を入力します。[すぐに開始可能] を選択した場合、このオプションは無効になります。
![コンソールのフォーム。データ転送の [スケジュール] オプションが表示されています。現在の選択は午前 9 時 30 分(アジア/カルカッタ時間)に設定されています。](https://cloud-dot-devsite-v2-prod.appspot.com/static/recommender/docs/images/transfer-schedule.png?hl=ja)
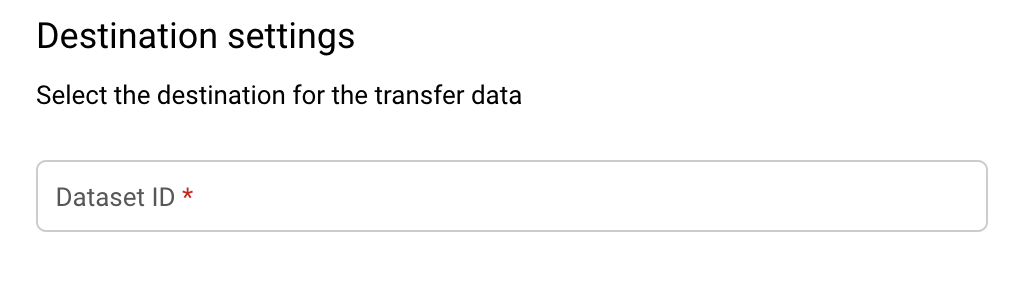
[転送先の設定] セクションで、宛先データセットには、データを保存するために作成した [データセット ID] を選択します。
[データソースの詳細] セクションで、次の操作を行います。
organization_id のデフォルト値は、現在推奨事項を表示している組織です。推奨事項を別の組織にエクスポートする場合は、組織ビューアのコンソールの上部で変更できます。

(省略可)[通知オプション] セクションで、次の操作を行います。
- 切り替えボタンをクリックしてメール通知を有効にします。このオプションを有効にすると、転送の実行が失敗した場合、転送管理者にメール通知が送信されます。
- [Pub/Sub トピックを選択してください] で、トピック名を選択するか、[トピックを作成する] をクリックします。このオプションで、Pub/Sub の転送実行通知を構成します。
![コンソールの [通知オプション] を設定するフォーム。メール通知を有効にする切り替えボタンと、Pub/Sub トピックを選択するプルダウン メニューが表示されています。](https://cloud-dot-devsite-v2-prod.appspot.com/static/recommender/docs/images/transfer-notifications.png?hl=ja)
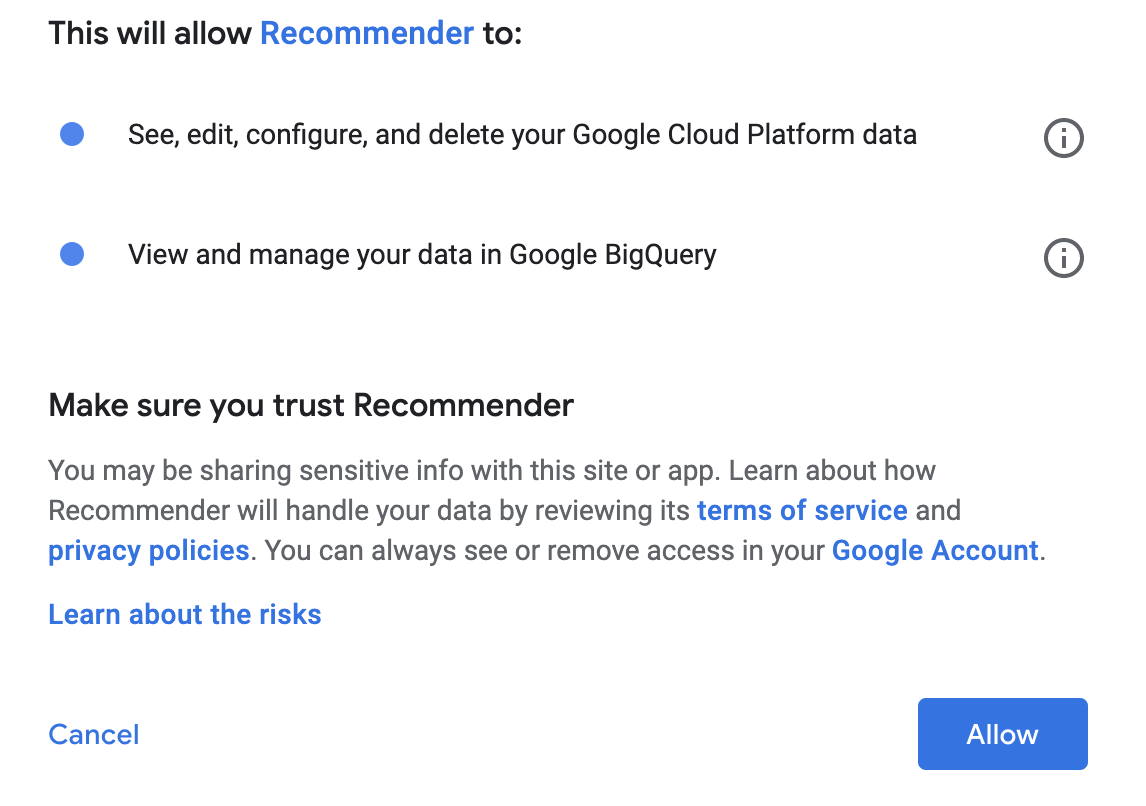
[作成] をクリックして転送を作成します。
同意のポップアップで [Allow] をクリックします。
転送が作成されると、Active Assist にリダイレクトされます。リンクをクリックして転送構成の詳細を表示できます。また、次の手順でも転送にアクセスできます。
Google Cloud コンソールの [BigQuery] ページに移動します。
[データ転送] をクリックします。利用可能なすべてのデータ転送を表示できます。
転送の実行履歴を表示する
転送の実行履歴を表示するには、次の手順に沿って操作します。
Google Cloud コンソールの [BigQuery] ページに移動します。
[データ転送] をクリックします。利用可能なすべてのデータ転送を表示できます。
リスト内の該当する転送をクリックします。
[実行履歴] タブに表示されている転送実行のリストで、詳細を表示する転送を選択します。
選択した個別の転送実行に対する [実行の詳細] パネルが表示されます。実行の詳細に表示される可能性がある情報の一部を次に示します。
- ソースデータが利用できないため、転送を延期しました。
- テーブルにエクスポートされた行数を示すジョブ。
- データソースに対する権限がありません。権限を付与し、後でバックフィルをスケジュールする必要があります。
データがエクスポートされるタイミング
データ転送を作成した場合は、最初のエクスポートが行われるまで 2 日かかります。最初のエクスポート後、設定時にリクエストした頻度でエクスポート ジョブが実行されます。次の条件が適用されます。
特定の日(D)のエクスポート ジョブは、1 日の終わりのデータを BigQuery データセットにエクスポートします。このデータセットは通常、翌日の終わり(D+1)までに終了します。エクスポート ジョブは PST タイムゾーンで動作するため、他のタイムゾーンではさらに遅延が生じる可能性があります。
毎日のエクスポート ジョブは、エクスポート対象のデータすべてが利用可能になるまで実行されません。その結果、データセットが更新される日時が変動したり、場合によっては遅延が発生したりする可能性があります。そのため、特定の日付のテーブルに対して強い制約や時間的制約などを設けるのではなく、利用可能な最新のデータ スナップショットを使用することをおすすめします。
エクスポート ジョブは、リージョンごとに利用可能な最新のデータを転送します。つまり、リージョンごとに推奨事項が利用可能な最新の日付が異なる可能性があります。
書き出しに関する一般的なステータス メッセージ
