La mayoría de los balanceadores de carga usan un enfoque de hash basado en flujo o round-robin para distribuir el tráfico. Los balanceadores de carga que usan este enfoque pueden tener dificultades para adaptarse cuando la demanda de tráfico supera la capacidad de servicio disponible. En este tutorial se muestra cómo Cloud Load Balancing optimiza la capacidad de tu aplicación global, lo que se traduce en una mejor experiencia de usuario y en costes más bajos en comparación con la mayoría de las implementaciones de balanceo de carga.
Este artículo forma parte de una serie de prácticas recomendadas para los productos de Cloud Load Balancing. Este tutorial se complementa con el artículo conceptual Optimizaciones de la capacidad de las aplicaciones con el balanceo de carga mundial, que explica con más detalle los mecanismos subyacentes del desbordamiento del balanceo de carga mundial. Para obtener más información sobre la latencia, consulta el artículo Optimizar la latencia de las aplicaciones con Cloud Load Balancing.
En este tutorial se presupone que tienes experiencia con Compute Engine. También debes conocer los conceptos básicos del balanceador de carga de aplicación externo.
Objetivos
En este tutorial, configurarás un servidor web sencillo que ejecute una aplicación que requiera mucha CPU y que calcule conjuntos de Mandelbrot. Empieza midiendo su capacidad de red con herramientas de prueba de carga (siege y httperf). A continuación, escala la red a varias instancias de VM en una sola región y mide el tiempo de respuesta bajo carga. Por último, escalará la red a varias regiones mediante el balanceo de carga global y, a continuación, medirá el tiempo de respuesta del servidor bajo carga y lo comparará con el balanceo de carga de una sola región. Al realizar esta secuencia de pruebas, podrás ver los efectos positivos de la gestión de carga entre regiones de Cloud Load Balancing.
La velocidad de comunicación de red de una arquitectura de servidor de tres niveles típica suele estar limitada por la velocidad del servidor de aplicaciones o la capacidad de la base de datos, en lugar de por la carga de la CPU en el servidor web. Después de completar el tutorial, puedes usar las mismas herramientas de prueba de carga y ajustes de capacidad para optimizar el comportamiento del balanceo de carga en una aplicación real.
Deberás hacer lo siguiente:
- Consulta cómo usar las herramientas de prueba de carga (
siegeyhttperf). - Determina la capacidad de servicio de una sola instancia de VM.
- Mide los efectos de la sobrecarga con el balanceo de carga de una sola región.
- Mide los efectos del desbordamiento a otra región con el balanceo de carga global.
Costes
En este tutorial se usan componentes facturables de Google Cloud, como los siguientes:
- Compute Engine
- Balanceo de carga y reglas de reenvío
Usa la calculadora de precios para generar una estimación de costes en función del uso previsto.
Antes de empezar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Configurar un entorno
En esta sección, configurará los ajustes del proyecto, la red de VPC y las reglas de cortafuegos básicas que necesita para completar el tutorial.
Iniciar una instancia de Cloud Shell
Abre Cloud Shell desde la Google Cloud consola. A menos que se indique lo contrario, el resto del tutorial se ejecuta desde Cloud Shell.
Configura los ajustes del proyecto
Para que te resulte más fácil ejecutar comandos gcloud, puedes definir propiedades para no tener que proporcionar opciones para estas propiedades con cada comando.
Configura tu proyecto predeterminado con el ID de proyecto
[PROJECT_ID]:gcloud config set project [PROJECT_ID]
Define tu zona predeterminada de Compute Engine. Para ello, usa la zona que prefieras para
[ZONE]y, a continuación, define esta zona como variable de entorno para usarla más adelante:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
Crear y configurar la red VPC
Crea una red de VPC para hacer pruebas:
gcloud compute networks create lb-testing --subnet-mode auto
Define una regla de cortafuegos para permitir el tráfico interno:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11Define una regla de cortafuegos para permitir que el tráfico SSH se comunique con la red VPC:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
Determinar la capacidad de servicio de una sola instancia de VM
Para examinar las características de rendimiento de un tipo de instancia de VM, haz lo siguiente:
Configura una instancia de máquina virtual que sirva de carga de trabajo de ejemplo (la instancia del servidor web).
