Meridian 版 Cortex
本页详细介绍了 Google Meridian 的数据准备和云自动化流程。适用于 Meridian 的 Cortex Framework 可通过跨媒体和销售数据简化开源营销组合建模 (MMM)。Cortex Framework 通过提供预配置的数据模型并使用 Colab Enterprise 和 Workflows 等 Google Cloud 服务自动执行 Meridian 开源模型,从而简化了这一流程。
Google Cloud Cortex Framework 的主要价值主张之一是为下一代企业智能提供数据和人工智能 (AI) 基础,从而实现跨销售、营销、订单履行和库存管理等关键领域的分析。
Cortex Framework for Marketing 提供跨媒体平台的关键绩效指标 (KPI) 和指标。这些指标是运行 Google 最新开源 MMM 框架 Meridian 的预建模数据准备步骤的重要组成部分。广告客户、代理机构和合作伙伴可以利用 Google Cloud Cortex Framework Data Foundation 加快预建模数据准备流程。
Cortex for Meridian 可高效地从核心 Cortex Framework 数据源(包括以下数据源)收集和转换数据,从而简化模型构建前的流程:
如需了解详情,请参阅 Meridian 文档。
配置文件
在笔记本执行期间,系统会从 Cloud Storage 中 configuration 文件夹内的 cortex_meridian_config.json 文件检索配置参数。
以下部分分享了 Meridian 执行的不同配置 YAML 文件示例:
销售
以销售额作为 KPI 的配置 YAML 文件示例:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
转化次数
将转化作为 KPI 的配置 YAML 文件示例:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
下表介绍了 cortex_meridian_config.json 文件中每个配置形参的值:
| 参数 | 含义 | 默认值 | 说明 |
cortex_bq_project_id
|
包含 Cortex Framework 数据集的项目。 | {PROJECT_ID}
|
Google Cloud 项目 ID。 |
cortex_meridian_marketing_data_set_id
|
包含 Cortex for Meridian 视图的 BigQuery 数据集。 | config.json 文件中 k9.datasets.reporting 的配置值。
|
包含 cortex_meridian_marketing_view_name 视图的数据集。
|
cortex_meridian_marketing_view_name
|
包含 Meridian 营销数据和销售数据的 BigQuery 视图(使用 Cortex)。 | "CrossMediaSalesInsightsWeeklyAgg"
|
包含每周汇总的营销和销售数据。 |
column_mappings.controls
|
可选:可以包含对目标 KPI 和媒体指标都有因果效应的混杂因素。 | []
|
如需详细了解控制变量的 Meridian 数据建模,请参阅控制变量。 |
column_mappings.geo
|
提供地理位置信息的列。 | "geo"
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.kpi
|
模型的目标 KPI。 | "number_of_sales_orders" 或“conversions" ”。
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.media
|
提供渠道展示次数的列数组。 | [
"Tiktok_impression",
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.media_spend
|
提供渠道支出的列。 | [
"Tiktok_spend",
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.population
|
每个地理位置的人口数量。 | "population"
