Cortex para Meridian
En esta página, se detalla el proceso de preparación de datos y automatización en la nube para Google Meridian. Cortex Framework para Meridian optimiza el modelado de combinación de marketing (MMM) de código abierto con datos de ventas y de medios múltiples. Cortex Framework simplifica este proceso, ya que proporciona modelos de datos preconfigurados y automatiza la ejecución del modelo de código abierto de Meridian con servicios de Google Cloud como Colab Enterprise y Workflows.
Una de las principales propuestas de valor de Google Cloud Cortex Framework es proporcionar una base de datos y de inteligencia artificial (IA) para la inteligencia empresarial de próxima generación que permita el análisis en áreas clave, como ventas, marketing, cumplimiento de pedidos y administración de inventario.
Cortex Framework para marketing proporciona indicadores clave de rendimiento (KPI) y métricas en todas las plataformas de medios. Estas métricas son una parte importante del paso de preparación de los datos previos al modelado para ejecutar el MMM de código abierto más reciente de Google, llamado Meridian. Los anunciantes, las agencias y los socios pueden acelerar el proceso de preparación de datos previo al modelado aprovechando la base de datos de Cortex Framework de Google Cloud.
Cortex para Meridian simplifica el proceso previo al modelado, ya que recopila y transforma de manera eficiente los datos de las fuentes de datos principales de Cortex Framework, incluidas las siguientes:
Para obtener más información, consulta la documentación de Meridian.
Archivo de configuración
Durante la ejecución del notebook, el sistema recupera los parámetros de configuración del archivo cortex_meridian_config.json ubicado en la carpeta configuration dentro de Cloud Storage.
En la siguiente sección, se comparten diferentes ejemplos de archivos YAML de configuración para la ejecución de Meridian:
Ventas
Ejemplo de archivo de configuración YAML para las ventas como KPI:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
Conversiones
Ejemplos de archivos de configuración YAML para las conversiones como KPI:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
En la siguiente tabla, se describe el valor de cada parámetro de configuración del archivo cortex_meridian_config.json:
| Parámetro | Significado | Valor predeterminado | Descripción |
cortex_bq_project_id
|
Es el proyecto que contiene los conjuntos de datos de Cortex Framework. | {PROJECT_ID}
|
ID del proyecto Google Cloud |
cortex_meridian_marketing_data_set_id
|
Es el conjunto de datos de BigQuery con Cortex para la vista de Meridian. | El valor de configuración de k9.datasets.reporting en el archivo config.json.
|
Es el conjunto de datos que contiene la vista cortex_meridian_marketing_view_name.
|
cortex_meridian_marketing_view_name
|
Vista de BigQuery con Cortex para los datos de marketing y ventas de Meridian. | "CrossMediaSalesInsightsWeeklyAgg"
|
Es la vista que contiene datos agregados semanales de marketing y ventas. |
column_mappings.controls
|
Opcional: Puede contener los factores de confusión que tienen un efecto causal tanto en el KPI objetivo como en la métrica de medios. | []
|
Para obtener detalles sobre el modelado de datos de Meridian en relación con las variables de control, consulta Variables de control. |
column_mappings.geo
|
Son las columnas que proporcionan información geográfica. | "geo"
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.kpi
|
Es el KPI objetivo del modelo. | "number_of_sales_orders" o "conversions" .
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.media
|
Es un array de columnas que proporciona las impresiones del canal. | [
"Tiktok_impression",
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.media_spend
|
Son las columnas que proporcionan la inversión del canal. | [
"Tiktok_spend",
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.population
|
Es la población de cada ubicación geográfica. | "population"
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.revenue_per_kpi
|
Son los ingresos promedio de una unidad de KPI. | "average_revenue_per_sales_order" o ""
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
column_mappings.time
|
La columna de tiempo: Comienzo de la semana (lunes). | "time"
|
Para obtener detalles sobre el modelado de datos de Meridian, consulta Cómo recopilar y organizar tus datos. |
channel_names
|
Es un array de nombres de canales. | [
"TikTok",
|
Los nombres que se usan para el canal y el índice deben coincidir con column_mappings.media y column_mappings.media_spend.