Crea una segunda instancia de VM en la misma zona (la instancia de prueba de carga).
Con la segunda instancia de VM, medirás el rendimiento con pruebas de carga sencillas y herramientas de medición del rendimiento. Usarás estas mediciones más adelante en el tutorial para definir la configuración de capacidad de balanceo de carga correcta para el grupo de instancias.
La primera instancia de VM usa una secuencia de comandos de Python para crear una tarea que requiere mucha CPU. Para ello, calcula y muestra una imagen de un conjunto de Mandelbrot en cada solicitud a la ruta raíz (/). El resultado no se almacena en caché. Durante el tutorial, obtendrás la secuencia de comandos de Python del repositorio de GitHub que se usa en esta solución.
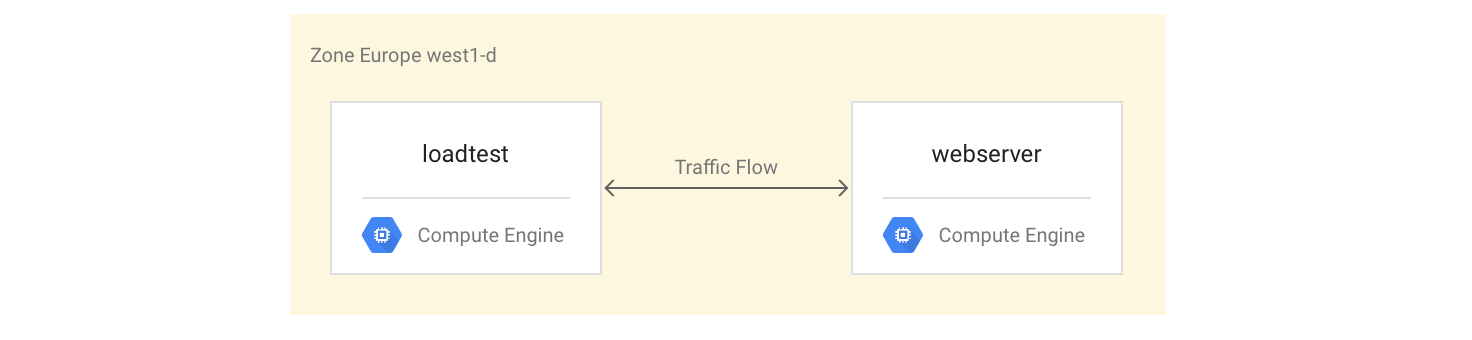
Configurar las instancias de VM
Configura la instancia de VM
webservercomo una instancia de VM de 4 núcleos instalando y, a continuación, iniciando el servidor de Mandelbrot:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crea una regla de cortafuegos para permitir el acceso externo a la instancia
webserverdesde tu máquina:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverObtén la dirección IP de la instancia
webserver:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"En un navegador web, ve a la dirección IP devuelta por el comando anterior. Verás un conjunto de Mandelbrot calculado:
Crea la instancia de prueba de carga:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
Probar las instancias de VM
El siguiente paso es ejecutar solicitudes para evaluar las características de rendimiento de la instancia de VM de prueba de carga.
Usa el comando
sshpara conectarte a la instancia de VM de prueba de carga:gcloud compute ssh loadtest
En la instancia de prueba de carga, instala siege y httperf como herramientas de prueba de carga:
sudo apt-get install -y siege httperf
La herramienta
siegepermite simular solicitudes de un número específico de usuarios, de forma que solo se hagan solicitudes posteriores cuando los usuarios hayan recibido una respuesta. De esta forma, obtendrás información valiosa sobre la capacidad y los tiempos de respuesta previstos de las aplicaciones en un entorno real.La herramienta
httperfpermite enviar un número específico de solicitudes por segundo, independientemente de si se reciben respuestas o errores. De esta forma, obtendrás información valiosa sobre cómo responden las aplicaciones a una carga específica.Mide el tiempo que tarda en completarse una solicitud sencilla al servidor web:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserverObtienes una respuesta como 0,395260. Esto significa que el servidor ha tardado 395 milisegundos (ms) en responder a tu solicitud.
