A transcodificação de dados localmente em um mainframe é um processo que exige muita CPU e resulta em um alto consumo de milhões de instruções por segundo (MIPS). Para evitar isso, use o Cloud Run para mover e transcodificar dados de mainframe remotamente noGoogle Cloud. Isso libera seu mainframe para tarefas essenciais de negócios e também reduz o consumo de MIPS.
Se você quiser transferir volumes muito grandes de dados (cerca de 500 GB por dia ou mais) do mainframe para Google Cloude não quiser usar o mainframe para essa tarefa, use uma solução de biblioteca de fitas virtual (VTL, na sigla em inglês) ativada pela nuvem para transferir os dados para um bucket do Cloud Storage. Em seguida, use o Cloud Run para transcodificar os dados presentes no bucket e movê-los para o BigQuery.
Esta página discute como ler dados de mainframe copiados em um bucket do Cloud Storage, fazer a transcodificação do conjunto de dados do código de troca decimal codificado em binário estendido (EBCDIC, na sigla em inglês) para o formato ORC em UTF-8 e carregar o conjunto de dados em uma tabela do BigQuery.
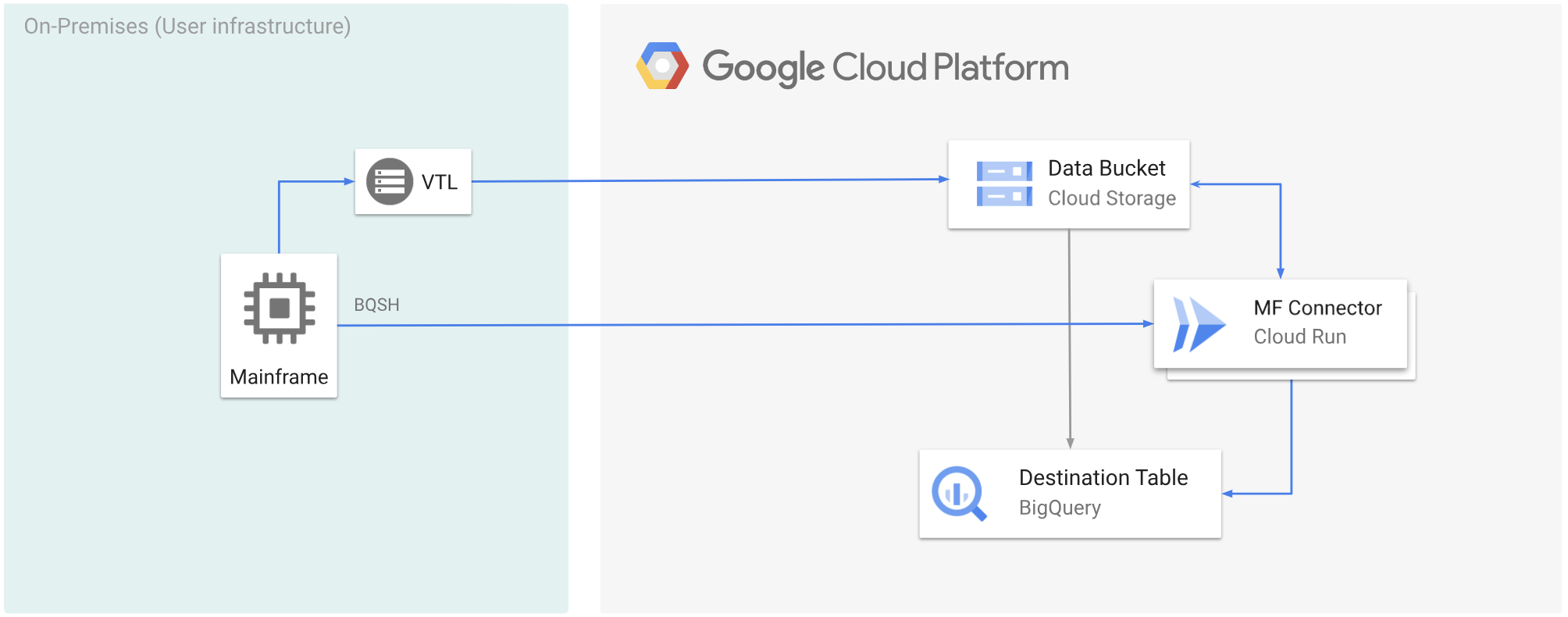
O diagrama a seguir mostra como mover os dados do mainframe para um bucket do Cloud Storage usando uma solução de VTL, transcodificar os dados para o formato ORC usando o Cloud Run e mover o conteúdo para o BigQuery.
