您可以訓練自訂模型並擷取資料,建立專為文件設計的模型,不必使用生成式 AI。如果您不想使用生成式 AI,並想控管訓練模型的各個層面,這就是理想的選擇。
資料集設定
如要訓練、進階訓練或評估處理器版本,必須使用文件資料集。Document AI 處理器會像人類一樣從範例中學習。資料集可提升處理器效能穩定性。訓練資料集
如要提升模型和準確率,請使用文件訓練資料集。模型是由包含真值的檔案組成。至少須有三份文件才能訓練新模型。測試資料集
模型會使用測試資料集產生 F1 分數 (準確率)。這類資料集由含有真值的檔案組成,如要瞭解模型預測正確的頻率,請使用實際資料比較模型的預測結果 (從模型擷取的欄位) 與正確答案。測試資料集至少要有三份文件。事前準備
如果尚未啟用帳單和 Document AI API,請先啟用。
建構及評估自訂模型
首先,請建構自訂處理器,然後進行評估。
設定資料集位置:選取預設選項資料夾「Google-managed」(Google 代管)。 建立處理器後,系統可能會在不久後自動執行這項操作。
前往「Build」(建構) 分頁,然後選取「Import Documents」(匯入文件),並啟用自動加上標籤功能 (請參閱「使用基礎模型自動加上標籤」)。