Usa el siguiente comando para ejecutar 20 solicitudes de 4 usuarios en paralelo:
siege -c 4 -r 20 webserver
Verá un resultado similar al siguiente:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
El resultado se explica detalladamente en el manual de Siege, pero en este ejemplo puedes ver que los tiempos de respuesta variaron entre 0,37 y 0,7 s. De media, se respondieron 5,05 solicitudes por segundo. Estos datos ayudan a estimar la capacidad de publicación del sistema.
Ejecuta los siguientes comandos para validar los resultados con la herramienta de pruebas de carga
httperf:httperf --server webserver --num-conns 500 --rate 4
Este comando ejecuta 500 solicitudes a una frecuencia de 4 solicitudes por segundo, que es inferior a las 5,05 transacciones por segundo que ha completado
siege.Verá un resultado similar al siguiente:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
El resultado se explica en el archivo LÉEME de httperf. Fíjate en la línea que empieza por
Connection time [ms], que muestra que las conexiones han tardado entre 369,6 y 487,8 ms en total y no han generado ningún error.Repite la prueba 3 veces y define la opción
rateen 5, 7 y 10 solicitudes por segundo.En los siguientes bloques se muestran los comandos de
httperfy sus resultados (solo se muestran las líneas relevantes con información sobre el tiempo de conexión).Comando para 5 solicitudes por segundo:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
Resultados de 5 solicitudes por segundo:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando para 7 solicitudes por segundo:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
Resultados de 7 solicitudes por segundo:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Comando para 10 solicitudes por segundo:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
Resultados de 10 solicitudes por segundo:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Cierra sesión en la instancia de
webserver:exit
A partir de estas mediciones, puede concluir que el sistema tiene una capacidad de aproximadamente 5 solicitudes por segundo (RPS). Con 5 solicitudes por segundo, la instancia de VM reacciona con una latencia comparable a la de 4 conexiones. Con 7 y 10 conexiones por segundo, el tiempo de respuesta medio aumenta drásticamente a más de 10 segundos y se producen varios errores de conexión. Es decir, si se superan las 5 solicitudes por segundo, se producirán ralentizaciones significativas.
En un sistema más complejo, la capacidad del servidor se determina de forma similar, pero depende en gran medida de la capacidad de todos sus componentes. Puedes usar las herramientas siege y httperf junto con la monitorización de la carga de CPU y de E/S de todos los componentes (por ejemplo, el servidor frontend, el servidor de aplicaciones y el servidor de bases de datos) para identificar cuellos de botella. Esto, a su vez, puede ayudarte a habilitar un escalado óptimo para cada componente.
Medir los efectos de la sobrecarga con un balanceador de carga de una sola región
En esta sección, se analizan los efectos de la sobrecarga en los balanceadores de carga de una sola región, como los balanceadores de carga típicos que se usan en las instalaciones locales o el Google Cloud balanceador de carga de red de paso a través externo. También puedes observar este efecto con un balanceador de carga HTTP(S) cuando se usa para un despliegue regional (en lugar de global).
