Ce document présente les pipelines de connectivité gérée que vous pouvez utiliser pour importer des métadonnées depuis des sources tierces dans Dataplex Universal Catalog.
La connectivité gérée vous permet d'importer des métadonnées dans Dataplex Universal Catalog à grande échelle. Un pipeline de connectivité gérée extrait les métadonnées de vos sources de données, puis les importe dans Dataplex Universal Catalog. Si nécessaire, le pipeline crée également des groupes d'entrées Dataplex Universal Catalog dans votre projetGoogle Cloud . Vous pouvez orchestrer les workflows et planifier les jobs d'importation selon vos besoins.
Vous créez vos propres connecteurs personnalisés pour extraire les métadonnées de sources tierces. Par exemple, vous pouvez créer un connecteur pour extraire les métadonnées de sources telles que MySQL, SQL Server, Oracle, Snowflake et Databricks, entre autres. Pour découvrir comment créer un exemple de connecteur personnalisé, consultez Développer un connecteur personnalisé pour l'importation de métadonnées. Vous pouvez également utiliser les connecteurs personnalisés issus de la communauté, qui sont disponibles pour diverses sources tierces.
Pour découvrir comment exécuter un pipeline de connectivité gérée, consultez Importer des métadonnées depuis une source personnalisée à l'aide de Workflows.
Fonctionnement de la connectivité gérée
Le diagramme suivant représente un pipeline de connectivité gérée.
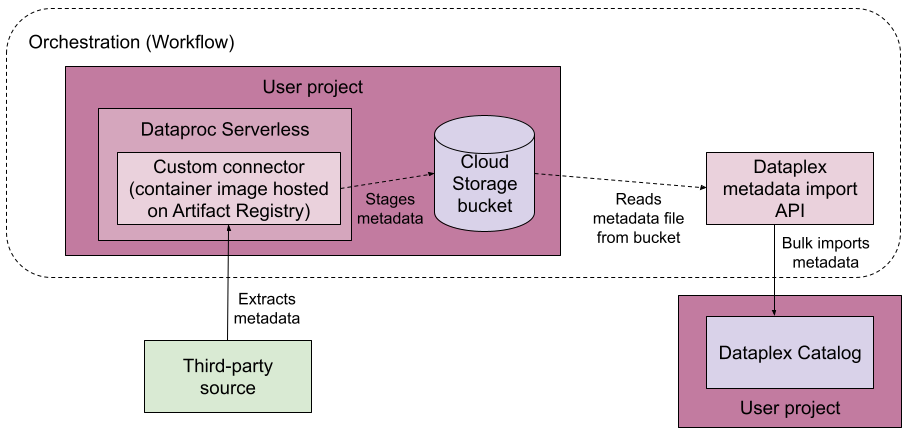
De manière générale, voici comment fonctionne la connectivité gérée :
Vous créez un connecteur pour votre source de données.
Le connecteur doit être une image Artifact Registry pouvant s'exécuter sur Serverless pour Apache Spark.
Vous exécutez le pipeline de connectivité gérée dans Workflows, une plate-forme d'orchestration.
Le pipeline de connectivité gérée effectue les opérations suivantes :
- Il crée un groupe d'entrées cible basé sur votre configuration, si le groupe d'entrées n'existe pas encore.
- Il exécute le connecteur. Le connecteur extrait les métadonnées de votre source de données et génère un fichier d'importation de métadonnées qui peut être importé dans Dataplex Universal Catalog.
- Il surveille la progression de l'extraction des métadonnées.
- Il exécute un job d'importation de métadonnées pour importer les métadonnées dans Dataplex Universal Catalog.
- Il surveille la progression de la tâche d'importation des métadonnées.
Le pipeline de connectivité gérée utilise Google Cloud Serverless pour Apache Spark afin d'exécuter le connecteur, ainsi que les méthodes d'API Dataplex Universal Catalog pour l'importation de métadonnées afin d'exécuter le job d'importation des métadonnées.
Les métadonnées que vous importez se composent d'entrées Dataplex Universal Catalog et de leurs aspects. Pour en savoir plus sur les métadonnées Dataplex Universal Catalog, consultez À propos de la gestion des métadonnées dans Dataplex Universal Catalog.
Connecteurs personnalisés issus de la communauté
Pour importer des métadonnées depuis des sources tierces, vous pouvez utiliser des connecteurs personnalisés issus de la communauté. Consultez le fichier README de chaque connecteur pour obtenir des instructions de configuration et des informations détaillées sur le connecteur.
| Source de données | Dépôt |
|---|---|
| MySQL | mysql-connector |
| Oracle | oracle-connector |
| PostgreSQL | postgresql-connector |
| Snowflake | snowflake-connector |
| SQL Server | sql-server-connector |
Étapes suivantes
- Importer des métadonnées depuis une source personnalisée à l'aide de Workflows
- Développer un connecteur personnalisé pour l'importation de métadonnées
- Importer des métadonnées à l'aide d'un pipeline personnalisé