Document AI が生成する適合率や再現率などの評価指標を使用して、プロセッサの予測パフォーマンスを判断します。
これらの評価指標は、プロセッサから返されたエンティティ(予測)とテスト ドキュメント内のアノテーションを比較することで生成されます。プロセッサにテストセットがない場合は、まずデータセットを作成し、テスト ドキュメントにラベルを付ける必要があります。
評価を実行する
プロセッサ バージョンをトレーニングまたはアップトレーニングするたびに、評価が自動的に実行されます。
評価を手動で実行することもできます。これは、テストセットを変更した後に更新された指標を生成する場合や、事前トレーニング済みのプロセッサ バージョンを評価する場合に必要です。
ウェブ UI
Google Cloud コンソールで、[プロセッサ] ページに移動して、プロセッサを選択します。
[評価とテスト] タブで、評価するプロセッサの [バージョン] を選択し、[新しい評価を実行] をクリックします。
完了すると、このページにはすべてのラベルと個々のラベルの評価指標が表示されます。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
評価の結果を取得する
ウェブ UI
Google Cloud コンソールで、[プロセッサ] ページに移動して、プロセッサを選択します。
[評価とテスト] タブで、評価を表示するプロセッサの [バージョン] を選択します。
完了すると、このページにはすべてのラベルと個々のラベルの評価指標が表示されます。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
プロセッサ バージョンのすべての評価を一覧表示する
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
すべてのラベルの評価指標
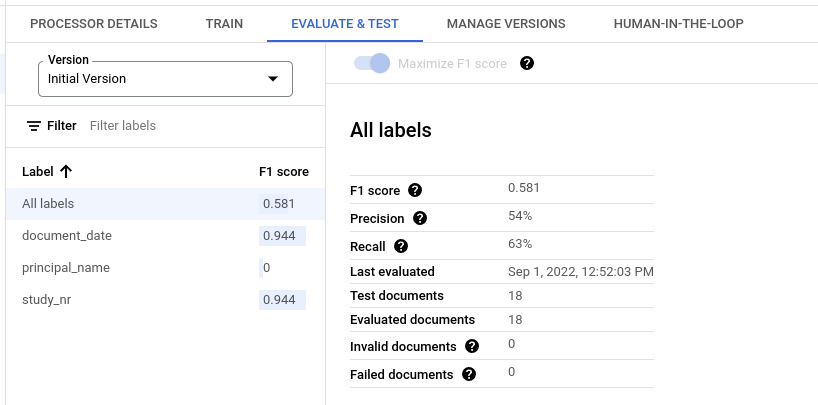
[All labels] の指標は、データセット内のすべてのラベルの真陽性、偽陽性、偽陰性の数に基づいて計算されます。したがって、各ラベルがデータセットに表示される回数で重み付けされます。これらの用語の定義については、個々のラベルの評価指標をご覧ください。
適合率: テストセットのアノテーションと一致する予測の割合。定義:
True Positives / (True Positives + False Positives)再現率: テストセット内のアノテーションのうち、正しく予測されたものの割合。定義:
True Positives / (True Positives + False Negatives)F1 スコア: 適合率と再現率の調和平均。適合率と再現率を 1 つの指標にまとめ、両方に同じ重みを付けます。定義:
2 * (Precision * Recall) / (Precision + Recall)
個々のラベルの評価指標
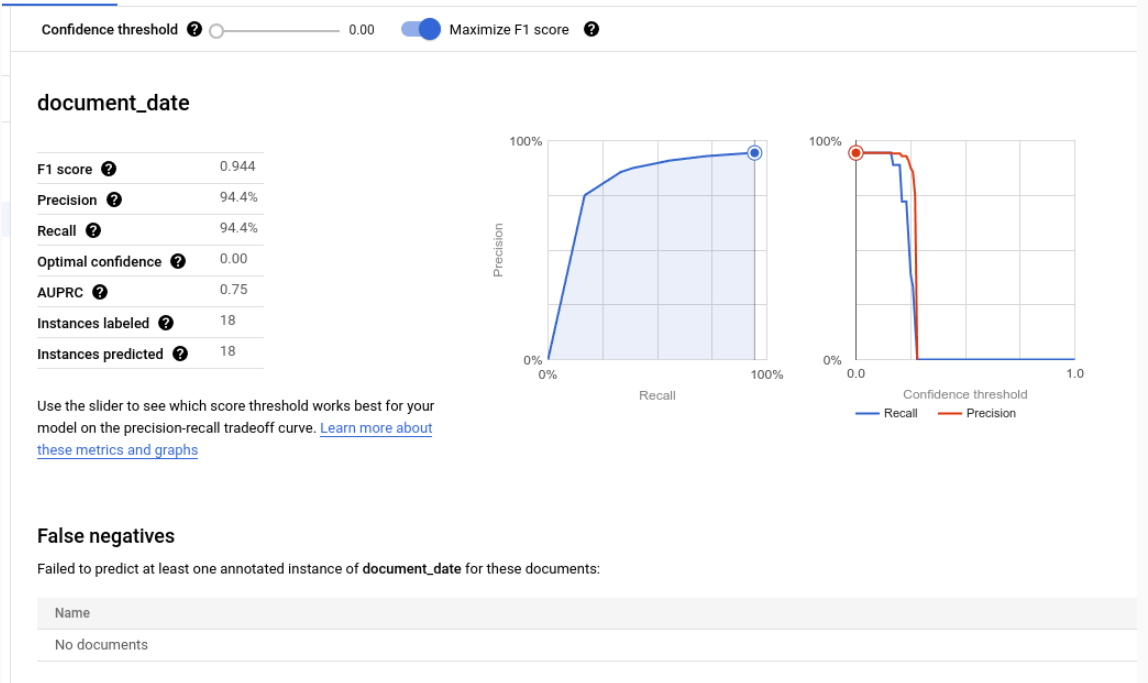
真陽性: テスト ドキュメント内のアノテーションと一致する予測エンティティ。詳細については、一致の動作をご覧ください。
偽陽性: テスト ドキュメント内のアノテーションのいずれとも一致しない予測されたエンティティ。
偽陰性: 予測されたエンティティのいずれとも一致しないテスト ドキュメント内のアノテーション。
- 偽陰性(しきい値未満): 予測されたエンティティと一致するテスト ドキュメント内のアノテーション。ただし、予測されたエンティティの信頼値が指定されたしきい値を下回っています。
信頼度のしきい値
評価ロジックでは、予測が正しくても、指定された信頼度のしきい値を下回る信頼度の予測は無視されます。Document AI は、信頼度のしきい値を低く設定した場合に一致するアノテーションである偽陰性(しきい値未満)のリストを提供します。
Document AI は、F1 スコアを最大化する最適なしきい値を自動的に計算し、デフォルトで信頼度のしきい値をこの最適値に設定します。