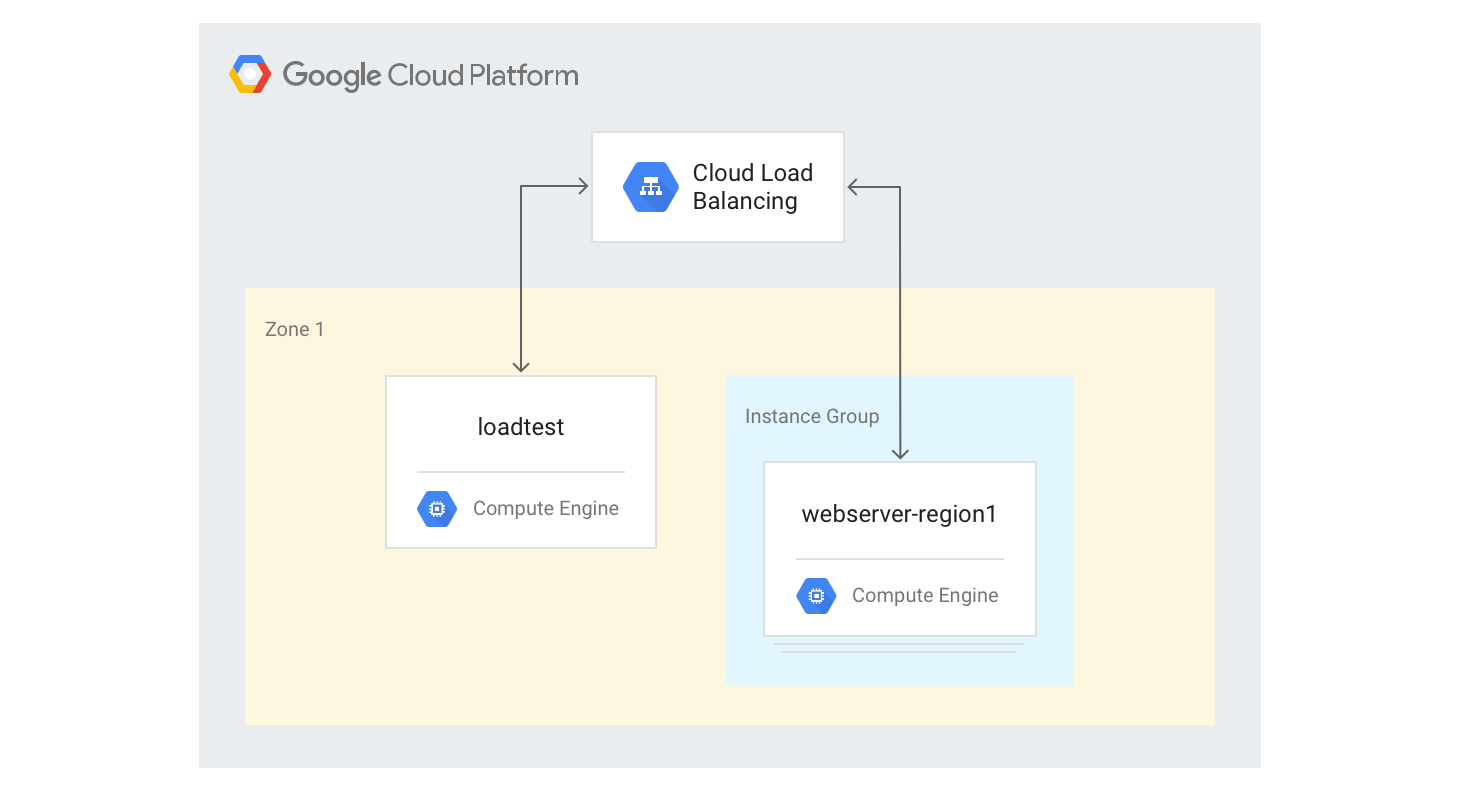
Crear el balanceador de carga HTTP(S) de una sola región
En los siguientes pasos se describe cómo crear un balanceador de carga HTTP(S) de una sola región con un tamaño fijo de 3 instancias de VM.
Crea una plantilla de instancia para las instancias de máquina virtual del servidor web con la secuencia de comandos de generación de Mandelbrot de Python que has usado antes. Ejecuta los siguientes comandos en Cloud Shell:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Crea un grupo de instancias gestionado con 3 instancias basadas en la plantilla del paso anterior:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversCrea la comprobación del estado, el servicio de backend, el mapa de URLs, el proxy de destino y la regla de reenvío global necesarios para generar el balanceo de carga HTTP:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80Obtén la dirección IP de la regla de reenvío:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
El resultado es la dirección IP pública del balanceador de carga que has creado.
