Mentranskode data secara lokal di mainframe adalah proses yang intensif CPU yang menghasilkan konsumsi million instructions per second (MIPS) yang tinggi. Untuk menghindari hal ini, Anda dapat menggunakan Cloud Run untuk memindahkan dan mentranskode data mainframe dari jarak jauh di Google Cloud. Tindakan ini akan membebaskan mainframe Anda untuk tugas penting bisnis dan juga mengurangi konsumsi MIPS.
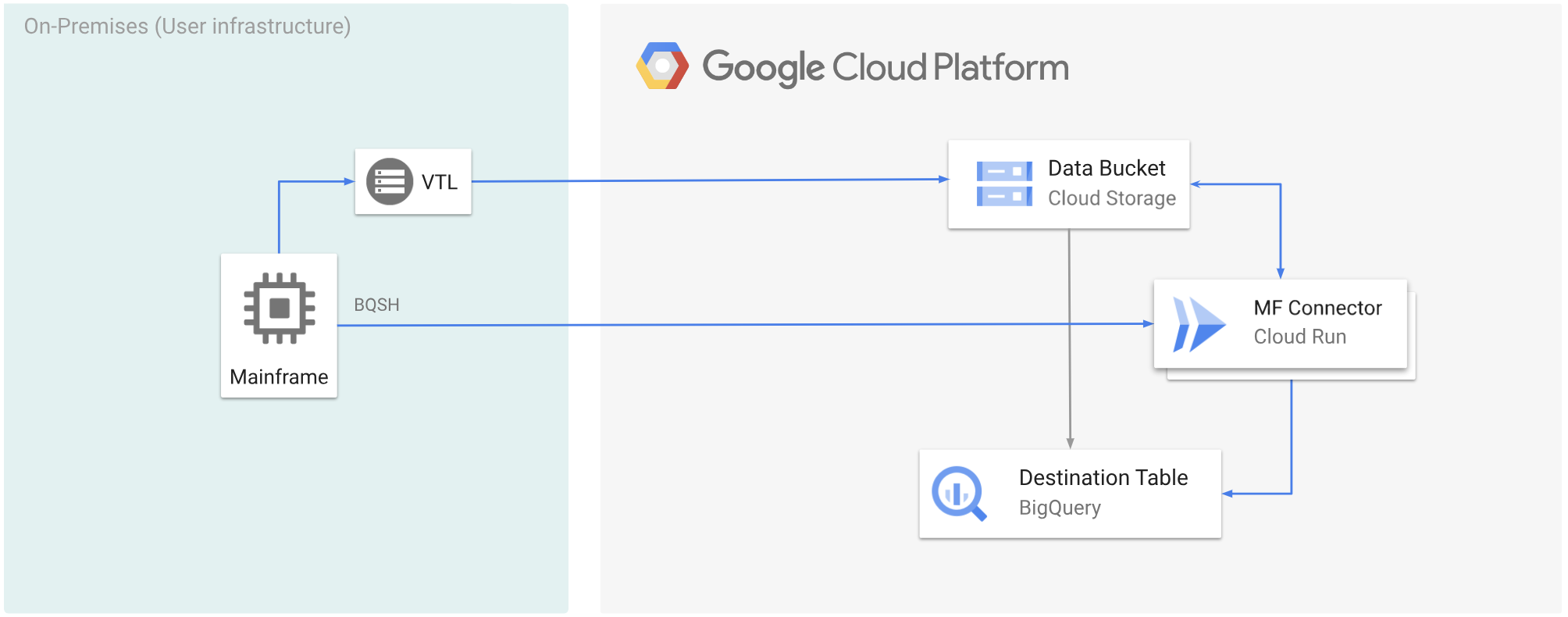
Jika Anda ingin memindahkan data dalam volume yang sangat besar (sekitar 500 GB per hari atau lebih) dari mainframe ke Google Cloud, dan tidak ingin menggunakan mainframe untuk upaya ini, Anda dapat menggunakan solusi Virtual Tape Library (VTL) yang mendukung cloud untuk mentransfer data ke bucket Cloud Storage. Kemudian, Anda dapat menggunakan Cloud Run untuk mentranskode data yang ada di bucket dan memindahkannya ke BigQuery.