スライダーバーを動かして、信頼度のしきい値を自由に選択できます。一般的に、信頼度のしきい値が高いほど、次のようになります。
- 予測が正しくなる可能性が高いため、適合率が高くなります。
- 予測数が少ないため、再現率が低くなります。
表形式のエンティティ
親ラベルの指標は、子指標を直接平均して計算されるのではなく、親の信頼度しきい値がすべての子ラベルに適用され、結果が集計されます。
親の最適なしきい値は、すべての子に適用したときに親の F1 スコアが最大になる信頼度のしきい値です。
一致の動作
予測されたエンティティは、次の条件を満たす場合にアノテーションと一致します。
- 予測されたエンティティのタイプ(
entity.type)がアノテーションのラベル名と一致している - 予測されたエンティティの値(
entity.mention_textまたはentity.normalized_value.text)が、アノテーションのテキスト値と一致する(ファジー一致が有効になっている場合は、その対象となる)。
照合に使用されるのは、型とテキスト値のみです。テキスト アンカーや境界ボックスなどの他の情報(後述の表形式のエンティティを除く)は使用されません。
単一発生ラベルと複数発生ラベル
単一出現ラベルには、同じドキュメント内で値が複数回アノテーションされている場合でも(同じドキュメントのすべてのページに請求書 ID が表示されている場合など)、ドキュメントごとに 1 つの値があります(請求書 ID など)。複数のアノテーションのテキストが異なっていても、それらは同じとみなされます。つまり、予測されたエンティティがアノテーションのいずれかと一致する場合、一致と見なされます。追加のアノテーションは重複するメンションと見なされ、真陽性、偽陽性、偽陰性のいずれのカウントにも影響しません。
複数回出現するラベルには、複数の異なる値を指定できます。したがって、予測された各エンティティとアノテーションは個別に考慮され、照合されます。ドキュメントに複数回出現するラベルのアノテーションが N 個含まれている場合、予測されたエンティティと N 個の一致が存在する可能性があります。予測された各エンティティとアノテーションは、真陽性、偽陽性、偽陰性として個別にカウントされます。
ファジー一致
[ファジー一致] 切り替えを使用すると、一部のマッチング ルールを厳しくしたり緩くしたりして、一致する数を減らしたり増やしたりできます。
たとえば、ファジー一致を使用しない場合、大文字と小文字が異なるため、文字列 ABC は abc と一致しません。しかし、ファジー一致に切り替えると、一致します。
ファジー一致が有効になっている場合、ルールは次のように変更されます。
空白文字の是正: 先頭と末尾の空白を削除し、連続する中間空白(改行を含む)を単一のスペースに圧縮します。
先頭と末尾の句読点の削除: 先頭と末尾の句読点文字(
!,.:;-"?|)を削除します。大文字と小文字を区別しない照合: すべての文字を小文字に変換します。
金額の正規化: データ型が
moneyのラベルの場合、先頭と末尾の通貨記号を削除します。
表形式のエンティティ
親エンティティとアノテーションにはテキスト値がなく、子エンティティの結合されたバウンディング ボックスに基づいて照合されます。予測された親が 1 つで、アノテーション付きの親が 1 つしかない場合、境界ボックスに関係なく、それらは自動的に照合されます。
親が一致すると、その子は表形式以外のエンティティとして一致します。親が一致しない場合、Document AI は子を照合しようとしません。つまり、親エンティティが一致しない場合、テキスト コンテンツが同じでも、子エンティティは正しくないと見なされます。
親エンティティと子エンティティはプレビュー機能であり、1 つのネストレイヤを持つテーブルでのみサポートされています。
評価指標をエクスポートする
Google Cloud コンソールで、[プロセッサ] ページに移動して、プロセッサを選択します。
[評価とテスト] タブで [指標をダウンロード] をクリックして、評価指標を JSON ファイルとしてダウンロードします。