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.revenue_per_kpi
|
每个 KPI 单位的平均收入。 | "average_revenue_per_sales_order" 或 ""
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
column_mappings.time
|
时间列 - 周的开始时间(星期一)。 | "time"
|
如需详细了解 Meridian 数据建模,请参阅收集和整理数据。 |
channel_names
|
频道名称数组。 | [
"TikTok",
|
用于频道 - 索引的名称应与 column_mappings.media 和 column_mappings.media_spend 一致。
|
data_processing.kpi_type
|
KPI 可以是收入,也可以是转化次数等其他非收入 KPI。即使最终的 KPI 是收入,也可以使用非收入 KPI 类型。 | "{USE_CASE_SPECIFIC}"
|
如需了解 KPI 的 Meridian 数据建模详情,请参阅 KPI。 |
data_processing.roi_mu
|
每个媒体渠道的投资回报率 (ROI) 先验分布。roi_mu
(与笔记本中的 ROI_M 一起使用)。
|
{USE_CASE_SPECIFIC}
|
如需详细了解 Meridian 数据处理,请务必阅读并理解:配置模型和 API 参考。 |
data_processing.roi_sigma
|
每个媒体渠道 roi_sigma 的投资回报率 (ROI) 先验分布(与笔记本中的 ROI_M 一起使用)。
|
{USE_CASE_SPECIFIC}
|
如需了解 Meridian 数据处理详情,请务必阅读并理解:配置模型和 API 参考。 |
data_processing.sample.prior
|
从先验分布中抽样的次数。 | {USE_CASE_SPECIFIC}
|
如需了解 Meridian 数据处理的详细信息,请务必阅读并理解:默认先验形参和 API 参考文档。 |
data_processing.sample.posterior.n_chains
|
MCMC 链的数量。 | {USE_CASE_SPECIFIC}
|
如需详细了解 Meridian 数据处理,请务必阅读并理解:配置模型和 API 参考文档 |
data_processing.sample.posterior.n_adapt
|
每条链的自适应抽样次数。 | {USE_CASE_SPECIFIC}
|
如需了解 Meridian 数据处理详情,请务必阅读并理解:配置模型和 API 参考。 |
data_processing.sample.posterior.n_burnin
|
每条链的预选抽样次数。 | {USE_CASE_SPECIFIC}
|
如需了解 Meridian 数据处理详情,请务必阅读并理解:配置模型和 API 参考。 |
data_processing.sample.posterior.n_keep
|
每条链保留的抽样次数,抽取的样本将用于推理。 | {USE_CASE_SPECIFIC}
|
如需了解 Meridian 数据处理详情,请务必阅读并理解:配置模型和 API 参考。 |
与 Meridian 的兼容性
Cortex Framework Data Foundation 和 Meridian 是单独发布的。Cortex Framework 版本说明概述了其版本和版本。在 Meridian 的 GitHub 代码库中,您可以查看最新可用的 Meridian 版本。您可以在 Meridian 的用户指南中查看 Meridian 的前提条件和系统建议。
Cortex Framework Data Foundation 版本会使用特定版本的 Meridian 进行测试。您可以在 Jupyter 笔记本中找到兼容的 Meridian,如下图所示:

如需更新到较新的 Meridian 版本,请修改笔记本中的相应行。请注意,可能需要在笔记本中进行额外的代码调整。
数据模型
本部分使用实体关系图 (ERD) 介绍了 CrossMediaSalesInsightsWeeklyAgg 数据模型。
Cortex for Meridian 依赖于单个视图 CrossMediaSalesInsightsWeeklyAgg 来运行。相应视图的数据源由 k9.Meridian.salesDataSourceType 配置设置决定,该设置可以是:
BYOD(自带数据):自定义数据集成。SAP_SALES:来自 SAP 系统的销售数据。ORACLE_SALES:来自 Oracle EBS 系统的销售数据。
以下部分分享了 CrossMediaForMeridian 的实体关系图:
自带数据 (BYOD)

CortexForMeridian(不含销售数据)。SAP

CortexForMeridian SAP 数据。OracleEBS

CortexForMeridian。下表显示了 CrossMediaSalesInsightsWeeklyAgg 视图(属于 Meridian 的 Cortex)的详细架构:
| 列 | 类型 | 说明 |
| 地理位置 | 字符串 | 用于汇总所有其他值的地理区域。 |
| 时间 | 字符串 | 用于汇总所有其他值的时间维度。 |
| Tiktok_impression | 整数 | 您的广告在 TikTok 上展示的次数。 |
| Meta_impression | 整数 | 您的广告在 Meta 上展示的次数。 |
| YouTube_impression | 整数 | 您的广告在 YouTube 上展示的次数。 |
| GoogleAds_impression | 整数 | 您的广告在 Google Ads 中展示的次数。 |
| Tiktok_spend | 浮点数 | 在 TikTok 上投放广告所花费的金额。 |
| Meta_spend | 浮点数 | 在 Meta 上投放广告所花费的金额。 |
| YouTube_spend | 浮点数 | 在 YouTube 上投放广告所花费的金额。 |
| GoogleAds_spend | 浮点数 | 在 Google Ads 上投放广告所花费的金额。 |
| target_currency | 字符串 | 所有收入列使用的目标币种。 |
| 转化 | 整数 | 转化。 |
| number_of_sales_orders | 整数 | 来自 Oracle EBS 或 SAP 的销售订单数量。 |
| average_revenue_per_sales_order | 浮点数 | 来自 Oracle EBS 或 SAP 的每个销售订单的平均收入。 |
| 人口 | 整数 | 地理位置的人口规模。 |
部署
本页面概述了为 Meridian 部署 Cortex Framework 的步骤,以便在 Google Cloud 环境中实现一流的 MMM。
如需查看快速入门演示,请参阅 Meridian 快速入门演示。
架构
Meridian 版 Cortex 使用 Cortex Framework 将营销和跨媒体数据与销售数据相结合。您可以从 Oracle EBS、SAP 或其他来源系统导入销售数据。
下图描述了 Meridian 版 Cortex 的关键组件:

Meridian 组件和服务
在部署 Cortex Framework Data Foundation(请参阅部署前提条件)期间,您可以在 config.json 文件中将 deployMeridian 设置为 true,以针对 Meridian 启用 Cortex。此选项会启动额外的 Cloud Build 流水线,用于安装 Meridian 所需的以下组件和服务:
BigQuery 视图:在 K9 报告数据集中创建名为
CrossMediaSalesInsightsWeeklyAgg的视图。这样,您就可以通过 Cortex Framework 查询营销数据和销售数据。视图和底层来源的实际实现取决于您在部署期间选择的销售数据源。Cloud Storage 存储桶:
PROJECT_ID-cortex-meridian存储桶包含 Cortex for Meridian 所需的所有工件,以及由 Cortex for Meridian 生成的所有工件,这些工件位于以下文件夹中:configuration:为 Meridian 定义 Cortex 的设置和参数。在笔记本执行期间,Colab Enterprise 笔记本会使用此服务账号。csv:运行 Meridian 后输出的原始数据将保存为 CSV 文件。models:运行 Meridian 后生成的模型将保存在此处。notebook-run-logs:每次执行的笔记本副本和日志将保存在此处。notebooks:包含用于为 Meridian 运行 Cortex 的代码和逻辑的主要笔记本。此笔记本旨在进一步自定义,以支持您的特定需求和要求。reporting:这是保存 Meridian 执行报告的文件夹。还包含一个 HTML 模板,用于生成包含指向 Meridian 报告输出的链接的概览报告。
