Mantenha tudo organizado com as coleções
Salve e categorize o conteúdo com base nas suas preferências.
Com as tarefas de qualidade de dados do Catálogo Universal do Dataplex, é possível definir e executar verificações de qualidade de dados em tabelas do BigQuery e do Cloud Storage. Com as tarefas de qualidade de dados do Catálogo Universal do Dataplex, também é possível aplicar controles regulares de dados em ambientes do BigQuery.
Quando criar tarefas de qualidade de dados do Dataplex Universal Catalog
As tarefas de qualidade de dados do Dataplex Universal Catalog podem ajudar você com o seguinte:
Validar os dados como parte de um pipeline de produção de dados.
Monitorar rotineiramente a qualidade dos conjuntos de dados em relação às suas expectativas.
Criar relatórios de qualidade de dados para atender às exigências regulatórias.
Benefícios
Especificações personalizáveis. É possível usar a sintaxe YAML altamente flexível para declarar suas regras de qualidade de dados.
Implementação sem servidor. O Dataplex Universal Catalog não precisa de configuração de infraestrutura.
Copiar sem cópia e pushdown automático. As verificações YAML são convertidas em SQL e enviadas para o BigQuery, sem resultar em cópia de dados.
Verificações de qualidade de dados programáveis. É possível agendar verificações de qualidade de dados
pelo programador sem servidor no Dataplex Universal Catalog ou usar a
API Dataplex por programadores externos, como o Cloud Composer
para integração de pipelines.
Experiência gerenciada. O Dataplex Universal Catalog usa um mecanismo de qualidade de dados de código aberto, o CloudDQ, para executar verificações de qualidade de dados. No entanto, o Dataplex Universal Catalog oferece uma experiência gerenciada perfeita para realizar essas verificações.
Como as tarefas de qualidade de dados funcionam
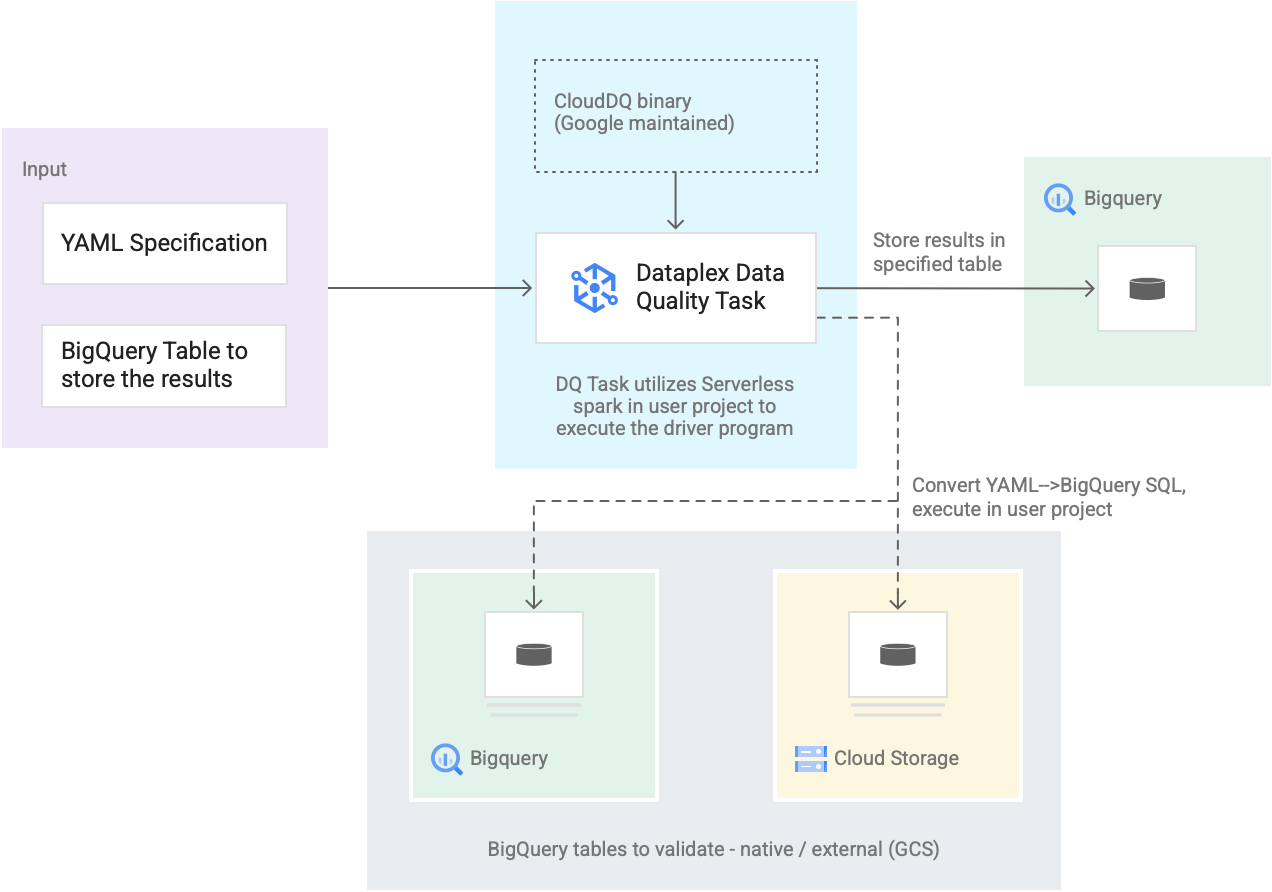
O diagrama a seguir mostra como as tarefas de qualidade de dados do Dataplex Universal Catalog funcionam:
Entrada dos usuários
Especificação YAML: um conjunto de um ou mais arquivos YAML que definem regras de qualidade de dados com base na sintaxe de especificação. Você armazena os arquivos YAML em um
bucket do Cloud Storage no seu projeto. Os usuários podem executar várias regras
simultaneamente, e essas regras podem ser aplicadas a diferentes tabelas do BigQuery, incluindo tabelas em diferentes conjuntos de dados ou projetos do Google Cloud. A especificação aceita execuções incrementais apenas para validar novos dados. Para