En un navegador, ve a la dirección IP devuelta por el comando anterior. Al cabo de unos minutos, verás la misma imagen de Mandelbrot que has visto antes. Sin embargo, esta vez la imagen se sirve desde una de las instancias de VM del grupo que acabamos de crear.
Inicia sesión en la máquina
loadtest:gcloud compute ssh loadtest
En la línea de comandos de la máquina
loadtest, prueba la respuesta del servidor con diferentes números de solicitudes por segundo (RPS). Asegúrate de usar valores de RPS que estén comprendidos entre 5 y 20.Por ejemplo, el siguiente comando genera 10 RPS. Sustituye
[IP_address]por la dirección IP del balanceador de carga de un paso anterior de este procedimiento.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
La latencia de respuesta aumenta significativamente a medida que el número de RPS supera los 12 o 13 RPS. Aquí tienes una visualización de los resultados típicos:

Cierra la sesión de la instancia de VM
loadtest:exit
Este rendimiento es habitual en un sistema con balanceo de carga regional. A medida que la carga supera la capacidad de servicio, la latencia media y máxima de las solicitudes aumenta considerablemente. Con 10 RPS, la latencia media de las solicitudes es de casi 500 ms, pero con 20 RPS, la latencia es de 5000 ms. La latencia se ha multiplicado por diez y la experiencia de usuario se deteriora rápidamente, lo que provoca que los usuarios abandonen la aplicación o que se agote el tiempo de espera de la aplicación, o ambas cosas.
En la siguiente sección, añadirás una segunda región a la topología de balanceo de carga y compararás cómo afecta la conmutación por error interregional a la latencia del usuario final.
Medir los efectos de desbordamiento en otra región
Si usas una aplicación global con un balanceador de carga de aplicaciones externo y tienes backends desplegados en varias regiones, cuando se produce una sobrecarga de capacidad en una región, el tráfico se dirige automáticamente a otra región. Para comprobarlo, añade un segundo grupo de instancias de VM en otra región a la configuración que has creado en la sección anterior.
