Esta página explica como a arquitetura do Memorystore para Valkey oferece e é compatível com alta disponibilidade (HA). Esta página também explica as configurações recomendadas que contribuem para melhorar o desempenho e a estabilidade da instância.
Alta disponibilidade
O Memorystore para Valkey é criado em uma arquitetura de alta disponibilidade em que os clientes acessam diretamente os nós gerenciados do Memorystore para Valkey. Para isso, os clientes se conectam a endpoints individuais, conforme descrito em Conectar-se a uma instância do Memorystore para Valkey.
A conexão direta aos fragmentos oferece os seguintes benefícios:
A conexão direta evita saltos intermediários, o que minimiza o tempo de retorno (latência do cliente) entre o cliente e o nó do Valkey.
No modo de cluster ativado, a conexão direta evita qualquer ponto único de falha porque cada fragmento é projetado para falhar de forma independente. Por exemplo, se o tráfego de vários clientes sobrecarregar um slot (parte do keyspace), a falha de fragmento vai limitar o impacto ao fragmento responsável por atender ao slot.
Configurações recomendadas
Recomendamos criar instâncias multizona de alta disponibilidade em vez de instâncias de zona única devido à maior confiabilidade que elas oferecem. No entanto, se você optar por provisionar uma instância sem réplicas, recomendamos escolher uma instância de zona única. Para mais informações, consulte Escolher uma instância de zona única se ela não usar réplicas.
Para ativar a alta disponibilidade da sua instância, provisione pelo menos um nó de réplica para cada fragmento. Você pode fazer isso ao criar a instância ou escalonar a contagem de réplicas para pelo menos uma réplica por fragmento. As réplicas oferecem failover automático durante a manutenção planejada e falhas inesperadas de fragmentos.
Configure seu cliente de acordo com as orientações em Práticas recomendadas para clientes. Usar as práticas recomendadas permite que seu cliente processe automaticamente e sem tempo de inatividade os seguintes itens da sua instância:
A função (failovers automáticos)
O endpoint (substituição de nó)
Mudanças na atribuição de slots relacionadas ao modo de cluster ativado (escalonar horizontalmente e redução horizontal do consumidor)
Réplicas
Uma instância altamente disponível do Memorystore para Valkey é um recurso regional. Isso significa que o Memorystore para Valkey distribui nós principais e de réplica de fragmentos em várias zonas para proteger contra uma interrupção zonal. O Memorystore para Valkey é compatível com instâncias com 0, 1 ou 2 réplicas por nó.
É possível usar réplicas para aumentar a capacidade de leitura, mas isso pode causar defasagem nos dados.
- Modo de cluster ativado:use o comando
READONLYpara estabelecer uma conexão que permita ao cliente ler das réplicas. - Modo de cluster desativado:conecte-se ao endpoint de leitura para acessar qualquer uma das réplicas disponíveis.
Formatos de instância com o modo de cluster ativado
Os diagramas a seguir ilustram formas para instâncias com o modo de cluster ativado:
Com três fragmentos e zero réplicas por nó
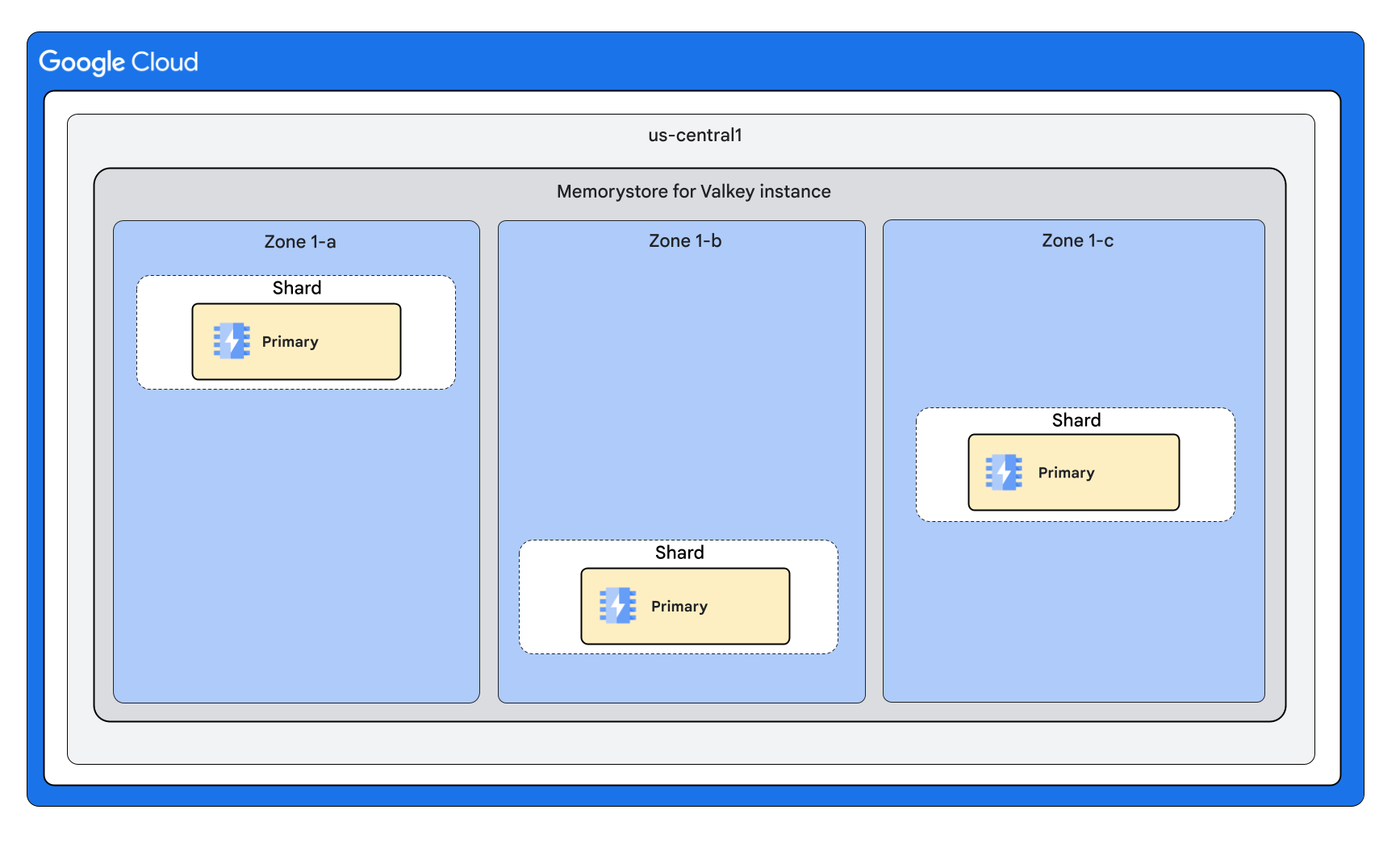
Com três fragmentos e uma réplica por nó
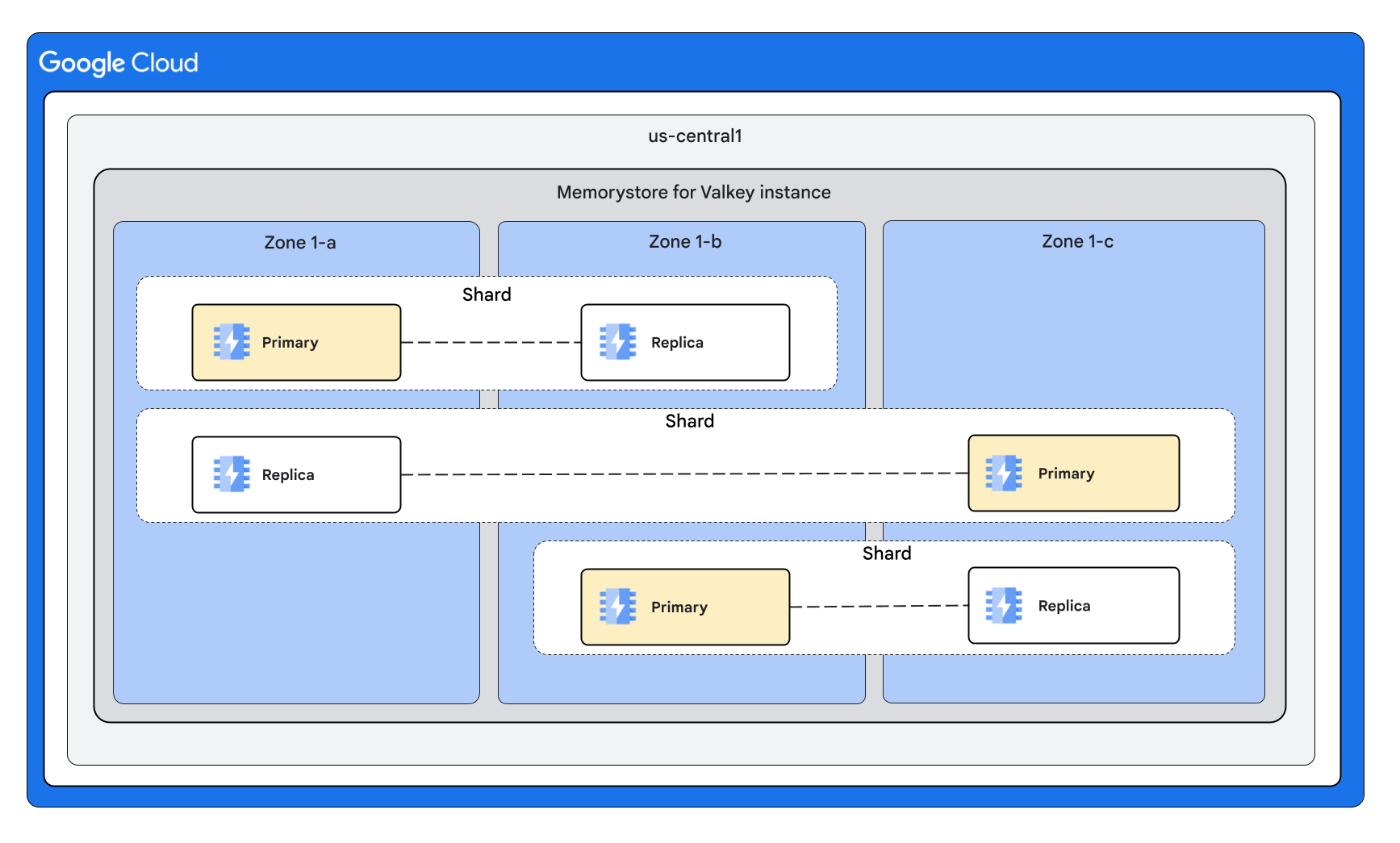
Com três fragmentos e duas réplicas por nó
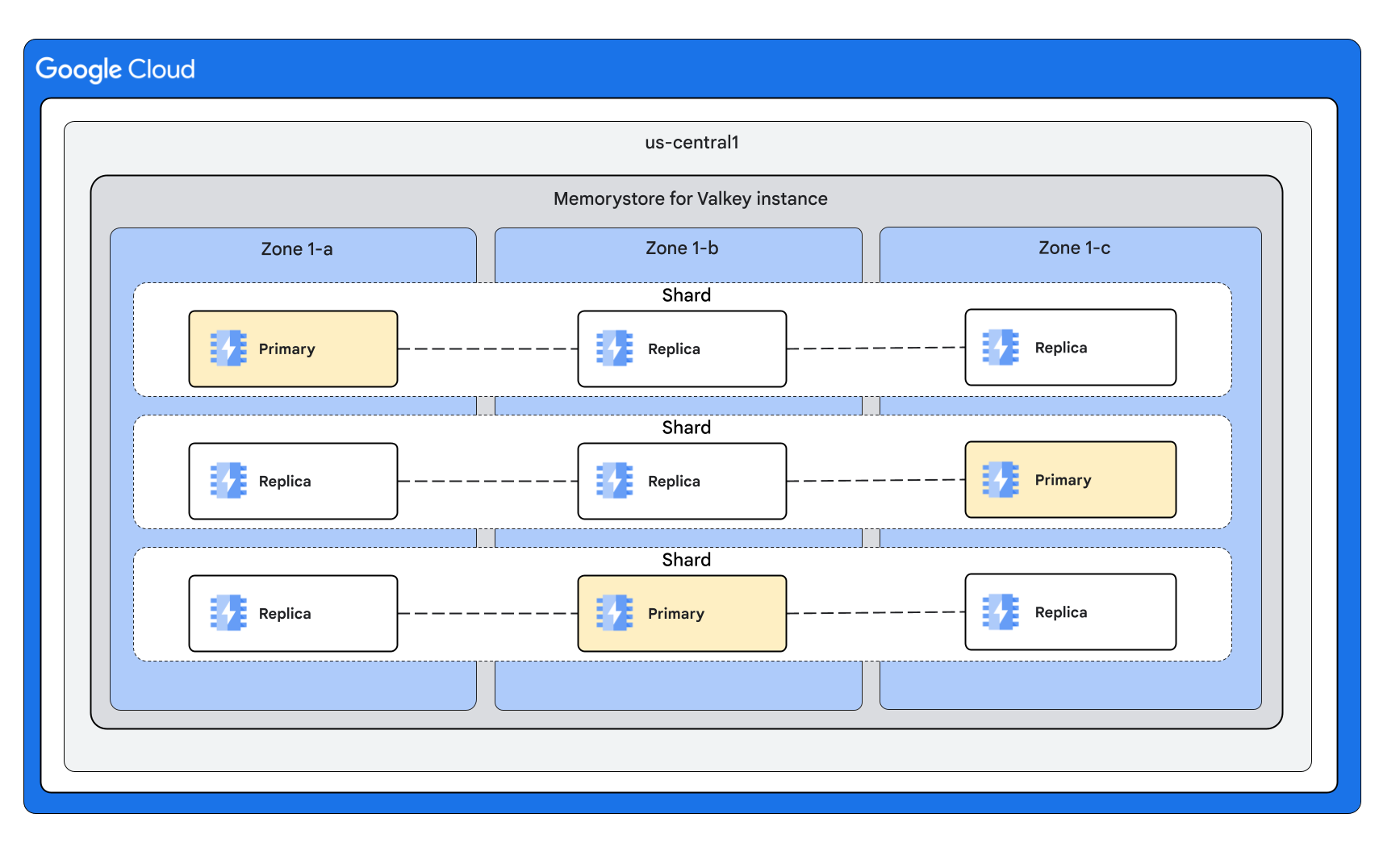
Formatos de instância com o modo de cluster desativado
Os diagramas a seguir ilustram formas para instâncias com o modo de cluster desativado:
Com duas réplicas
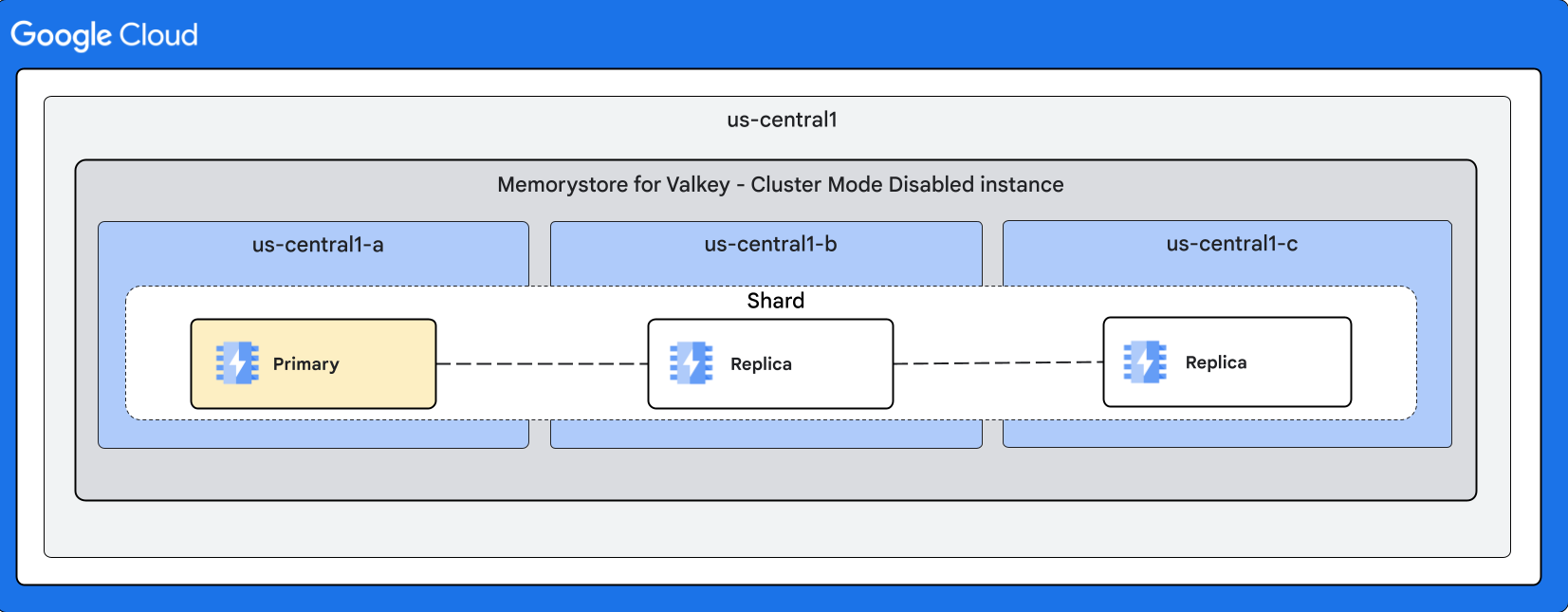
Failover automático
Os failovers automáticos em um fragmento podem ocorrer devido a manutenção ou a uma falha inesperada no nó principal. Durante um failover, uma réplica é promovida para ser a principal. É possível configurar réplicas explicitamente. O serviço também pode provisionar temporariamente réplicas extras durante a manutenção interna para evitar inatividade.
