Data Catalog is a central inventory of an organization's data assets. Data Catalog automatically catalogs metadata from Google Cloud sources such as BigQuery, Vertex AI, Pub/Sub, Spanner, Bigtable, and more. Data Catalog also indexes table and fileset metadata from Cloud Storage through discovery.
You can discover data with Dataplex Universal Catalog's governed organization-wide metadata search capability. You can further enrich metadata with critical business context, and enable lineage tracking, data profiling, data quality checks, and access control capabilities.
Using Data Catalog, organizations can achieve better data discovery, metadata management, and governance.
Why do you need Data Catalog?
Most organizations deal with a large and growing number of data assets. Data stakeholders (consumers, producers, and administrators) within an organization face multiple challenges, including the following:
Searching for insightful data:
- Data consumers don't know the location and origin of data. They have to navigate data "swamps".
- Data consumers don't know what data to use to get insights because most data isn't well documented and, even if documented, isn't well maintained.
- Data can't be found and is often lost when it resides only in people's minds.
Understanding data:
- Is the data fresh, clean, validated, approved for use in production?
- Which dataset out of several duplicate sets is relevant and up-to-date?
- How does one dataset relate to another?
- Who is using the data and who is the owner?
- Who and what processes are transforming the data?
Making data useful:
Data producers don't have an efficient way to put forward their data for consumers. If there's no self-service, consumers may overwhelm producers. Several data engineers can't manually provide data to thousands of data analysts.
Valuable time is lost if data consumers have to find out how to request data access, wait without a defined response time, escalate, and wait again.
Without the right tools, the challenges become a major obstacle to the efficient use of data. Data Catalog provides a centralized repository that lets organizations achieve the following:
- Gain a unified view to reduce the pain of searching for the right data.
- Support data-driven decision making and accelerate the insight time by enriching data with technical and business metadata.
- Improve data management to increase operational efficiency and productivity.
- Take ownership over the data to improve trust and confidence in it.
Data Catalog functions
Data Catalog provides three main functions:
- Searching for data entries for which you have access
- Tagging data entries with metadata
- Providing column-level security for BigQuery tables
In addition, Data Catalog can build on the results of a Sensitive Data Protection scan to identify sensitive data directly within Data Catalog in the form of tag templates.
How Data Catalog works
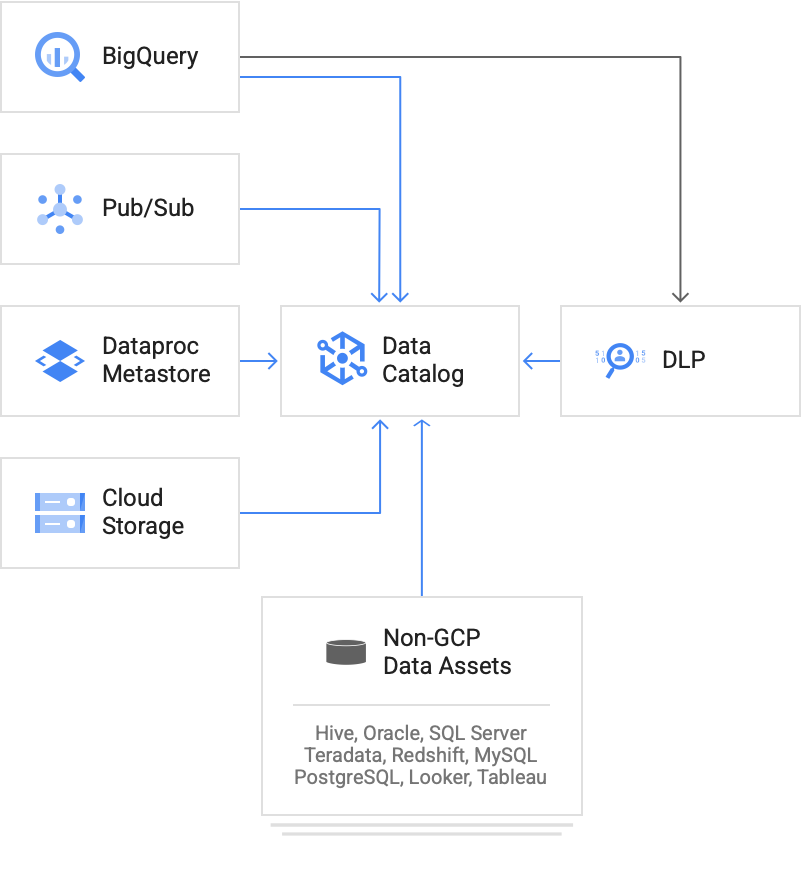
Data Catalog can catalog asset metadata from different Google Cloud systems.
You can also use Data Catalog APIs to integrate with custom data sources.
After your data is cataloged, you can add your own metadata to these assets using tags.
Data Catalog metadata
Data Catalog handles two types of metadata: technical metadata and business metadata. To know more about metadata, see Data Catalog metadata.
Search and discovery
Data Catalog offers a powerful predicate-based search experience for technical and business metadata associated with a data entry. You must have the permissions to read the metadata for a data entry so that you can apply search and discovery on the metadata. Data Catalog does not index the data within a data entry. Data Catalog only indexes the metadata that describes an asset.
Data Catalog controls some metadata such as user-generated tags. For all metadata sourced from the underlying storage system, Data Catalog is a read-only service that reflects the metadata and permissions provided by the underlying storage system. You can make edits in the underlying storage system to add, update, or delete the metadata of a data entry.
To know more about Data Catalog search, see Search for data assets with Data Catalog.
Automatic cataloging of assets
For a given project, Data Catalog automatically catalogs the following Google Cloud assets:
- BigQuery sharing (formerly Analytics Hub) linked datasets
- BigQuery datasets, tables, models, routines, and connections
- Bigtable instances, clusters, and tables (including column family details)
- Dataplex Universal Catalog lakes, zones, tables, and filesets
- Dataproc Metastore services, databases, and tables
- Pub/Sub topics
- Spanner instances, databases, tables, and views
Vertex AI models, datasets, and Vertex AI Feature Store resources
In addition to cataloging assets within the project IDs for which you have metadata access, Data Catalog can catalog data stored in the BigQuery projects that contain public datasets.
Catalog non-Google Cloud assets
To catalog metadata from non-Google Cloud systems in your organization, you can use the following:
- Community-contributed connectors to multiple popular on-premises data sources
- Manually build on the Data Catalog APIs for custom entries
Access Data Catalog
You can access Data Catalog functionalities using:
Dataplex Universal Catalog in the Google Cloud console
gcloudcommand-line interface (CLI)
What's next
Learn how to tag a BigQuery table by using Data Catalog.
Learn how to search data assets with Data Catalog.
Learn how to integrate Google Cloud and on-premises data sources with Data Catalog.