Document AI 会生成评估指标(例如精确率和召回率),以帮助您确定处理器的预测性能。
这些评估指标是通过将处理器返回的实体(预测)与测试文档中的注释进行比较生成的。如果您的处理器没有测试集,则必须先创建数据集并标记测试文档。
运行评估
当您训练或增量训练处理器版本时,系统会自动运行评估。
您也可以手动运行评估。如果您修改了测试集,或者要评估预训练的处理器版本,则必须执行此操作才能生成更新后的指标。
网页界面
在 Google Cloud 控制台中,前往处理器页面,然后选择您的处理器。
在评估和测试标签页中,选择要评估的处理器版本,然后点击运行新评估。
完成后,该页面会显示所有标签和每个单独标签的评估指标。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
获取评估结果
网页界面
在 Google Cloud 控制台中,前往处理器页面,然后选择您的处理器。
在评估和测试标签页中,选择要查看评估的处理器版本。
完成后,该页面会显示所有标签和每个单独标签的评估指标。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
列出处理器版本的所有评估
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
所有标签的评估指标
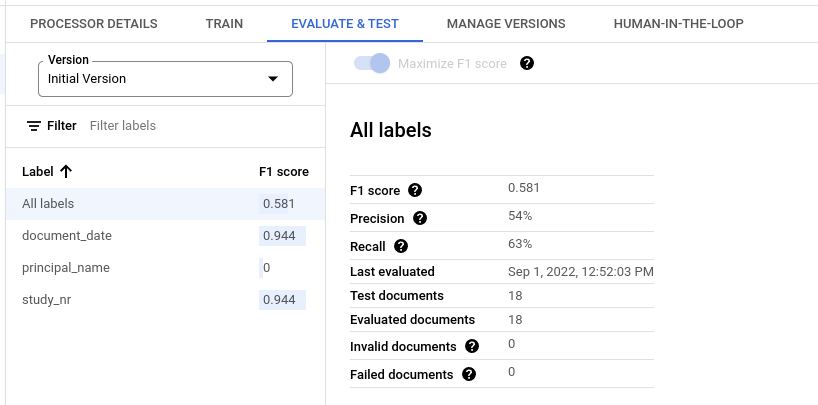
所有标签的指标是根据数据集中所有标签的真正例数、假正例数和假负例数计算得出的,因此会根据每个标签在数据集中出现的次数进行加权。如需了解这些术语的定义,请参阅各个标签的评估指标。
精确率:与测试集中的注释匹配的预测所占的比例。定义为
True Positives / (True Positives + False Positives)召回率:测试集中被正确预测的注释所占的比例。定义为
True Positives / (True Positives + False Negatives)F1 得分:精确率和召回率的调和平均数,可将精确率和召回率合并为一个指标,并为两者赋予相同的权重。定义为
2 * (Precision * Recall) / (Precision + Recall)
各个标签的评估指标
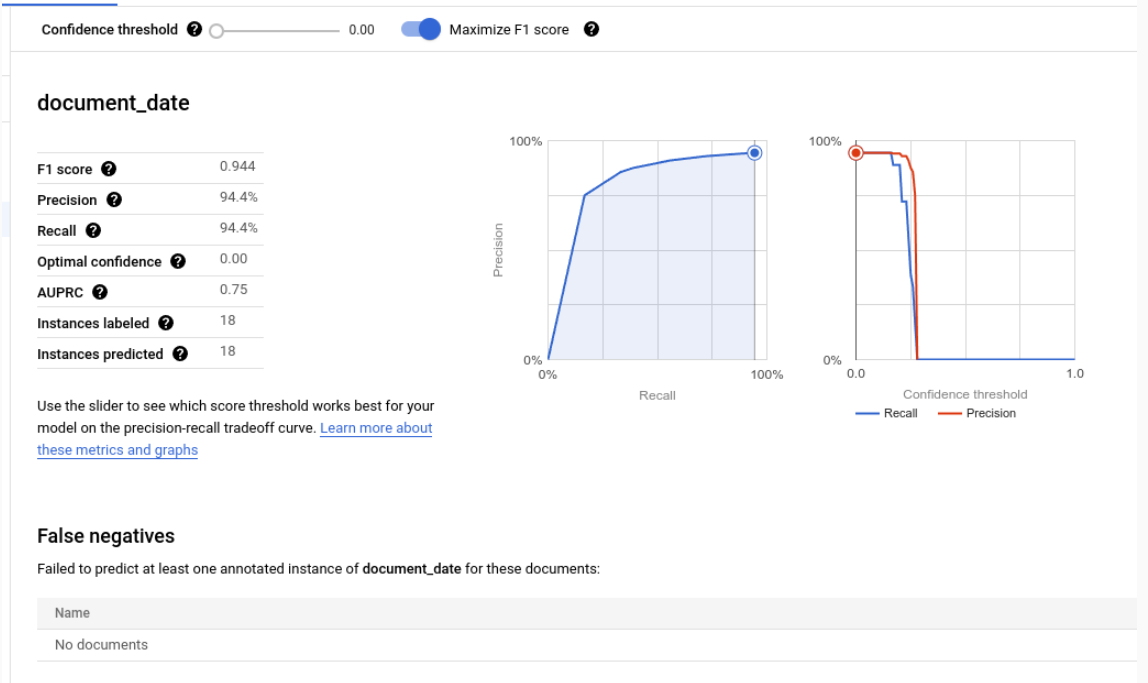
真正例:与测试文档中的注解匹配的预测实体。如需了解详情,请参阅匹配行为。
假正例:与测试文档中的任何注解都不匹配的预测实体。
假负例:测试文档中与任何预测实体都不匹配的注释。
- 假负例(低于阈值):测试文档中本应与预测实体匹配的注释,但预测实体的置信度值低于指定的置信度阈值。
置信度阈值
评估逻辑会忽略置信度低于指定置信度阈值的所有预测,即使预测正确也是如此。Document AI 会提供一份假负例(低于阈值)列表,其中列出了如果降低置信度阈值,本应匹配的注释。