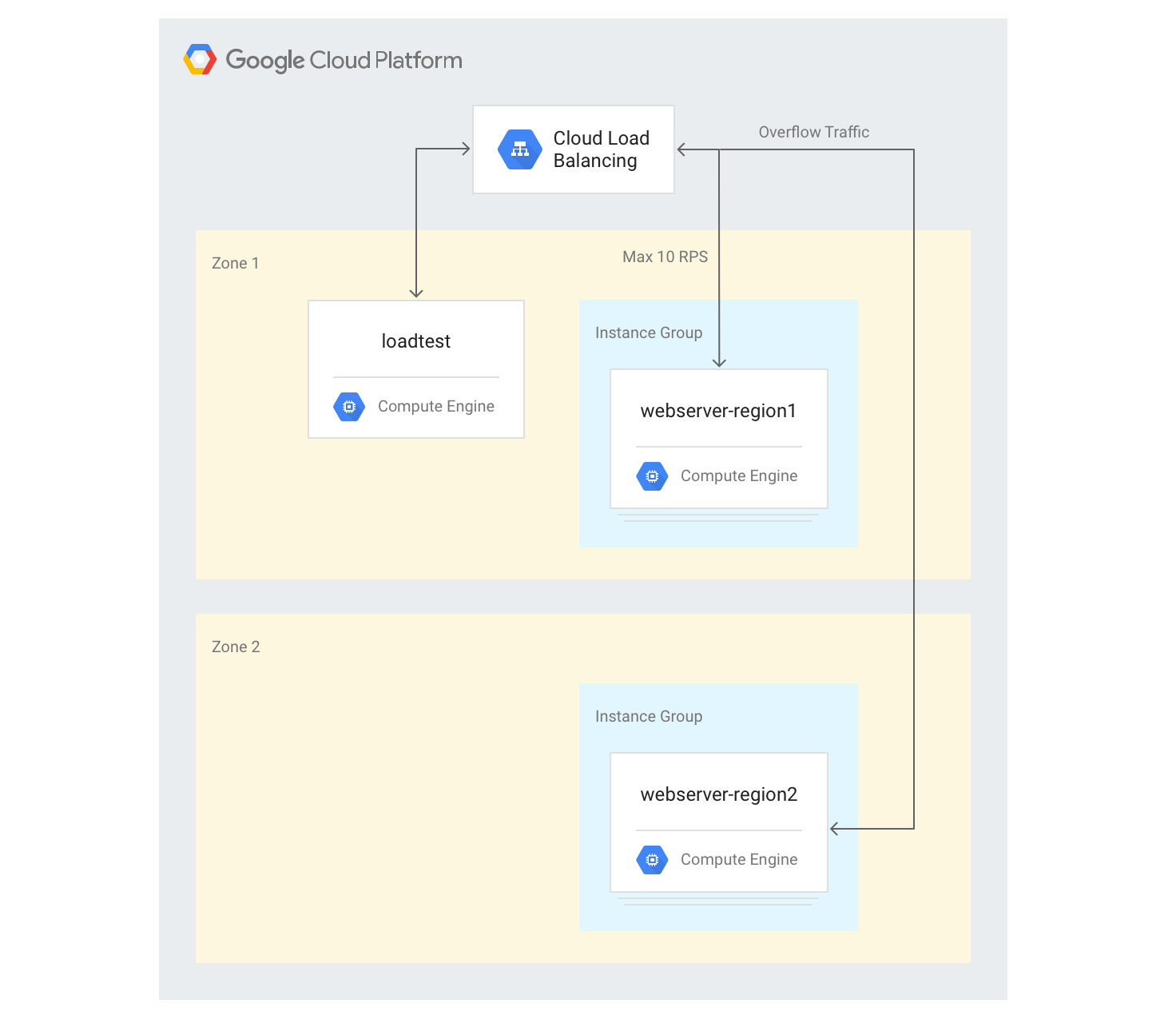
Crear servidores en varias regiones
En los siguientes pasos, añadirá otro grupo de back-ends en otra región y asignará una capacidad de 10 RPS por región. De esta forma, puedes ver cómo reacciona el balanceo de carga cuando se supera este límite.
En Cloud Shell, elige una zona de una región distinta a la predeterminada y defínela como variable de entorno:
export ZONE2=[zone]
Crea un grupo de instancias en la segunda región con 3 instancias de VM:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2Añade el grupo de instancias al servicio de backend con una capacidad máxima de 10 SPS:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10Ajusta el
max-ratea 10 RPS para el servicio de backend actual:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10Una vez que se hayan iniciado todas las instancias, inicia sesión en la instancia de VM
loadtest:gcloud compute ssh loadtest
Ejecuta 500 solicitudes a 10 RPS. Sustituye
[IP_address]por la dirección IP del balanceador de carga:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
Verás resultados como los siguientes:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
Los resultados son similares a los que genera el balanceador de carga regional.
Como la herramienta de prueba ejecuta una carga completa de inmediato y no aumenta la carga lentamente como en una implementación real, tienes que repetir la prueba un par de veces para que el mecanismo de desbordamiento surta efecto. Ejecuta 500 solicitudes 5 veces a 20 SPS. Sustituye
[IP_address]por la dirección IP del balanceador de carga.for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; doneVerás resultados como los siguientes:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
Una vez que el sistema se estabiliza, el tiempo medio de respuesta es de 400 ms a 10 RPS y solo aumenta a 700 ms a 20 RPS. Esto supone una mejora considerable con respecto a la latencia de 5000 ms que ofrece un balanceador de carga regional, lo que se traduce en una experiencia de usuario mucho mejor.