Colab Enterprise: Colab Enterprise 是一项基于 Google Cloud 的托管式服务,可为使用 Jupyter 笔记本的数据科学和机器学习工作流提供安全且协作的环境。它提供托管式基础设施、企业级安全控制功能以及与其他 Google Cloud 服务的集成等功能,非常适合处理敏感数据并需要强大治理功能的团队。 用于运行 Jupyter 笔记本的托管式环境。
Cortex for Meridian 使用 Colab Enterprise 定义具有所需基础架构的运行时模板,以自动执行 Meridian 运行。

使用工作流触发端到端流水线时,系统会创建一个执行。这会使用最新配置从 Cloud Storage 运行当前 Jupyter 笔记本的副本。

工作流:名为
cortex-meridian-execute-notebook的 Cloud Workflow 可编排整个 Cortex for Meridian 流水线的执行。该工作流将调用 Colab Enterprise API,该 API 会根据运行时模板创建运行时,并使用当前配置执行笔记本运行,最后将所有结果保存到 Cloud Storage 中。
图 8。Meridian 的 Workflows。 您可以为工作流选择以下两种可选配置:
- 如果您能提供新的 Cortex for Meridian JSON 配置作为工作流的输入,如果您这样做,该流程将备份旧配置,并使用您的输入更新配置。如需了解详情,请参阅 REPLACE。
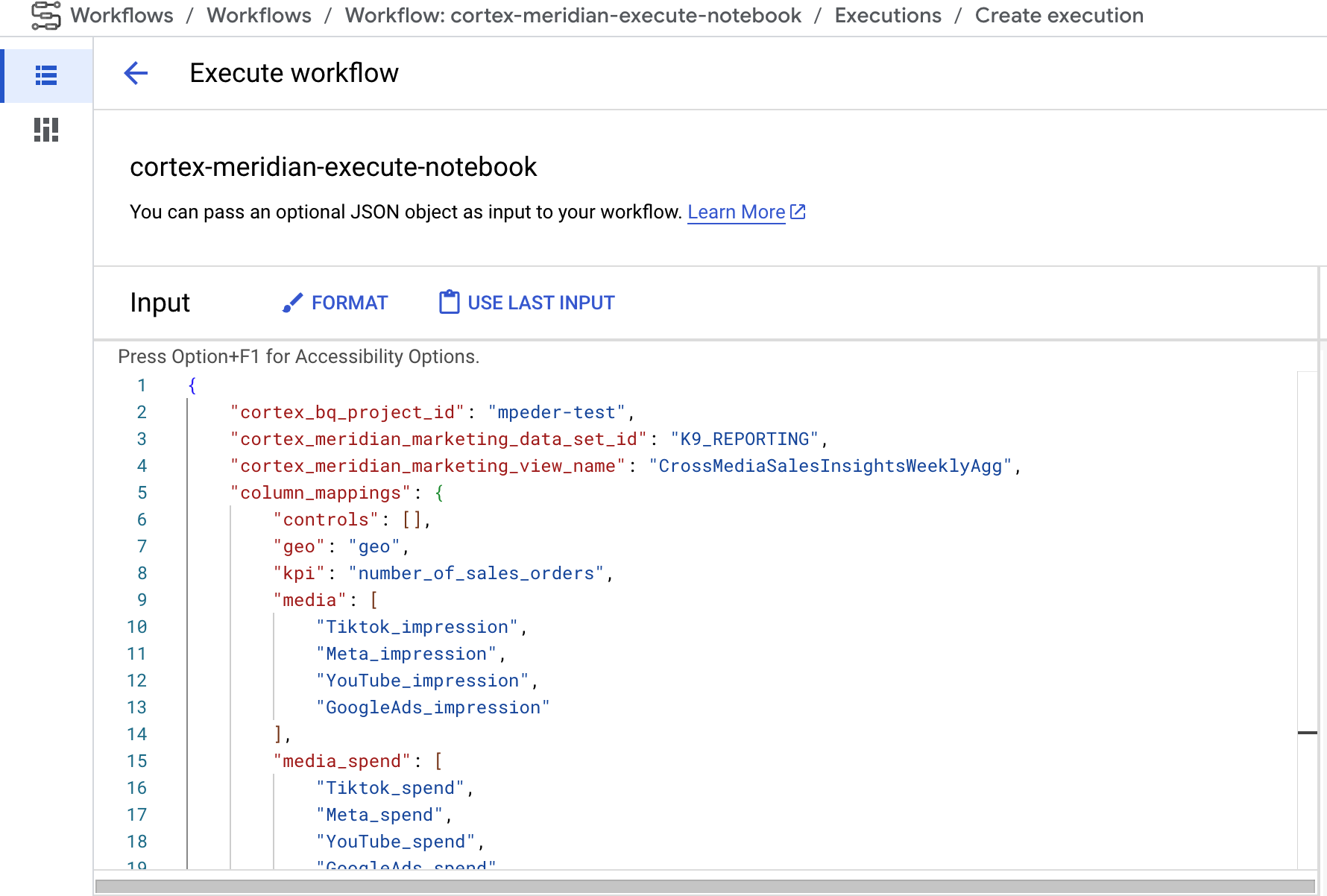
图 9。修改并执行新输入 JSON 的示例。 - 在运行笔记本之前,您可以在
pre_notebook_execution步骤中启动需要自动执行的任何其他任务。例如,从 Google Cloud Cortex Framework 之外的来源加载数据。
服务账号:部署期间必须提供专用服务账号。这是在 Colab Enterprise 中执行工作流和笔记本所必需的。
Meridian 的其他部署参数
config.json 文件用于配置运行 Meridian 和 Cortex Framework 所需的设置。此文件包含以下适用于 Cortex for Meridian 的参数:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
下表介绍了每个 Meridian 参数的值和说明:
| 参数 | 含义 | 默认值 | 说明 |
k9.deployMeridian
|
是否部署 Meridian。 | false
|
选择是否将 Cortex for Meridian 作为数据基础部署的一部分进行部署。 |
k9.Meridian.salesDataSourceType
|
销售数据的来源。 | - | 选择 BYOD、SAP 或 OracleEBS
|
k9.Meridian.salesDatasetID
|
销售数据集的 ID。 | - | 销售数据集的 ID。因相关 Cortex Data Foundation 配置而异。 |
k9.Meridian.deploymentType
|
定义部署是全新部署还是增量部署。 | - | 请在 initial 和 incremental 之间进行选择。
|
k9.Meridian.defaultNotebookFile
|
Jupyter 笔记本文件。 | meridian_cortex_marketing.ipynb
|
位于 Cloud Storage 中 notebooks 文件夹内的笔记本文件的名称。
|
k9.Meridian.defaultConfigFile
|
用于运行笔记本的配置文件。 | cortex_meridian_config.json
|
它包含运行笔记本时使用的 Cortex for Meridian 配置。
它必须位于 Cloud Storage 中的 configuration 文件夹中。
|
k9.Meridian.gcsBucketNameSuffix
|
Cortex for Meridian Cloud Storage 存储桶的后缀。 | cortex-meridian
|