Document AI 会自动计算可最大限度提高 F1 得分的最佳阈值,并默认将置信度阈值设置为此最佳值。
您可以移动滑块来自由选择置信度阈值。 一般来说,置信度阈值越高,就会:
- 精确率更高,因为预测结果更可能是正确的。
- 召回率较低,因为预测较少。
表格实体
父级标签的指标不是通过直接平均子级指标来计算的,而是通过将父级的置信度阈值应用于其所有子级标签并汇总结果来计算的。
父级的最佳阈值是置信度阈值值,当应用于所有子级时,可为父级带来最高的 F1 得分。
匹配行为
如果预测实体满足以下条件,则与注解匹配:
- 预测实体的类型 (
entity.type) 与注解的标签名称一致 - 预测实体的价值(
entity.mention_text或entity.normalized_value.text)与注解的文本值相匹配,但如果启用了模糊匹配,则可能会有出入。
请注意,系统仅使用类型和文本值进行匹配。其他信息(例如文本锚点和边界框,下文所述的表格实体除外)不会使用。
单次出现标签与多次出现标签
即使单个标签值在同一文档中多次注释(例如,账单 ID 出现在同一文档的每个页面中),每个文档也只有一个单次出现标签值(例如,账单 ID)。即使多个注释的文本不同,它们也会被视为相等。换句话说,如果预测的实体与任何注释匹配,则视为匹配。这些额外的注释被视为重复提及,不会计入任何真正例、假正例或假负例的数量。
多次出现的标签可以有多个不同的值。因此,每个预测实体和注解都会单独进行考虑和匹配。如果文档包含针对多次出现标签的 N 个注释,则预测的实体最多可以有 N 个匹配项。每个预测的实体和注解都会单独计为真正例、假正例或假负例。
模糊匹配
借助模糊匹配切换开关,您可以收紧或放宽部分匹配规则,以减少或增加匹配次数。
例如,如果不使用模糊匹配,字符串 ABC 会因大小写而与 abc 不匹配。但通过模糊匹配,它们可以匹配。
启用模糊匹配后,规则会发生以下变化:
空格规范化:移除开头和结尾处的空格,并将中间的连续空格(包括换行符)压缩为单个空格。
移除前导/尾随标点符号:移除以下前导/尾随标点符号字符
!,.:;-"?|。不区分大小写的匹配:将所有字符转换为小写。
货币归一化:对于数据类型为
money的标签,移除开头和结尾的币种符号。
表格实体
父实体和注释没有文本值,而是根据其子级的组合边界框进行匹配。如果只有一个预测父级和一个带注释的父级,则无论边界框如何,系统都会自动匹配它们。
家长匹配成功后,系统会像匹配非表格实体一样匹配其子女。如果找不到匹配的父级,Document AI 将不会尝试匹配其子级。这意味着,即使子实体具有相同的文本内容,如果其父实体不匹配,子实体也可能被视为不正确。
父 / 子实体是一项预览版功能,仅支持具有一层嵌套的表。
导出评估指标
在 Google Cloud 控制台中,前往处理器页面,然后选择您的处理器。
在评估和测试标签页中,点击下载指标,以将评估指标下载为 JSON 文件。