criar uma especificação YAML, consulte
Criar um arquivo de especificação.
Tabela de resultados do BigQuery: uma tabela especificada pelo usuário em que os resultados da validação da qualidade de dados são armazenados. O projeto Google Cloud em que essa tabela reside pode ser diferente daquele em que a tarefa de qualidade de dados do Dataplex Universal Catalog é usada.
Tabelas para validação
Na especificação YAML, você precisa especificar quais tabelas quer validar e para quais regras, também conhecido como uma vinculação de regra. Elas podem ser tabelas nativas ou externas do BigQuery no Cloud Storage. Com a especificação YAML, é possível especificar tabelas dentro ou fora de uma zona do Dataplex Universal Catalog.
As tabelas do BigQuery e do Cloud Storage validadas em uma única execução podem pertencer a projetos diferentes.
Tarefa de qualidade de dados do Catálogo Universal do Dataplex: uma tarefa de qualidade de dados do Catálogo Universal do Dataplex é configurada com um binário PySpark do CloudDQ pré-criado e mantido, além de usar a especificação YAML e a tabela de resultados do BigQuery como entrada. Assim como outras tarefas do Catálogo Universal do Dataplex, a tarefa de qualidade de dados do Catálogo Universal do Dataplex é executada em um ambiente sem servidor do Spark, converte a especificação YAML em consultas do BigQuery e executa essas consultas nas tabelas definidas no arquivo de especificação.
Preços
Quando você executa tarefas de qualidade de dados do Catálogo Universal do Dataplex, você é cobrado pelo uso do BigQuery e do Dataproc sem servidor (Batches).
A tarefa de qualidade de dados do Catálogo Universal do Dataplex converte o arquivo de especificação em consultas do BigQuery e as executa no projeto do usuário. Consulte
Preços do BigQuery.
O Dataplex Universal Catalog usa o Spark para executar o programa de driver CloudDQ de código aberto
pré-criado e mantido pelo Google para converter a especificação do usuário em consultas do BigQuery. Consulte Preços do Dataproc sem servidor.
Não há cobranças pelo uso do Dataplex Universal Catalog para organizar dados ou pelo uso do
programador sem servidor no Dataplex Universal Catalog para programar verificações de qualidade de dados. Consulte os preços do Dataplex Universal Catalog.