Antes de começar
- Escolha uma solução de VTL que atenda aos seus requisitos e mova os dados do mainframe
para um bucket do Cloud Storage e salve-os como
.dat. Adicione uma chave de metadados chamadax-goog-meta-lreclao arquivo.datenviado e verifique se o comprimento da chave de metadados é igual ao comprimento do registro do arquivo original, por exemplo, 80. - Implantar o Mainframe Connector no Cloud Run.
- No mainframe, defina a variável de ambiente
GCSDSNURIcomo o prefixo que você usou para os dados do mainframe no bucket do Cloud Storage.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: o nome do bucket do Cloud Storage.
- PREFIX: o prefixo que você quer usar no bucket.
- Crie uma conta de serviço ou identifique uma conta de serviço atual para usar com o Mainframe Connector. Essa conta de serviço precisa ter permissões para acessar buckets do Cloud Storage, conjuntos de dados do BigQuery e qualquer outro Google Cloud recurso que você queira usar.
- Verifique se a conta de serviço criada recebeu o papel de invocador do Cloud Run.
Transcodificar dados do mainframe enviados para um bucket do Cloud Storage
Para mover dados de mainframe para Google Cloud usando VTL e transcodificação remota, realize as seguintes tarefas:
- Leia e transcodifique os dados presentes em um bucket do Cloud Storage para o formato ORC. A operação de transcodificação converte um conjunto de dados EBCDIC de mainframe para o formato ORC em UTF-8.
- Carregar o conjunto de dados em uma tabela do BigQuery.
- (Opcional) Execute uma consulta SQL na tabela do BigQuery.
- (Opcional) Exporte dados do BigQuery para um arquivo binário no Cloud Storage.
Para realizar essas tarefas, siga estas etapas:
No mainframe, crie um job para ler os dados de um arquivo
.datem um bucket do Cloud Storage e transcodificar para o formato ORC, conforme mostrado a seguir.Para conferir a lista completa de variáveis de ambiente compatíveis com o Mainframe Connector, consulte Variáveis de ambiente.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*Substitua:
PROJECT_NAME: o nome do projeto em que você quer executar a consulta.INPUT_FILENAME: o nome do arquivo.datque você enviou para um bucket do Cloud Storage.
Se você quiser registrar os comandos executados durante esse processo, ative as estatísticas de carga.
(Opcional) Crie e envie um job de consulta do BigQuery que execute uma leitura SQL do arquivo QUERY DD. Normalmente, a consulta será uma instrução
MERGEouSELECT INTO DMLque resulta na transformação de uma tabela do BigQuery. O conector de mainframe registra nas métricas do job, mas não grava os resultados da consulta em um arquivo.É possível consultar o BigQuery de várias maneiras: inline, com um conjunto de dados separado usando DD ou com um conjunto de dados separado usando DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*Substitua:
PROJECT_NAME: o nome do projeto em que você quer executar a consulta.LOCATION: o local em que a consulta será executada. Recomendamos que você execute a consulta em um local próximo aos dados.
(Opcional) Crie e envie um job de exportação que execute uma leitura SQL do arquivo QUERY DD e exporte o conjunto de dados resultante para o Cloud Storage como um arquivo binário.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Substitua:
PROJECT_NAME: o nome do projeto em que você quer executar a consulta.DATASET_ID: o ID do conjunto de dados do BigQuery que contém a tabela que você quer exportar.DESTINATION_TABLE: a tabela do BigQuery que você quer exportar.BUCKET: o bucket do Cloud Storage que vai conter o arquivo binário de saída.