A transcodificação de dados localmente em um mainframe é um processo que consome muita CPU e resulta em um alto consumo de milhões de instruções por segundo (MIPS). Para evitar isso, use o Cloud Run para mover e transcodificar dados de mainframe remotamente no formatoGoogle Cloud para ORC (formato de linha otimizada) e mova os dados para o Cloud Storage. Isso libera seu mainframe para tarefas essenciais de negócios e também reduz o consumo de MIPS.
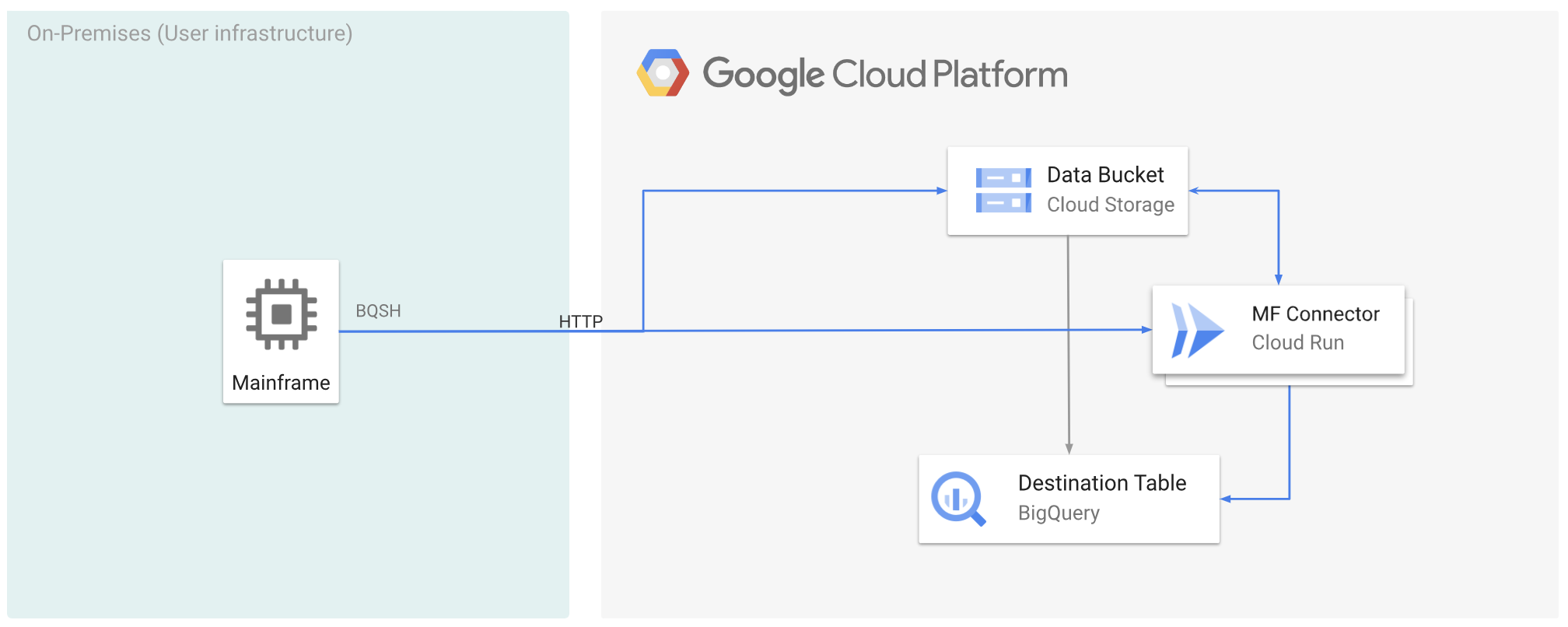
A figura a seguir descreve como mover os dados do mainframe para o Google Cloud e fazer a transcodificação remotamente para o formato ORC usando o Cloud Run e, em seguida, mover o conteúdo para o BigQuery.
Antes de começar
- Implantar o conector de mainframe no Cloud Run.
- Crie uma conta de serviço ou identifique uma conta de serviço atual para usar com o Mainframe Connector. Essa conta de serviço precisa ter permissões para acessar buckets do Cloud Storage, conjuntos de dados do BigQuery e qualquer outro Google Cloud recurso que você queira usar.
- Verifique se a conta de serviço criada recebeu o papel de Invocador do Cloud Run.
Mover dados do mainframe para o Google Cloud e fazer a transcodificação remotamente usando o Cloud Run
Para mover os dados do mainframe para o Google Cloud e fazer a transcodificação remotamente usando o Cloud Run, você precisa realizar as seguintes tarefas:
- Leia e transcodifique um conjunto de dados em um mainframe e faça upload dele no Cloud Storage
no formato ORC. A transcodificação é feita durante a operação
gsutil cp, em que um conjunto de dados de código binário estendido (EBCDIC) de mainframe é convertido para o formato ORC em UTF-8 durante a cópia para um bucket do Cloud Storage. - Carregar o conjunto de dados em uma tabela do BigQuery.
- (Opcional) Execute uma consulta SQL na tabela do BigQuery.
- (Opcional) Exporte dados do BigQuery para um arquivo binário no Cloud Storage.
Para realizar essas tarefas, siga estas etapas:
No mainframe, crie um job para ler o conjunto de dados e transcodificar para o formato ORC, conforme mostrado a seguir. Leia os dados do conjunto de dados INFILE e o layout de registro do COPYBOOK DD. O conjunto de dados de entrada precisa ser um arquivo de método de acesso sequencial em fila (QSAM, na sigla em inglês) com comprimento de registro fixo ou variável.
Para conferir a lista completa de variáveis de ambiente compatíveis com o Mainframe Connector, consulte Variáveis de ambiente.
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Se você quiser registrar os comandos executados durante esse processo, ative as estatísticas de carga.
(Opcional) Crie e envie um job de consulta do BigQuery que execute uma leitura SQL do arquivo QUERY DD. Normalmente, a consulta será uma instrução
MERGEouSELECT INTO DMLque resulta na transformação de uma tabela do BigQuery. O conector de mainframe registra nas métricas do job, mas não grava os resultados da consulta em um arquivo.É possível consultar o BigQuery de várias maneiras: inline, com um conjunto de dados separado usando DD ou com um conjunto de dados separado usando DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*Além disso, é necessário definir a variável de ambiente
BQ_QUERY_REMOTE_EXECUTION=true.Substitua:
PROJECT_NAME: o nome do projeto em que você quer executar a consulta.LOCATION: o local em que a consulta será executada. Recomendamos que você execute a consulta em um local próximo aos dados.
(Opcional) Crie e envie um job de exportação que execute uma leitura SQL do arquivo QUERY DD e exporte o conjunto de dados resultante para o Cloud Storage como um arquivo binário.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Substitua:
PROJECT_NAME: o nome do projeto em que você quer executar a consulta.DATASET_ID: o ID do conjunto de dados do BigQuery que contém a tabela que você quer exportar.DESTINATION_TABLE: a tabela do BigQuery que você quer exportar.BUCKET: o bucket do Cloud Storage que vai conter o arquivo binário de saída.
A seguir
- Mover dados de mainframe transcodificados localmente para Google Cloud
- Transcodificar dados de mainframe remotamente no Google Cloud
- Transcodificar dados de mainframe movidos para Google Cloud usando uma biblioteca de fitas virtual