存储桶的全名默认为 {PROJECT_ID}-cortex-meridian。 |
k9.Meridian.workflow.template
|
工作流的模板。 | create_notebook_execution_run.yaml
|
用于创建工作流的模板。该工作流用于启动笔记本执行。 |
k9.Meridian.workflow.name
|
工作流的名称。 | cortex-meridian-execute-notebook
|
工作流在 Google Cloud 门户中显示的名称。 |
k9.Meridian.workflow.region
|
工作流的部署区域。 | us-central1
|
工作流的部署区域。它通常会选择与部署的其余部分相同的区域。 |
k9.Meridian.runnerServiceAccount
|
Meridian 的 Cortex 服务账号的名称。 | cortex-meridian-colab-runner
|
用于运行工作流和 Colab Enterprise 执行的服务账号的名称。 |
k9.Meridian.colabEnterprise.region
|
Colab Enterprise 执行的部署区域。 | us-central1
|
Colab Enterprise 执行的部署区域。它通常会选择与部署的其余部分相同的区域。 |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
企业版 Colab 运行时模板名称。 | cortex-meridian-template
|
企业版 Colab 运行时模板名称。 |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
企业版 Colab 笔记本运行时的机器类型。 | n1-highmem-32
|
企业版 Colab 笔记本运行时的机器类型。 |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
核心数。 | 1
|
企业版 Colab 笔记本的运行时所用的 GPU 加速器核心数。 |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
企业版 Colab 笔记本运行时的加速器类型。 | NVIDIA_TESLA_T4
|
GPU 的类型。 |
k9.Meridian.colabEnterprise.executionName
|
企业版 Colab 笔记本运行时对应的执行名称。 | cortex-meridian-execution
|
将在 Colab Enterprise 的网页界面中显示的名称 - 执行。 |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
运行时执行的文件夹的名称。 | notebook-run-logs
|
Colab 笔记本的执行将在此处存储日志和笔记本的执行副本。 |
工作流
工作流是启动 Cortex for Meridian 执行的主要界面。一个名为 cortex-meridian-execute-notebook 的默认工作流会作为 Cortex for Meridian 的一部分进行部署。
笔记本执行
如需开始执行 Meridian 的新 Cortex,请按以下步骤操作:
- 前往 Workflows 中的
cortex-meridian-execute-notebook笔记本。 - 点击执行以开始新的执行。
- 对于初始运行,请将输入字段留空,以使用存储在 Cloud Storage 中的
cortex_meridian_config.json配置文件中的默认配置。 - 再次点击执行以继续操作。
短暂延迟后,系统会显示工作流执行状态:

图 10. 执行详细信息示例。 在 Colab Enterprise 中跟踪笔记本执行进度。
工作流程步骤
cortex-meridian-execute-notebook 工作流包含以下步骤:
| 步骤 | 子步骤 | 说明 |
init
|
-
|
初始化参数。 |
checkInputForConfig
|
-
|
检查是否提供了新的配置 JSON 作为工作流输入。 |
logBackupConfigFileName
|
记录备份配置文件名。 | |
backupConfigFile
|
在 Cloud Storage 上备份配置文件。 | |
logBackupResult
|