訓練集和測試集中至少需要各 10 份文件,才能訓練自訂模型。
訓練模型:
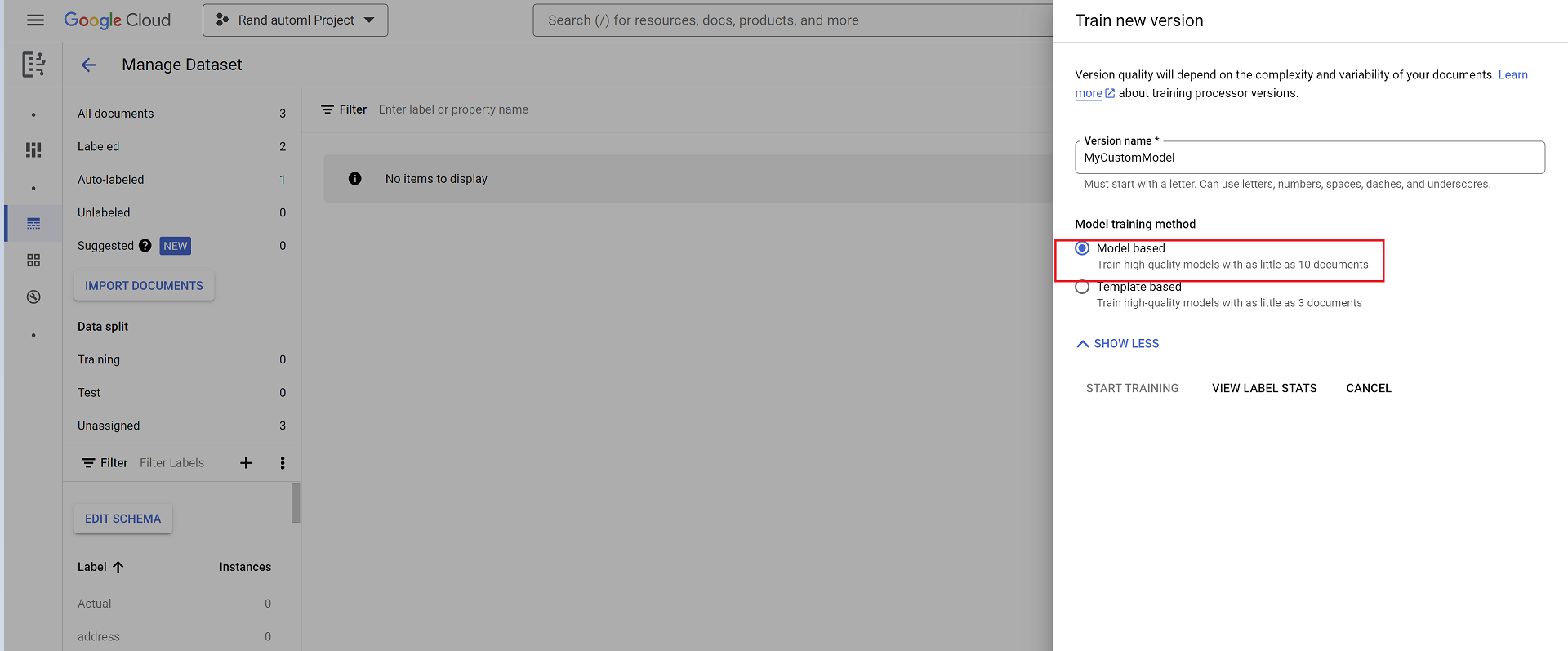
- 選取「訓練新版本」,然後為處理器版本命名。
- 前往「顯示進階選項」,然後選取「以模型為準」選項。
評估:
- 前往「評估與測試」,選取剛訓練的版本,然後選取「查看完整評估」。
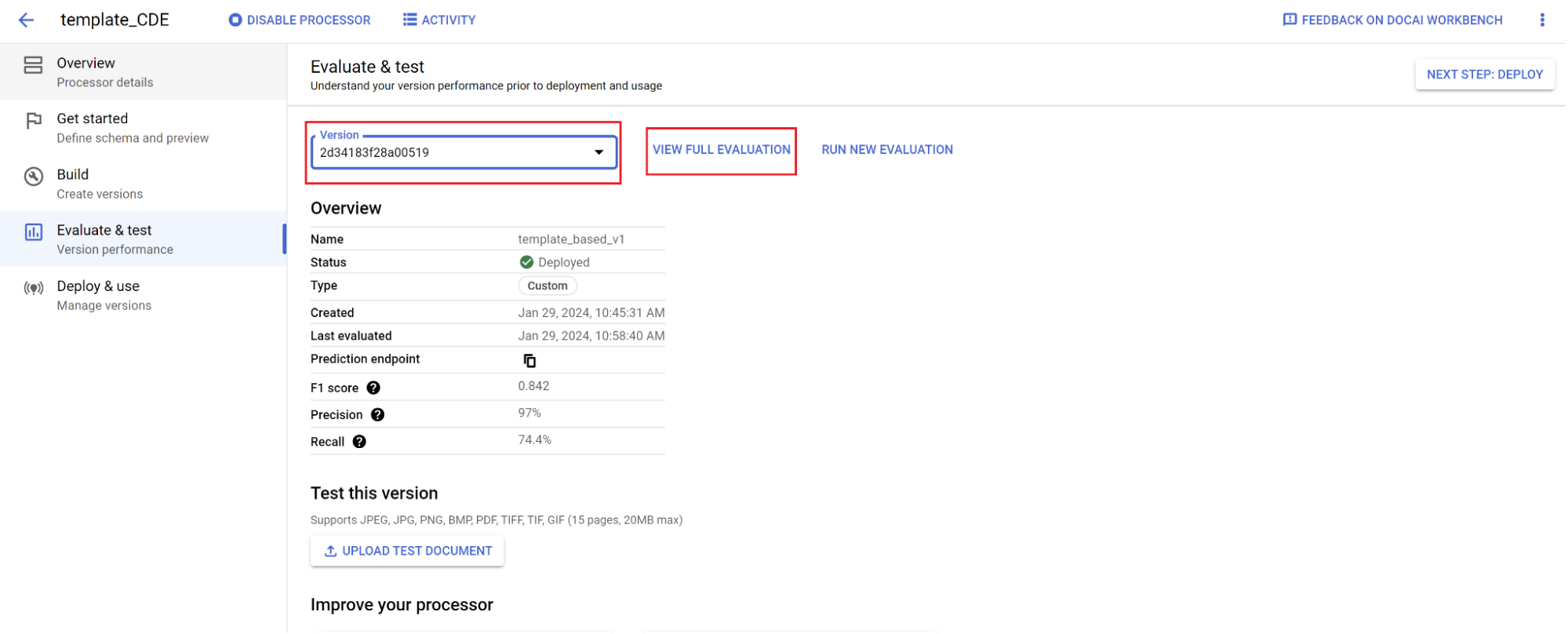