Halaman ini membahas cara membaca data mainframe yang disalin ke bucket Cloud Storage, mengonversinya dari set data extended binary coded decimal interchange code (EBCDIC) ke format ORC dalam UTF-8, dan memuat set data ke tabel BigQuery.
Diagram berikut menunjukkan cara memindahkan data mainframe ke bucket Cloud Storage menggunakan solusi VTL, mentranskode data ke format ORC menggunakan Cloud Run, lalu memindahkan konten ke BigQuery.
Sebelum memulai
- Pilih solusi VTL yang sesuai dengan persyaratan Anda, lalu pindahkan data mainframe Anda ke bucket Cloud Storage dan simpan sebagai
.dat. Pastikan Anda menambahkan kunci metadata bernamax-goog-meta-lreclke file.datyang diupload, dan panjang kunci metadata sama dengan panjang data file asli, misalnya 80. - Men-deploy Mainframe Connector di Cloud Run.
- Di mainframe, tetapkan variabel lingkungan
GCSDSNURIke awalan yang telah Anda gunakan untuk data mainframe di bucket Cloud Storage.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: Nama bucket Cloud Storage.
- PREFIX: Awalan yang ingin Anda gunakan di bucket.
- Buat akun layanan atau identifikasi akun layanan yang ada untuk digunakan dengan Mainframe Connector. Akun layanan ini harus memiliki izin untuk mengakses bucket Cloud Storage, set data BigQuery, dan resource Google Cloud lainnya yang ingin Anda gunakan.
- Pastikan akun layanan yang Anda buat diberi peran Cloud Run Invoker.
Mentranskode data mainframe yang diupload ke bucket Cloud Storage
Untuk memindahkan data mainframe ke Google Cloud menggunakan VTL dan melakukan transcoding dari jarak jauh, Anda harus melakukan tugas berikut:
- Membaca dan mentranskode data yang ada di bucket Cloud Storage ke format ORC. Operasi transcoding mengonversi set data EBCDIC mainframe ke format ORC dalam UTF-8.
- Muat set data ke tabel BigQuery.
- (Opsional) Jalankan kueri SQL pada tabel BigQuery.
- (Opsional) Mengekspor data dari BigQuery ke file biner di Cloud Storage.
Untuk melakukan tugas ini, ikuti langkah-langkah berikut:
Di mainframe, buat tugas untuk membaca data dari file
.datdi bucket Cloud Storage, dan transkode ke format ORC, seperti berikut.Untuk mengetahui daftar lengkap variabel lingkungan yang didukung oleh Mainframe Connector, lihat Variabel lingkungan.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*Ganti kode berikut:
PROJECT_NAME: Nama project tempat Anda ingin menjalankan kueri.INPUT_FILENAME: Nama file.datyang Anda upload ke bucket Cloud Storage.
Jika ingin mencatat perintah yang dieksekusi selama proses ini, Anda dapat mengaktifkan statistik pemuatan.
(Opsional) Buat dan kirim tugas kueri BigQuery yang menjalankan pembacaan SQL dari file DD QUERY. Biasanya, kueri akan berupa pernyataan
MERGEatauSELECT INTO DMLyang menghasilkan transformasi tabel BigQuery. Perhatikan bahwa Konektor Mainframe mencatat metrik tugas, tetapi tidak menulis hasil kueri ke file.Anda dapat membuat kueri BigQuery dengan berbagai cara-inline, dengan set data terpisah menggunakan DD, atau dengan set data terpisah menggunakan DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*Ganti kode berikut:
PROJECT_NAME: Nama project tempat Anda ingin menjalankan kueri.LOCATION: Lokasi tempat kueri akan dijalankan. Sebaiknya jalankan kueri di lokasi yang dekat dengan data.
(Opsional) Buat dan kirim tugas ekspor yang mengeksekusi pembacaan SQL dari file DD QUERY, dan ekspor set data yang dihasilkan ke Cloud Storage sebagai file biner.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Ganti kode berikut:
PROJECT_NAME: Nama project tempat Anda ingin menjalankan kueri.DATASET_ID: ID set data BigQuery yang berisi tabel yang ingin Anda ekspor.DESTINATION_TABLE: Tabel BigQuery yang ingin Anda ekspor.BUCKET: Bucket Cloud Storage yang akan berisi file biner output.