|
data_processing.kpi_type
|
El KPI pueden ser los ingresos o algún otro KPI diferente. También se puede usar un tipo de KPI que no sean los ingresos, incluso cuando los ingresos sean, en última instancia, el KPI. | "{USE_CASE_SPECIFIC}"
|
Para obtener detalles sobre el modelado de datos de Meridian para el KPI, consulta KPI. |
data_processing.roi_mu
|
Es la distribución a priori del ROI de cada canal de medios. roi_mu
(se usa con ROI_M en el notebook).
|
{USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender los siguientes recursos: Configura el modelo y la referencia de la API. |
data_processing.roi_sigma
|
Es la distribución a priori del ROI de cada canal de medios roi_sigma (se usa con ROI_M en el notebook).
|
{USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender Configura el modelo y la referencia de la API. |
data_processing.sample.prior
|
Cantidad de muestras extraídas de la distribución a priori. | {USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender los parámetros de la distribución a priori predeterminada y la referencia de la API. |
data_processing.sample.posterior.n_chains
|
Cantidad de cadenas de MCMC. | {USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender los siguientes recursos: Configura el modelo y Referencia de la API |
data_processing.sample.posterior.n_adapt
|
Cantidad de extracciones de adaptación por cadena. | {USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender los siguientes recursos: Configura el modelo y Referencia de la API. |
data_processing.sample.posterior.n_burnin
|
Cantidad de extracciones iniciales por cadena. | {USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender Configura el modelo y la referencia de la API. |
data_processing.sample.posterior.n_keep
|
Cantidad de extracciones por cadena que se deben conservar para la inferencia. | {USE_CASE_SPECIFIC}
|
Para obtener detalles sobre el procesamiento de datos de Meridian, asegúrate de leer y comprender Configura el modelo y la referencia de la API. |
Compatibilidad con Meridian
Cortex Framework Data Foundation y Meridian se lanzan por separado. Las notas de la versión de Cortex Framework proporcionan una descripción general de sus versiones. En el repositorio de GitHub de Meridian, puedes ver las versiones más recientes disponibles de Meridian. Los requisitos previos y las recomendaciones del sistema de Meridian están disponibles en la guía del usuario de Meridian.
Las versiones de Cortex Framework Data Foundation se prueban con una versión específica de Meridian. Puedes encontrar el Meridian compatible en el notebook de Jupyter, como se muestra en la siguiente imagen:

Para actualizar a una versión más reciente de Meridian, modifica la línea correspondiente en el notebook. Ten en cuenta que es posible que se requieran ajustes de código adicionales en el notebook.
Modelo de datos
En esta sección, se describe el modelo de datos de CrossMediaSalesInsightsWeeklyAgg con el diagrama de relación entre entidades (ERD).
Cortex para Meridian se basa en una sola vista, CrossMediaSalesInsightsWeeklyAgg, para funcionar. La fuente de datos de esta vista se determina según el parámetro de configuración k9.Meridian.salesDataSourceType, que puede ser uno de los siguientes:
BYOD(Aporta tus propios datos): Integración de datos personalizados.SAP_SALES: Son los datos de ventas de los sistemas SAP.ORACLE_SALES: Son los datos de ventas de los sistemas de Oracle EBS.