- 現在您會看到整份文件和每個欄位的指標,例如 f1、精確度和召回率。
- 判斷效能是否符合生產目標。如果不符合,請重新評估訓練和測試集,通常是將無法順利剖析的文件新增至訓練測試集。
將新版本設為預設版本。
- 前往「管理版本」。
- 前往 選單,然後選取「設為預設」。
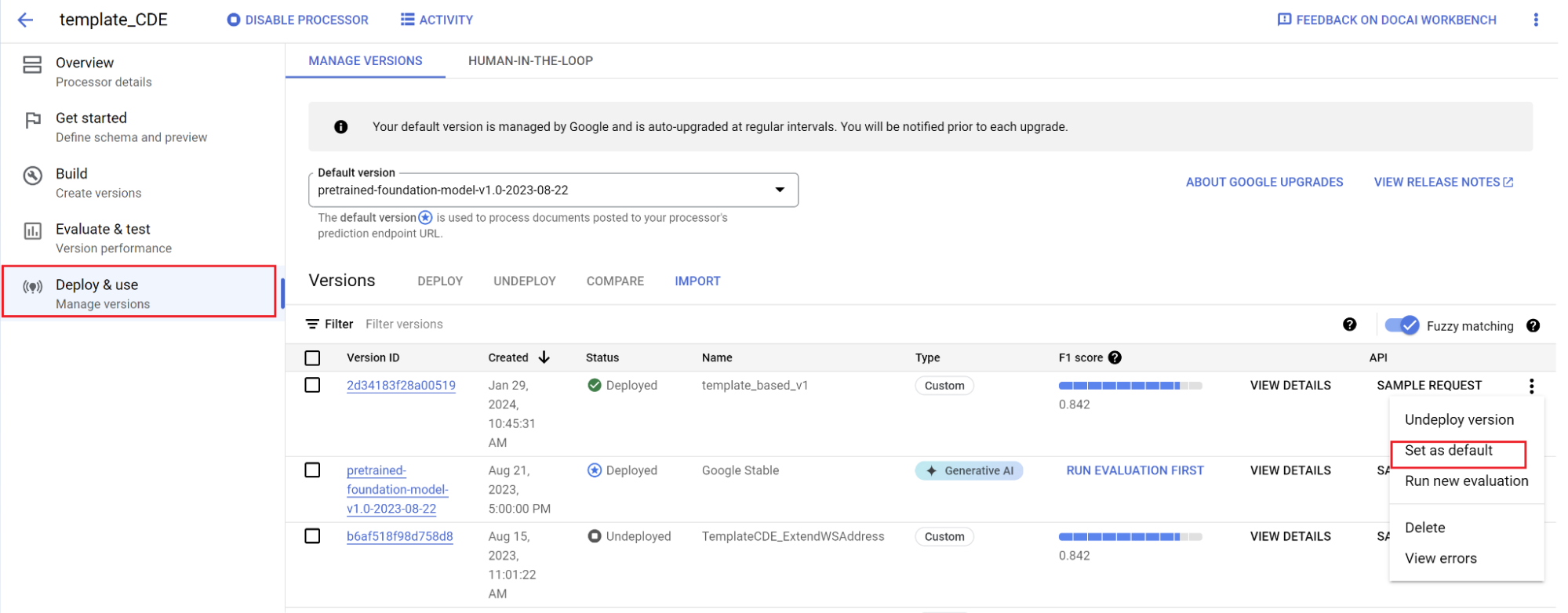
模型已部署完成,傳送至這個處理器的文件現在會使用自訂版本。您想評估模型成效,確認是否需要進一步訓練。
評估參考資料
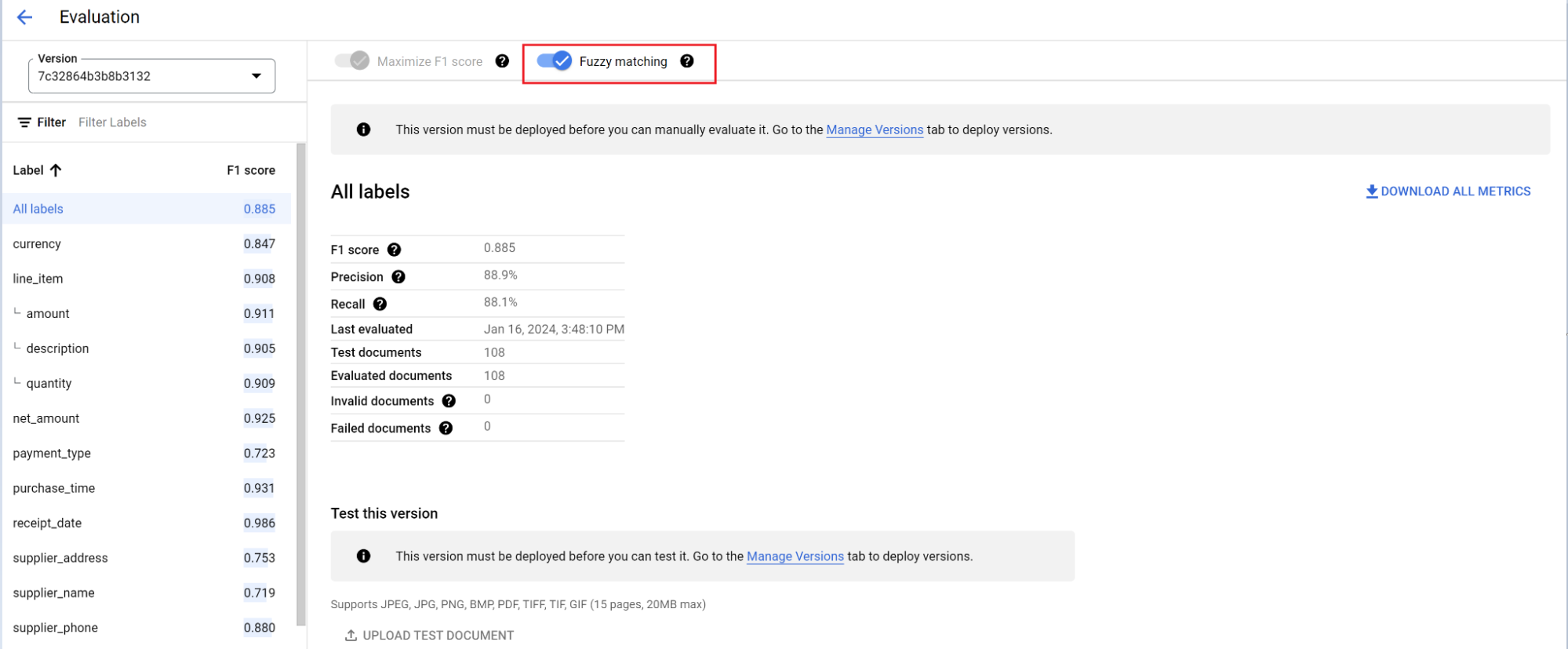