[[["Fácil de entender","easyToUnderstand","thumb-up"],["Meu problema foi resolvido","solvedMyProblem","thumb-up"],["Outro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Informações incorretas ou exemplo de código","incorrectInformationOrSampleCode","thumb-down"],["Não contém as informações/amostras de que eu preciso","missingTheInformationSamplesINeed","thumb-down"],["Problema na tradução","translationIssue","thumb-down"],["Outro","otherDown","thumb-down"]],["Última atualização 2025-09-05 UTC."],[[["\u003cp\u003eDataplex data quality tasks enable users to define and execute data quality checks on tables in BigQuery and Cloud Storage, also allowing for the implementation of regular data controls in BigQuery environments.\u003c/p\u003e\n"],["\u003cp\u003eThese tasks offer benefits such as customizable rule specifications using YAML syntax, a serverless implementation, zero-copy and automatic pushdown for efficiency, and the ability to schedule checks.\u003c/p\u003e\n"],["\u003cp\u003eThe tasks use a YAML specification to define data quality rules and can validate tables both inside and outside of Dataplex zones, as well as across different projects.\u003c/p\u003e\n"],["\u003cp\u003eUsers can store validation results in a specified BigQuery table, which can be in a different project than the one where the Dataplex task runs.\u003c/p\u003e\n"],["\u003cp\u003eDataplex uses the open source CloudDQ for data quality checks, though users are provided a managed experience, and cost is based on BigQuery and Dataproc Serverless (Batches) usage.\u003c/p\u003e\n"]]],[],null,["# Data quality tasks overview\n\n| **Caution:** Dataplex Universal Catalog data quality tasks is a legacy offering based on open source software. We recommend that you start using the latest built-in [Automatic data quality](/dataplex/docs/auto-data-quality-overview) offering.\n\nDataplex Universal Catalog data quality tasks let you define and run\ndata quality checks across tables in BigQuery and\nCloud Storage. Dataplex Universal Catalog data quality tasks also let you\napply regular data controls in BigQuery environments.\n\nWhen to create Dataplex Universal Catalog data quality tasks\n------------------------------------------------------------\n\nDataplex Universal Catalog data quality tasks can help you with the following:\n\n- Validate data as part of a data production pipeline.\n- Routinely monitor the quality of datasets against your expectations.\n- Build data quality reports for regulatory requirements.\n\nBenefits\n--------\n\n- **Customizable specifications.** You can use the highly flexible YAML syntax to declare your data quality rules.\n- **Serverless implementation.** Dataplex Universal Catalog does not need any infrastructure setup.\n- **Zero-copy and automatic pushdown.** YAML checks are converted to SQL and pushed down to BigQuery, resulting in no data copy.\n- **Schedulable data quality checks.** You can schedule data quality checks through the serverless scheduler in Dataplex Universal Catalog, or use the Dataplex API through external schedulers like Cloud Composer for pipeline integration.\n- **Managed experience.** Dataplex Universal Catalog uses an open source data quality engine, [CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality), to run data quality checks. However, Dataplex Universal Catalog provides a seamless managed experience for performing your data quality checks.\n\nHow data quality tasks work\n---------------------------\n\nThe following diagram shows how Dataplex Universal Catalog data quality tasks work:\n\n- **Input from users**\n - **YAML specification** : A set of one or more YAML files that define data quality rules based on the specification syntax. You store the YAML files in a Cloud Storage bucket in your project. Users can run multiple rules simultaneously, and those rules can be applied to different BigQuery tables, including tables across different datasets or Google Cloud projects. The specification supports incremental runs for only validating new data. To create a YAML specification, see [Create a specification file](/dataplex/docs/check-data-quality#create-a-specification-file).\n - **BigQuery result table**: A user-specified table where the data quality validation results are stored. The Google Cloud project in which this table resides can be a different project than the one in which the Dataplex Universal Catalog data quality task is used.\n- **Tables to validate**\n - Within the YAML specification, you need to specify which tables you want to validate for which rules, also known as a *rule binding*. The tables can be BigQuery native tables or BigQuery external tables in Cloud Storage. The YAML specification lets you specify tables inside or outside a Dataplex Universal Catalog zone.\n - BigQuery and Cloud Storage tables that are validated in a single run can belong to different projects.\n- **Dataplex Universal Catalog data quality task** : A Dataplex Universal Catalog data quality task is configured with a prebuilt, maintained CloudDQ PySpark binary and takes the YAML specification and BigQuery result table as the input. Similar to other [Dataplex Universal Catalog tasks](/dataplex/docs/schedule-custom-spark-tasks), the Dataplex Universal Catalog data quality task runs on a serverless Spark environment, converts the YAML specification to BigQuery queries, and then runs those queries on the tables that are defined in the specification file.\n\nPricing\n-------\n\nWhen you run Dataplex Universal Catalog data quality tasks, you are charged for\nBigQuery and Dataproc Serverless (Batches) usage.\n\n- The Dataplex Universal Catalog data quality task converts the specification file\n to BigQuery queries and runs them in the user project. See\n [BigQuery pricing](/bigquery/pricing).\n\n- Dataplex Universal Catalog uses Spark to run the prebuilt, Google-maintained [open source CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality)\n driver program to convert user specification to BigQuery\n queries. See [Dataproc Serverless pricing](/dataproc-serverless/pricing).\n\nThere are no charges for using Dataplex Universal Catalog to organize data or using the serverless\nscheduler in Dataplex Universal Catalog to schedule data quality checks. See\n[Dataplex Universal Catalog pricing](/dataplex/pricing).\n\nWhat's next\n-----------\n\n- [Create Dataplex Universal Catalog data quality checks](/dataplex/docs/check-data-quality)."]]