BigQuery への推奨事項のエクスポートで表示される一般的なステータス メッセージについて説明します。
ユーザーに必要な権限がない
ユーザーに必要な権限 recommender.resources.export がない場合、次のメッセージが表示されます。次のメッセージが表示されます。
User does not have required permission "recommender.resources.export". Please, obtain the required permissions for the datasource and try again by triggering a backfill for this date
この問題を解決するには、エクスポートを設定した組織の組織レベルでエクスポートを設定する user/service account に IAM ロール roles/recommender.exporter を付与します。これは、以下の gcloud コマンドで指定できます。
ユーザーの場合:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='user:*<user_name>*' --role='roles/recommender.exporter'サービス アカウントの場合:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'
ソースデータを利用できないため、転送が延期された
ソースデータが利用できないために転送スケジュールが再設定されると、次のメッセージが表示されます。これはエラーではありません。その日のエクスポート パイプラインがまだ完了していないことを意味します。転送は新しくスケジュールされた時刻に再実行され、エクスポート パイプラインが完了すると正常に終了します。次のメッセージが表示されます。
Transfer deferred due to source data not being available
ソースデータが見つからない
F1toPlacer パイプラインが完了し、エクスポートが設定された組織に関する推奨事項または分析情報が見つからなかった場合は、次のメッセージが表示されます。次のメッセージが表示されます。
Source data not found for 'recommendations_export$<date>'insights_export$<date>
このメッセージは次の理由で表示されます。
- ユーザーが書き出しを設定してから 2 日以内である。カスタマー ガイドに、エクスポートが利用可能になるまでに 1 日程度時間がかかることが記載されています。
- 特定の日に関して利用できる推奨事項や分析情報はありません。実際にない場合もありますが、その日に推奨事項や分析情報が利用可能になる前にパイプラインが実行されていた可能性もあります。
転送のテーブルを表示する
BigQuery に推奨事項をエクスポートした場合、データセットには、日付でパーティション分割された 2 つのテーブルが格納されています。
- recommendations_export
- insight_export
テーブルとスキーマの詳細については、テーブルの作成と使用および、スキーマの指定をご覧ください。
データ転送のテーブルを表示するには、次のようにします。
Google Cloud コンソールの [BigQuery] ページに移動します。[BigQuery] ページに移動
[データ転送] をクリックします。利用可能なすべてのデータ転送を表示できます。
リスト内の該当する転送をクリックします。
[構成] タブをクリックして、データセットをクリックします。
[エクスプローラ] パネルでプロジェクトを展開し、データセットを選択します。[詳細] パネルに説明と詳細が表示されます。データセットのテーブルは、[エクスプローラ] パネルにデータセット名とともに表示されます。
バックフィルのスケジュールを設定する
過去の日付の推奨事項(組織がエクスポートを有効にした日付より後の日付)は、バックフィルをスケジュールすることでエクスポートできます。バックフィルをスケジュールするには、次のようにします。
Google Cloud コンソールの [BigQuery] ページに移動します。
[データ転送] をクリックします。
[転送] ページで、リストから該当する転送をクリックします。
[バックフィルのスケジュール構成] をクリックします。
[バックフィルのスケジュール構成] ダイアログで、[開始日] と [終了日] を選択します。

転送の操作の詳細については、転送の操作をご覧ください。