Os failovers automáticos evitam a perda de dados durante as atualizações de manutenção. Para detalhes sobre o comportamento de failover automático durante a manutenção, consulte Comportamento de failover automático durante a manutenção.
Duração do failover e do reparo de nós
Os failovers automáticos podem levar dezenas de segundos para eventos não planejados, como uma falha no processo do nó principal ou uma falha de hardware. Durante esse período, o sistema detecta a falha e escolhe uma réplica para ser a nova primária.
O reparo de nós pode levar alguns minutos para que o serviço substitua o nó com falha. Isso vale para todos os nós principais e de réplica. Para instâncias que não são altamente disponíveis (sem réplicas provisionadas), o reparo de um nó principal com falha também leva alguns minutos.
Comportamento do cliente durante um failover não planejado
As conexões do cliente provavelmente serão redefinidas, dependendo da natureza da falha. Após a recuperação automática, as conexões precisam ser repetidas com espera exponencial para evitar sobrecarga nos nós primários e de réplica.
Os clientes que usam réplicas para capacidade de leitura precisam se preparar para uma degradação temporária na capacidade até que o nó com falha seja substituído automaticamente.
Gravações perdidas
Durante um failover resultante de uma falha inesperada, gravações reconhecidas podem ser perdidas devido à natureza assíncrona do protocolo de replicação do Valkey.
Os aplicativos clientes podem usar o comando WAIT do Valkey para melhorar a segurança dos dados do mundo real.
Impacto de uma falha temporária de zona única no keyspace
Esta seção descreve o impacto de uma interrupção de zona única em uma instância do Memorystore para Valkey.
Instâncias multizonais
Instâncias de alta disponibilidade:se uma zona tiver uma interrupção, todo o espaço de chaves estará disponível para leitura e gravação, mas como algumas réplicas de leitura estão indisponíveis, a capacidade de leitura será reduzida. Recomendamos provisionar a capacidade do cluster para que a instância tenha capacidade de leitura suficiente, no caso raro de uma interrupção em uma única zona. Quando a interrupção terminar, as réplicas na zona afetada serão restauradas, e a capacidade de leitura do cluster voltará ao valor configurado. Para mais informações, consulte Padrões para apps escalonáveis e confiáveis.
Instâncias não HA (sem réplicas): se uma zona tiver uma interrupção, a parte do espaço de chaves provisionada na zona afetada passará por uma limpeza de dados e ficará indisponível para gravações ou leituras durante a interrupção. Quando a interrupção terminar, as instâncias principais na zona afetada serão restauradas, e a capacidade do cluster voltará ao valor configurado.
Instâncias de zona única
- Instâncias de alta disponibilidade e sem alta disponibilidade:se a zona em que a instância é provisionada tiver uma interrupção, o cluster ficará indisponível e os dados serão liberados. Se uma zona diferente tiver uma interrupção, o cluster vai continuar atendendo às solicitações de leitura e gravação.
Práticas recomendadas
Esta seção descreve as práticas recomendadas para alta disponibilidade e réplicas.
Adicionar uma réplica
Para adicionar uma réplica, é necessário um snapshot do RDB. Os snapshots do RDB usam um fork de processo e um mecanismo de cópia na gravação para criar um snapshot dos dados do nó. Dependendo do padrão de gravações nos nós, a memória usada dos nós aumenta à medida que as páginas afetadas pelas gravações são copiadas. A ocupação de memória pode ser até o dobro do tamanho dos dados no nó.
Para garantir que os nós tenham memória suficiente para concluir o snapshot, mantenha ou
defina maxmemory em 80% da
capacidade do nó para que 20% sejam reservados para sobrecarga. Esse overhead de memória, além dos snapshots de monitoramento, ajuda você a gerenciar sua carga de trabalho para ter snapshots bem-sucedidos. Além disso, ao adicionar réplicas, reduza o tráfego de gravação o máximo possível. Para mais informações, consulte Monitorar o uso de memória de uma instância.