En la siguiente sección, se comparten los diagramas de relación entre entidades para CrossMediaForMeridian:
BYOD
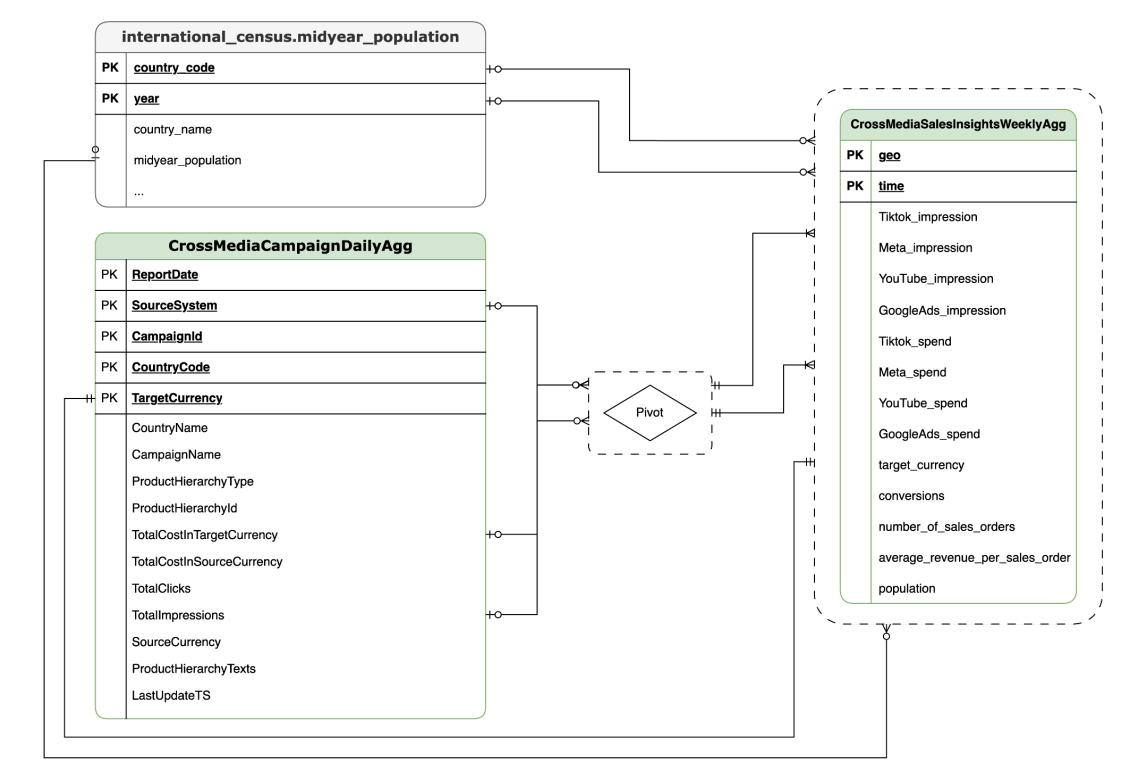
CortexForMeridian sin datos de ventas.SAP
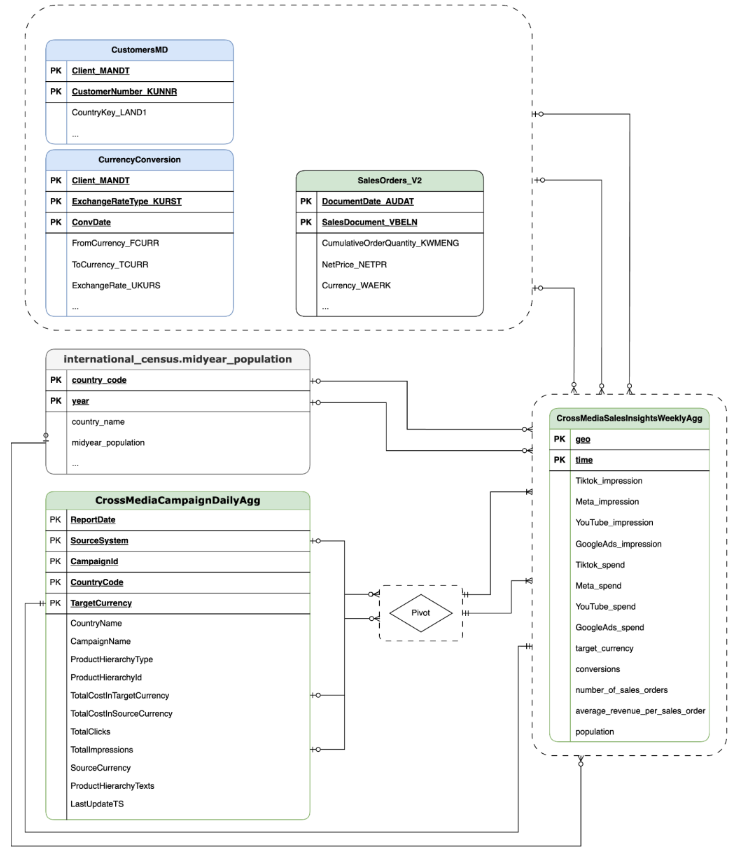
CortexForMeridian con datos de SAP.OracleEBS
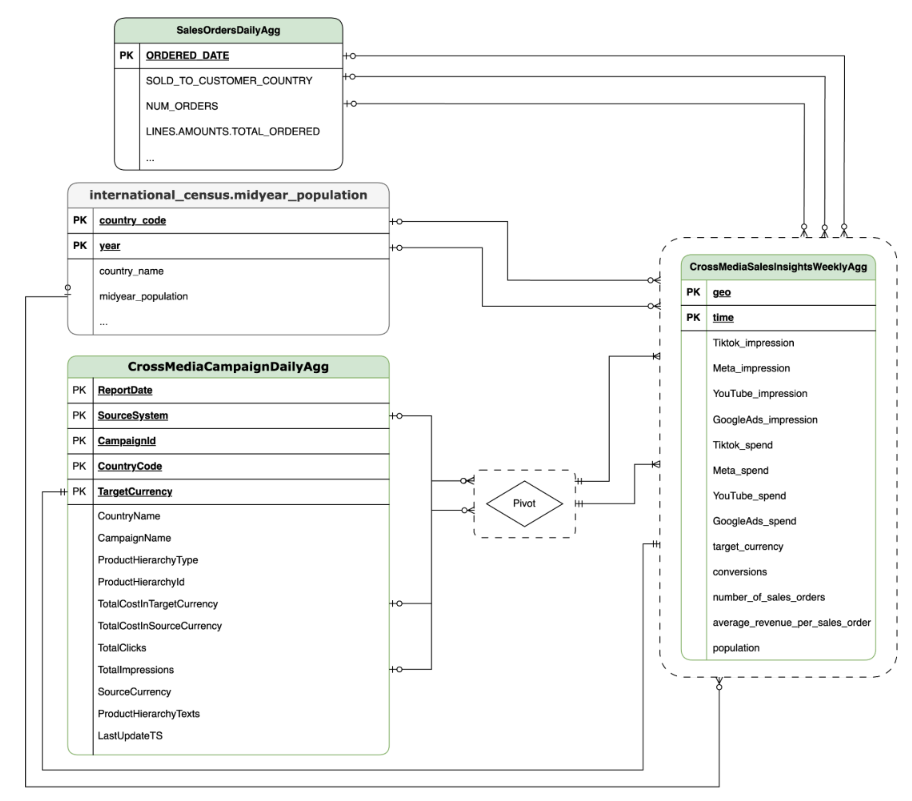
CortexForMeridian con datos de Oracle EBS.En la siguiente tabla, se muestra el esquema detallado de la vista CrossMediaSalesInsightsWeeklyAgg, que forma parte de Cortex para Meridian:
| Columna | Tipo | Descripción |
| geo | String | Es el área geográfica que se usa para agregar todos los demás valores. |
| hora | String | Es la dimensión de tiempo que se usa para agregar todos los demás valores. |
| Tiktok_impression | Número entero | Es la cantidad de veces que se mostraron tus anuncios en TikTok. |
| Meta_impression | Número entero | Es la cantidad de veces que se mostraron tus anuncios en Meta. |
| YouTube_impression | Número entero | Es la cantidad de veces que se mostraron tus anuncios en YouTube. |
| GoogleAds_impression | Número entero | Es la cantidad de veces que se mostraron tus anuncios en Google Ads. |
| Tiktok_spend | Número de punto flotante | Es la cantidad de dinero que se invirtió en publicidad en TikTok. |