记录 Cloud Storage API 调用的结果。 | |
updateGCSConfigFile
|
使用新值更新 Cloud Storage 中的配置文件。 | |
pre_notebook_execution
|
-
|
此步骤默认情况下为空。您可以根据需要进行自定义。 例如,在运行笔记本之前加载数据或其他相关步骤。如需了解详情,请参阅 Workflows 概览和 Workflows 连接器。 |
create_notebook_execution_run
|
-
|
创建 Colab Enterprise 笔记本执行(通过 Cloud Build 中的 shell 脚本)。 |
notebook_execution_run_started
|
-
|
输出补全结果。 |
自定义 Meridian 执行工作流
您可以在 Workflows 输入字段中提供自己的配置 JSON 文件,以自定义 Meridian 执行:
- 将修改后的配置的完整 JSON 输入到输入字段中。
- 然后,工作流将:
- 将 Cloud Storage 中的现有
cortex_meridian_config.json文件替换为提供的 JSON。 - 在
Cloud Storage/configuration目录中创建原始配置文件的备份。 - 备份文件名将采用
cortex_meridian_config_workflow_backup_workflow_execution_id.json格式,其中 workflow_execution_id 是当前工作流执行的唯一标识符(例如cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json)
- 将 Cloud Storage 中的现有
Jupyter 笔记本概览
将输入数据加载到 Meridian 模型以运行和执行该模型的核心功能由 Python 笔记本 meridian_cortex_marketing.ipynb 处理,该笔记本位于 Cloud Storage 存储桶的 notebooks 文件夹中。
笔记本的执行流程包括以下步骤:
- 安装必要的软件包(包括 Meridian),并导入所需的库。
- 加载用于与 Cloud Storage 和 BigQuery 交互的辅助函数。
- 从 Cloud Storage 中的
configuration/cortex_meridian_config.json文件检索执行配置。 - 从 BigQuery 中的 Cortex Framework Data Foundation 视图加载 Cortex Framework 数据。
- 配置 Meridian 模型规范,并将营销和销售的 Cortex Framework Data Foundation 数据模型映射到 Meridian 模型输入架构。
- 执行 Meridian 抽样并生成摘要报告,保存到 Cloud Storage (
/reporting)。 - 针对默认方案运行预算优化器,并将总结报告输出到 Cloud Storage (
/reporting)。 - 将模型保存到 Cloud Storage (
/models)。 - 将 CSV 结果保存到 Cloud Storage (
/csv)。 - 生成概览报告并将其保存到 Cloud Storage (
/reporting)。
导入笔记本以进行手动执行和编辑
如需自定义或手动执行笔记本,请从 Cloud Storage 导入笔记本:
- 前往 Colab Enterprise。
- 点击我的笔记本。
- 点击导入。
- 选择 Cloud Storage 作为导入来源,然后从 Cloud Storage 中选择笔记本。
- 点击导入。
笔记本随即会加载并打开。
笔记本执行结果
如需查看笔记本运行结果,请打开包含所有单元格输出的完整笔记本副本:
- 前往 Colab Enterprise 中的执行。
- 从下拉菜单中选择相关区域。
- 在要查看结果的笔记本运行旁边,点击查看结果。
- Colab Enterprise 会在新标签页中打开笔记本运行结果。
- 如需查看结果,请点击新标签页。
运行时模板
Google Cloud Colab Enterprise 使用运行时模板来定义预配置的执行环境。Cortex for Meridian 部署包含一个预定义的运行时模板,适合运行 Meridian Notebook。此模板会自动用于为笔记本执行创建运行时环境。
如有需要,您可以手动创建其他运行时模板。