En el siguiente gráfico se muestra el tiempo de respuesta medido por RPS mediante el balanceo de carga global:
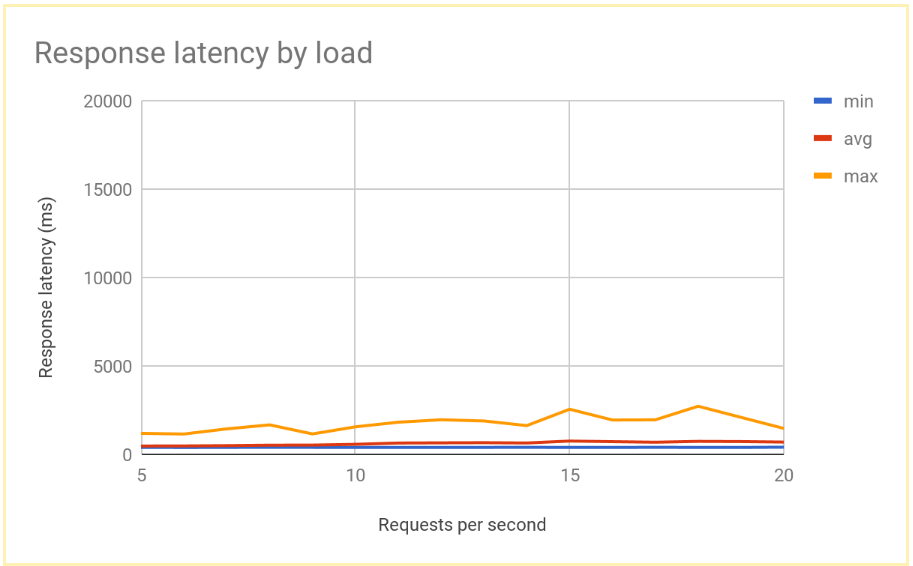
Comparar los resultados del balanceo de carga regional y global
Una vez que hayas determinado la capacidad de un solo nodo, podrás comparar la latencia observada por los usuarios finales en una implementación basada en regiones con la latencia en una arquitectura de balanceo de carga global. Aunque el número de solicitudes en una sola región es inferior a la capacidad de servicio total de esa región, ambos sistemas tienen una latencia similar para el usuario final, ya que los usuarios siempre se redirigen a la región más cercana.
Cuando la carga de una región supera la capacidad de servicio de esa región, la latencia del usuario final difiere significativamente entre las soluciones:
Las soluciones de balanceo de carga regional se sobrecargan cuando el tráfico supera la capacidad, ya que no puede dirigirse a ningún otro sitio que no sean las instancias de VM backend sobrecargadas. Esto incluye los balanceadores de carga locales tradicionales, los balanceadores de carga de red de paso a través externos en Google Cloudy los balanceadores de carga de aplicaciones externos en una configuración de una sola región (por ejemplo, con la red de nivel Estándar). Las latencias medias y máximas de las solicitudes aumentan en más de un factor de 10, lo que provoca malas experiencias de usuario que, a su vez, pueden provocar una pérdida significativa de usuarios.
Los balanceadores de carga de aplicaciones externos globales con backends en varias regiones permiten que el tráfico se desborde a la región más cercana que tenga capacidad de servicio disponible. Esto provoca un aumento medible, pero relativamente bajo, de la latencia del usuario final y proporciona una experiencia de usuario mucho mejor. Si tu aplicación no puede escalar horizontalmente en una región con la suficiente rapidez, te recomendamos que uses el balanceador de carga de aplicación externo global. Incluso durante un fallo en toda una región de los servidores de aplicaciones de los usuarios, el tráfico se redirige rápidamente a otras regiones, lo que ayuda a evitar una interrupción total del servicio.
Limpieza
Eliminar el proyecto
La forma más fácil de evitar que te cobren es eliminar el proyecto que has creado para el tutorial.
Para ello, sigue las instrucciones que aparecen a continuación:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Siguientes pasos
En las siguientes páginas se ofrece más información sobre las opciones de balanceo de carga de Google:
- Optimizar la latencia de las aplicaciones con Cloud Load Balancing
- Codelab de redes para principiantes
- Balanceador de carga de red de paso a través externo
- Balanceador de carga de aplicación externo
- Balanceador de carga de red de proxy externo