エクスポート スキーマ
推奨事項のエクスポート テーブル:
schema:
fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: recommender
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: recommender_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: primary_impact
type: RECORD
description: |
Required. The primary impact that this recommendation can have while trying to optimize
for one category.
schema:
fields:
- name: category
type: STRING
description: |
Category that is being targeted.
Values can be the following:
CATEGORY_UNSPECIFIED:
Default unspecified category. Do not use directly.
COST:
Indicates a potential increase or decrease in cost.
SECURITY:
Indicates a potential increase or decrease in security.
PERFORMANCE:
Indicates a potential increase or decrease in performance.
RELIABILITY:
Indicates a potential increase or decrease in reliability.
- name: cost_projection
type: RECORD
description: Optional. Use with CategoryType.COST
schema:
fields:
- name: cost
type: RECORD
description: |
An approximate projection on amount saved or amount incurred.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: cost_in_local_currency
type: RECORD
description: |
An approximate projection on amount saved or amount incurred in the local currency.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: duration
type: RECORD
description: Duration for which this cost applies.
schema:
fields:
- name: seconds
type: INTEGER
description: |
Signed seconds of the span of time. Must be from -315,576,000,000
to +315,576,000,000 inclusive. Note: these bounds are computed from:
60 sec/min * 60 min/hr * 24 hr/day * 365.25 days/year * 10000 years
- name: nanos
type: INTEGER
description: |
Signed fractions of a second at nanosecond resolution of the span
of time. Durations less than one second are represented with a 0
`seconds` field and a positive or negative `nanos` field. For durations
of one second or more, a non-zero value for the `nanos` field must be
of the same sign as the `seconds` field. Must be from -999,999,999
to +999,999,999 inclusive.