| Meta_spend | Número de punto flotante | Es la cantidad de dinero que se invirtió en publicidad en Meta. |
| YouTube_spend | Número de punto flotante | Es la cantidad de dinero que se invirtió en publicidad en YouTube. |
| GoogleAds_spend | Número de punto flotante | Es la cantidad de dinero que se invirtió en publicidad en Google Ads. |
| target_currency | String | Es la moneda objetivo que se usa para todas las columnas de ingresos. |
| de conversiones | Número entero | Conversiones. |
| number_of_sales_orders | Número entero | Es la cantidad de pedidos de venta de Oracle EBS o SAP. |
| average_revenue_per_sales_order | Número de punto flotante | Es el promedio de ingresos por pedido de venta de Oracle EBS o SAP. |
| population | Número entero | Es el tamaño de la población de la ubicación geográfica. |
Implementación
En esta página, se describen los pasos para implementar Cortex Framework para Meridian, lo que permite el mejor MMM de su clase en tu entorno de Google Cloud .
Para ver una demostración de inicio rápido, consulta Demostración de inicio rápido para Meridian.
Arquitectura
Cortex para Meridian usa Cortex Framework para el marketing y los datos de medios múltiples combinados con datos de ventas. Puedes importar datos de ventas de Oracle EBS, SAP o cualquier otro sistema fuente.