評估引擎可以執行完全比對或模糊比對。 如要完全相符,擷取的值必須與實際資料完全相符,否則會視為不符。
如果擷取的模糊比對結果有微小差異 (例如大小寫不同),仍會視為相符。您可以在「評估」畫面變更這項設定。
使用基礎模型自動加上標籤
基礎模型能精準地擷取各種文件類型的欄位,但您也可以提供其他訓練資料,提高模型處理特定文件結構的準確率。
Document AI 會使用您定義的標籤名稱和先前的註解,透過自動加上標籤功能,為大量文件加上標籤。
- 建立自訂處理器後,請前往「開始使用」分頁。
- 選取「建立新欄位」。
- 提供描述性名稱,並填寫說明欄位。您可以透過屬性說明為每個實體提供額外背景資訊、洞察資料和相關知識,以提升擷取準確度和效能。
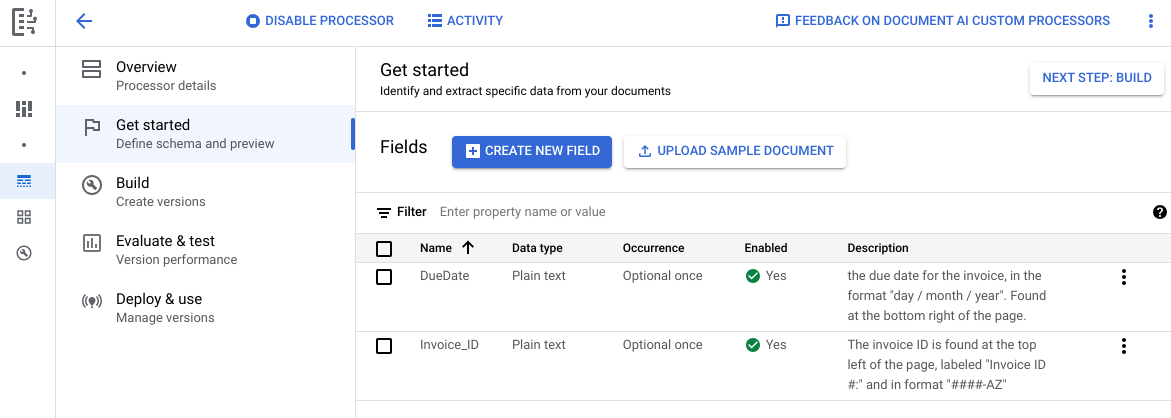
前往「Build」(建構) 分頁,然後選取「Import documents」(匯入文件)。
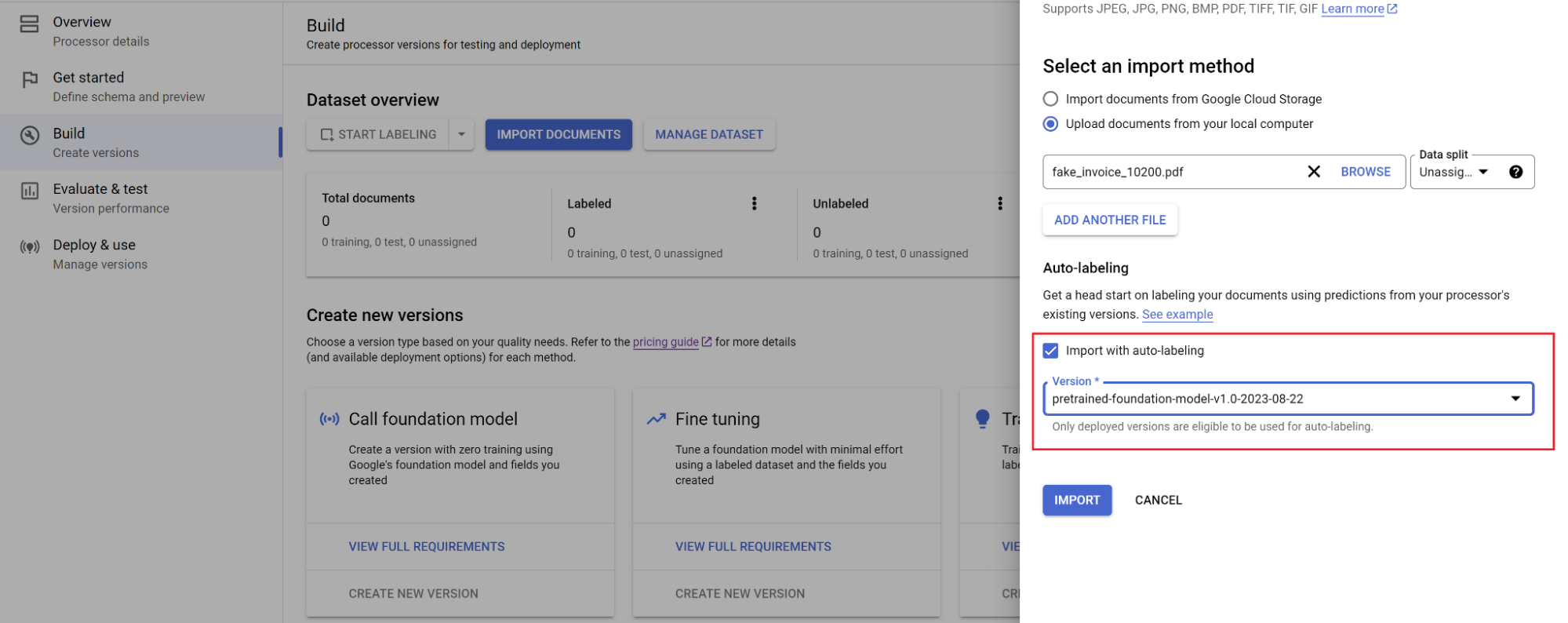
選取文件路徑,以及要將文件匯入哪個集合。勾選自動加上標籤方塊,然後選取基礎模型。