- name: pricing_type_name
type: STRING
description: |
A pricing type can either be based on the price listed on GCP (LIST) or a custom
price based on past usage (CUSTOM).
- name: reliability_projection
type: RECORD
description: Optional. Use with CategoryType.RELIABILITY
schema:
fields:
- name: risk_types
type: STRING
mode: REPEATED
description: |
The risk associated with the reliability issue.
RISK_TYPE_UNSPECIFIED:
Default unspecified risk. Do not use directly.
SERVICE_DISRUPTION:
Potential service downtime.
DATA_LOSS:
Potential data loss.
ACCESS_DENY:
Potential access denial. The service is still up but some or all clients
can not access it.
- name: details_json
type: STRING
description: |
Additional reliability impact details that is provided by the recommender in JSON
format.
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_insights
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: recommendation_details
type: STRING
description: |
Additional details about the recommendation in JSON format.
schema:
- name: overview
type: RECORD
description: Overview of the recommendation in JSON format
- name: operation_groups
type: OperationGroup
mode: REPEATED
description: Operations to one or more Google Cloud resources grouped in such a way
that, all operations within one group are expected to be performed
atomically and in an order. More here: https://cloud.google.com/recommender/docs/key-concepts#operation_groups
- name: operations
type: Operation
description: An Operation is the individual action that must be performed as one of the atomic steps in a suggested recommendation. More here: https://cloud.google.com/recommender/docs/key-concepts?#operation
- name: state_metadata
type: map with key: STRING, value: STRING
description: A map of STRING key, STRING value of metadata for the state, provided by user or automations systems.
- name: additional_impact
type: Impact
mode: REPEATED
description: Optional set of additional impact that this recommendation may have when
trying to optimize for the primary category. These may be positive
or negative. More here: https://cloud.google.com/recommender/docs/key-concepts?#recommender_impact
- name: priority
type: STRING
description: |
Priority of the recommendation:
PRIORITY_UNSPECIFIED:
Default unspecified priority. Do not use directly.
P4:
Lowest priority.
P3:
Second lowest priority.
P2:
Second highest priority.
P1:
Highest priority.
分析情報のエクスポート テーブル:
schema:
- fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: insight_type
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: insight_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: category
type: STRING
description: |
Category being targeted by the insight. Can be one of:
Unspecified category.
CATEGORY_UNSPECIFIED = Unspecified category.
COST = The insight is related to cost.
SECURITY = The insight is related to security.
PERFORMANCE = The insight is related to performance.
MANAGEABILITY = The insight is related to manageability.
RELIABILITY = The insight is related to reliability.;
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_recommendations
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: insight_details
type: STRING
description: |
Additional details about the insight in JSON format
schema:
fields:
- name: content
type: STRING
description: |
A struct of custom fields to explain the insight.
Example: "grantedPermissionsCount": "1000"
- name: observation_period
type: TIMESTAMP
description: |
Observation period that led to the insight. The source data used to
generate the insight ends at last_refresh_time and begins at
(last_refresh_time - observation_period).
- name: state_metadata
type: STRING
description: |
A map of metadata for the state, provided by user or automations systems.
- name: severity
type: STRING
description: |
Severity of the insight:
SEVERITY_UNSPECIFIED:
Default unspecified severity. Do not use directly.
LOW:
Lowest severity.
MEDIUM:
Second lowest severity.
HIGH:
Second highest severity.
CRITICAL:
Highest severity.
クエリの例
次のサンプルクエリを使用すると、エクスポートしたデータを分析できます。
推奨事項の費用削減額を表示する(推奨期間は日数で表示)
SELECT name, recommender, target_resources,
case primary_impact.cost_projection.cost.units is null
when true then round(primary_impact.cost_projection.cost.nanos * power(10,-9),2)
else
round( primary_impact.cost_projection.cost.units +
(primary_impact.cost_projection.cost.nanos * power(10,-9)), 2)
end
as dollar_amt,
primary_impact.cost_projection.duration.seconds/(60*60*24) as duration_in_days
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and primary_impact.category = "COST"
未使用の IAM ロールの一覧を表示する
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REMOVE_ROLE"
より小さいロールに置き換える必要がある、付与済みロールのリストを表示する
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REPLACE_ROLE"
推奨事項のインサイトを表示する
SELECT recommendations.name as recommendation_name,
insights.name as insight_name,
recommendations.cloud_entity_id,
recommendations.cloud_entity_type,
recommendations.recommender,
recommendations.recommender_subtype,
recommendations.description,
recommendations.target_resources,
recommendations.recommendation_details,
recommendations.state,
recommendations.last_refresh_time as recommendation_last_refresh_time,
insights.insight_type,
insights.insight_subtype,
insights.category,
insights.description,
insights.insight_details,
insights.state,
insights.last_refresh_time as insight_last_refresh_time
FROM `<project>.<dataset>.recommendations_export` as recommendations,
`<project>.<dataset>.insights_export` as insights
WHERE DATE(recommendations._PARTITIONTIME) = "<date>"
and DATE(insights._PARTITIONTIME) = "<date>"
and insights.name in unnest(recommendations.associated_insights)
特定のフォルダに属するプロジェクトの推奨事項を表示する
このクエリは、プロジェクトから最大 5 つのレベルの親フォルダを返します。
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and "<folder_id>" in unnest(ancestors.folder_ids)
これまでにエクスポートした最新の利用可能日に関する推奨事項を表示する
DECLARE max_date TIMESTAMP;
SET max_date = (
SELECT MAX(_PARTITIONTIME) FROM
`<project>.<dataset>.recommendations_export`
);
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE _PARTITIONTIME = max_date
スプレッドシートを使用して BigQuery データを調査する
BigQuery でクエリを実行する代わりに、新しい BigQuery データコネクタであるコネクテッド シートを使用して、スプレッドシートの数十億行にのぼる BigQuery データにアクセスし、分析、可視化、共有できます。詳しくは、Google スプレッドシートで BigQuery データを使ってみるをご覧ください。
BigQuery コマンドラインと REST API を使用したエクスポートの設定
-
必要な Identity and Access Management 権限は、Google Cloud コンソールまたはコマンドラインで取得できます。
- サービス アカウントのコマンドライン
- ユーザー向けコマンドライン:
たとえば、コマンドラインを使用してサービス アカウントの組織レベルの recommender.resources.export 権限を取得するには、次のようにします。
gcloud organizations add-iam-policy-binding *<organization_id>* --member=serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter' -
Datasource to use: 6063d10f-0000-2c12-a706-f403045e6250 エクスポートを作成します。
bq mk \ --transfer_config \ --project_id=project_id \ --target_dataset=dataset_id \ --display_name=name \ --params='parameters' \ --data_source=data_source \ --service_account_name=service_account_name
ここで
- project_id はプロジェクト ID です。
- dataset は、転送構成のターゲット データセット ID です。
- name は、転送構成の表示名です。転送名には、後で修正が必要になった場合に簡単に識別できる任意の名前を使用できます。
- parameters には、作成される転送構成のパラメータを JSON 形式で指定します。推奨事項と分析情報の BigQuery Export では、推奨事項と分析情報をエクスポートする organization_id を指定する必要があります。パラメータの形式: '{"organization_id":"<org id>"}'
- data_source 使用するデータソース: '6063d10f-0000-2c12-a706-f403045e6250'
- service_account_name は、エクスポートの認証に使用されるサービス アカウント名です。サービス アカウントは、転送の作成に使用した
project_idが所有している必要があります。また、上記の必要な権限がすべて付与されている必要があります。
UI または BigQuery コマンドラインを使用して既存のエクスポートを管理する:
注 - 今後エクスポートの構成を更新するかどうかに関係なく、書き出しはアカウントを設定したユーザーとして実行されます。たとえば、サービス アカウントを使用してエクスポートが設定され、その後ユーザーが BigQuery Data Transfer Service UI を介してエクスポート構成を更新した場合、エクスポートは引き続きサービス アカウントとして実行されます。この場合の recommender.resources.export の権限のチェックは、エクスポートが実行されるたびにサービス アカウントに対して行われます。