在「Build」(建構) 分頁中,選取「Manage Dataset」(管理資料集)。您應該會看到匯入的文件。選取其中一個文件。
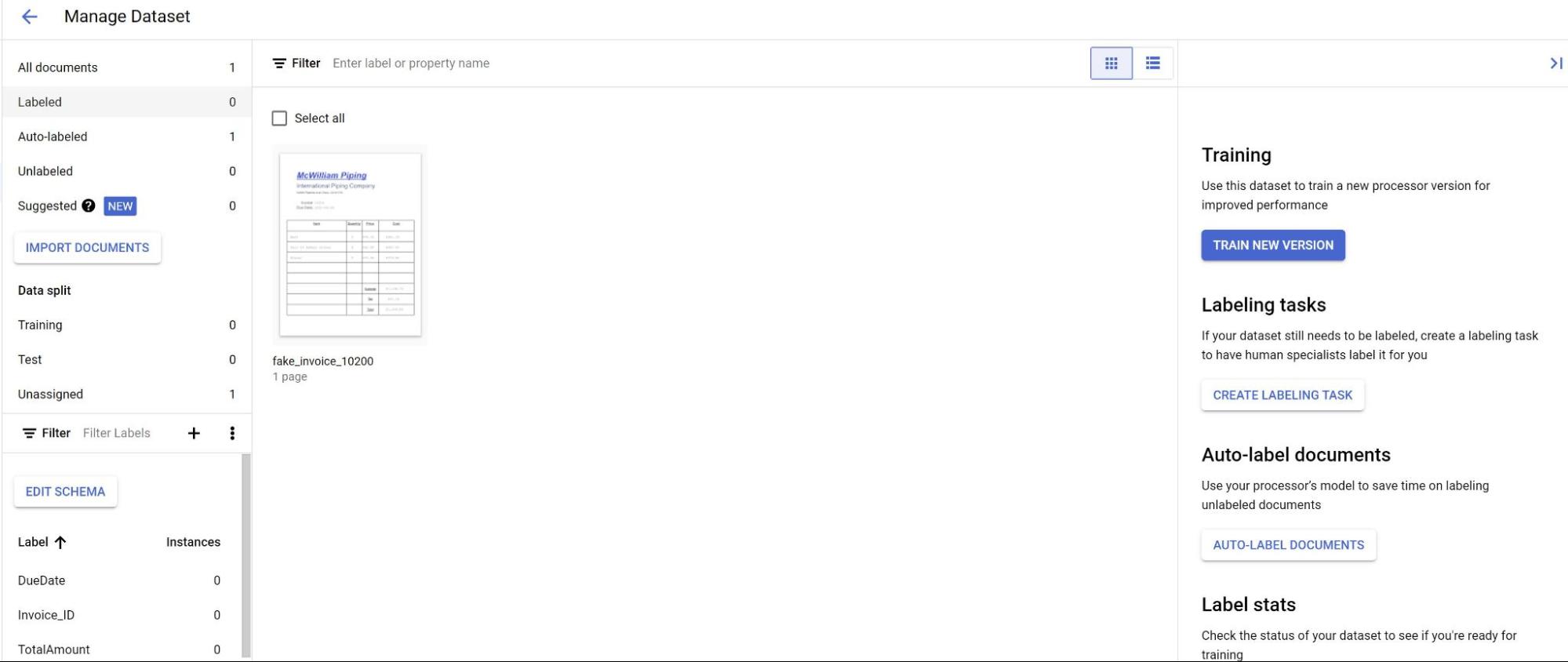
現在,模型預測結果會以紫色醒目顯示。
- 檢查模型預測的每個標籤,確認是否正確。如有缺漏欄位,也請一併新增。
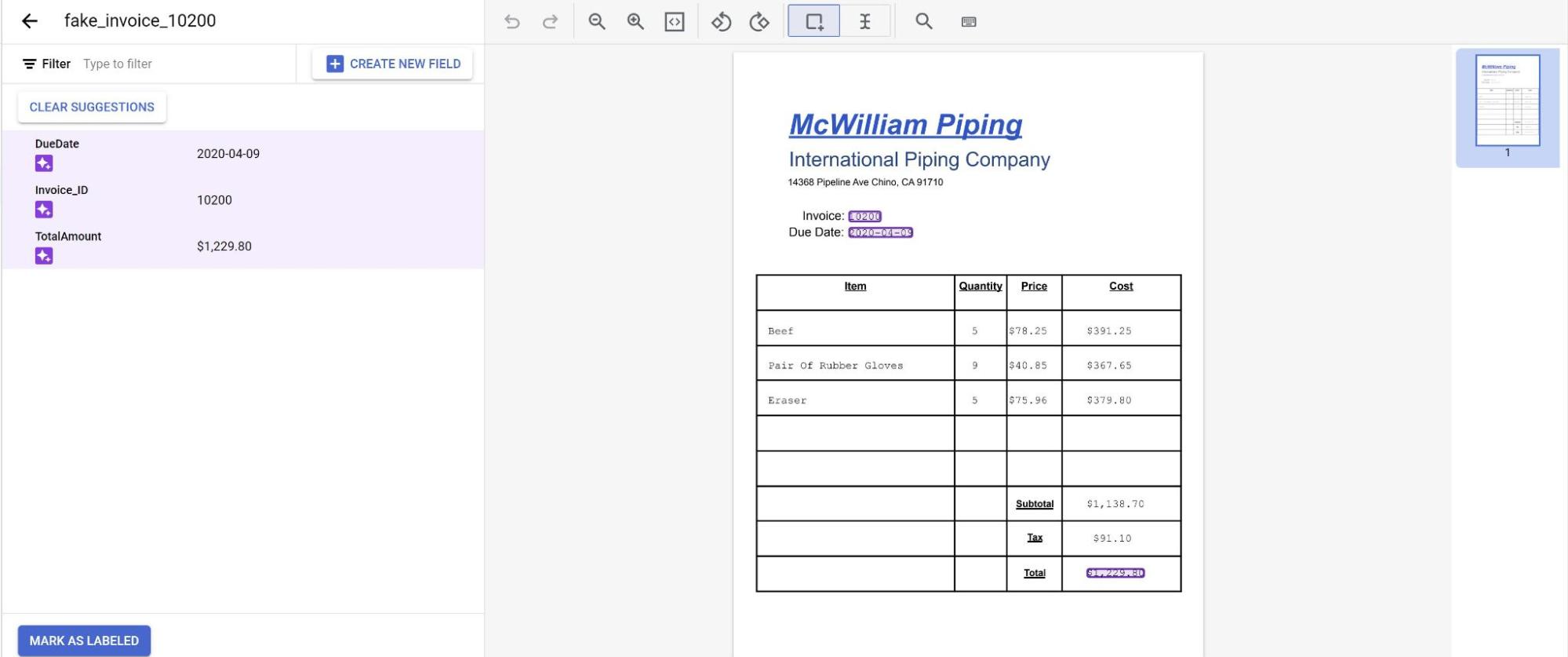
- 審查完文件後,請選取「標示為已加上標籤」。 模型現在可以使用這份文件。確認文件位於測試或訓練集中。