En el siguiente diagrama, se describen los componentes clave de Cortex para Meridian:
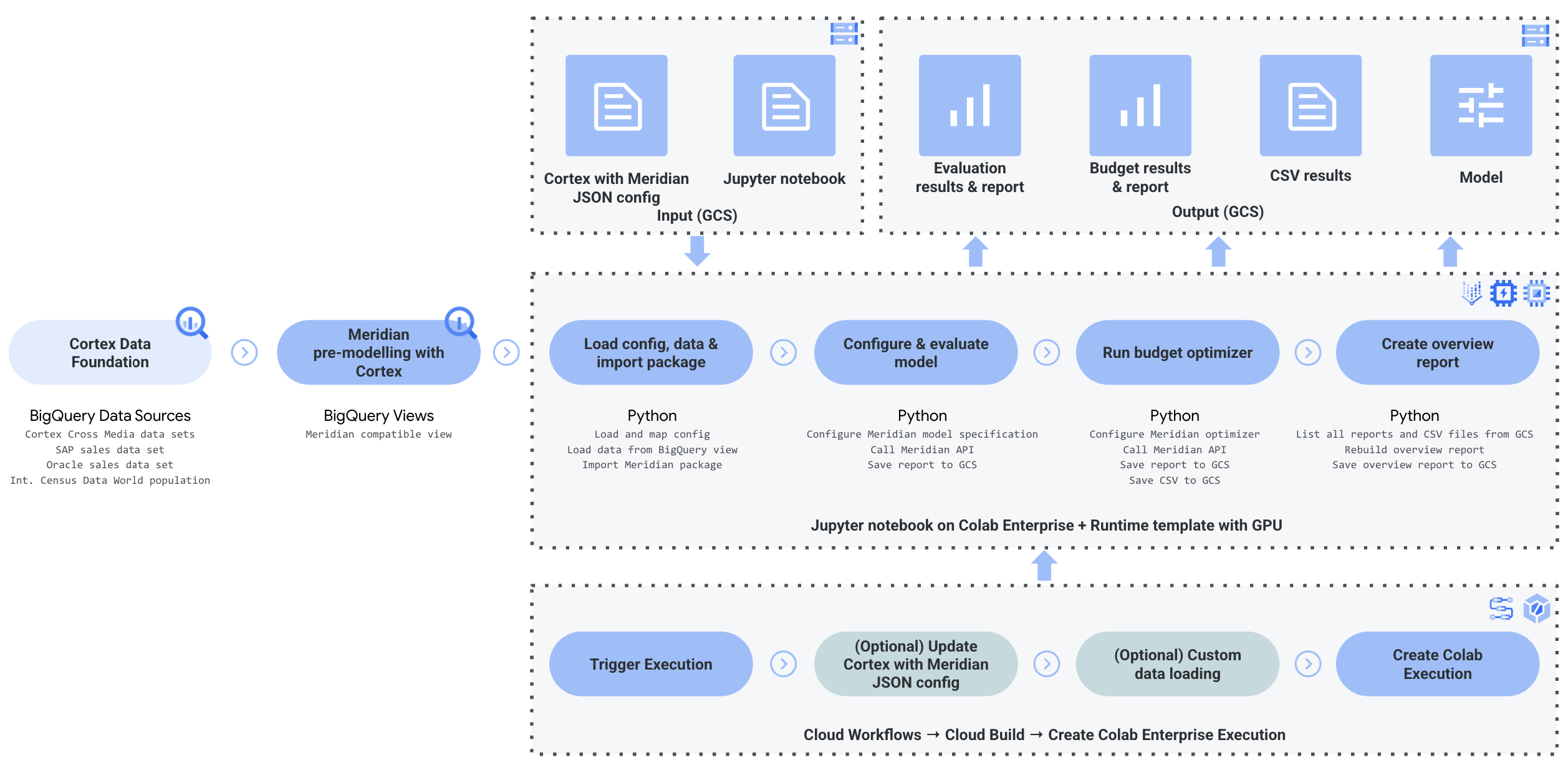
Componentes y servicios de Meridian
Durante la implementación de Cortex Framework Data Foundation (consulta los requisitos previos de implementación), puedes habilitar Cortex para Meridian configurando deployMeridian en true en el archivo config.json. Esta opción inicia una canalización adicional de Cloud Build, que instala los siguientes componentes y servicios necesarios para Meridian:
Vista de BigQuery: Se crea una vista en el conjunto de datos de informes de K9 llamada
CrossMediaSalesInsightsWeeklyAgg. Esto permite consultar datos de marketing y ventas desde Cortex Framework. La implementación real de la vista y las fuentes subyacentes dependen de la fuente de datos de ventas que selecciones durante la implementación.Bucket de Cloud Storage: El bucket
PROJECT_ID-cortex-meridiancontiene todos los artefactos que Cortex necesita y produce para Meridian en las siguientes carpetas:configuration: Define la configuración y los parámetros de Cortex para Meridian. El notebook de Colab Enterprise lo usa durante la ejecución.csv: Los datos sin procesar que se obtienen de la ejecución de Meridian se guardarán aquí como archivos CSV.models: Aquí se guardará el modelo generado después de ejecutar Meridian.notebook-run-logs: Aquí se guardarán las copias de los notebooks para cada ejecución y los registros.notebooks: Contiene el notebook principal con el código y la lógica para ejecutar Cortex para Meridian. Este notebook está diseñado para que lo personalices aún más y se adapte a tus necesidades y requisitos específicos.reporting: Es la carpeta en la que se guardarán los informes de las ejecuciones de Meridian. También contiene una plantilla HTML para generar un informe de resumen con vínculos a los resultados del informe de Meridian.
Colab Enterprise: Colab Enterprise es un servicio administrado en Google Cloud que proporciona un entorno seguro y colaborativo para los flujos de trabajo de ciencia de datos y aprendizaje automático con notebooks de Jupyter. Ofrece funciones como infraestructura administrada, controles de seguridad de nivel empresarial y la integración con otros servicios de Google Cloud , lo que lo hace adecuado para los equipos que trabajan con datos sensibles y requieren una administración sólida. Es un entorno administrado para ejecutar el notebook de Jupyter.
Cortex para Meridian usa Colab Enterprise para definir una plantilla de entorno de ejecución con la infraestructura necesaria para automatizar las ejecuciones de Meridian.
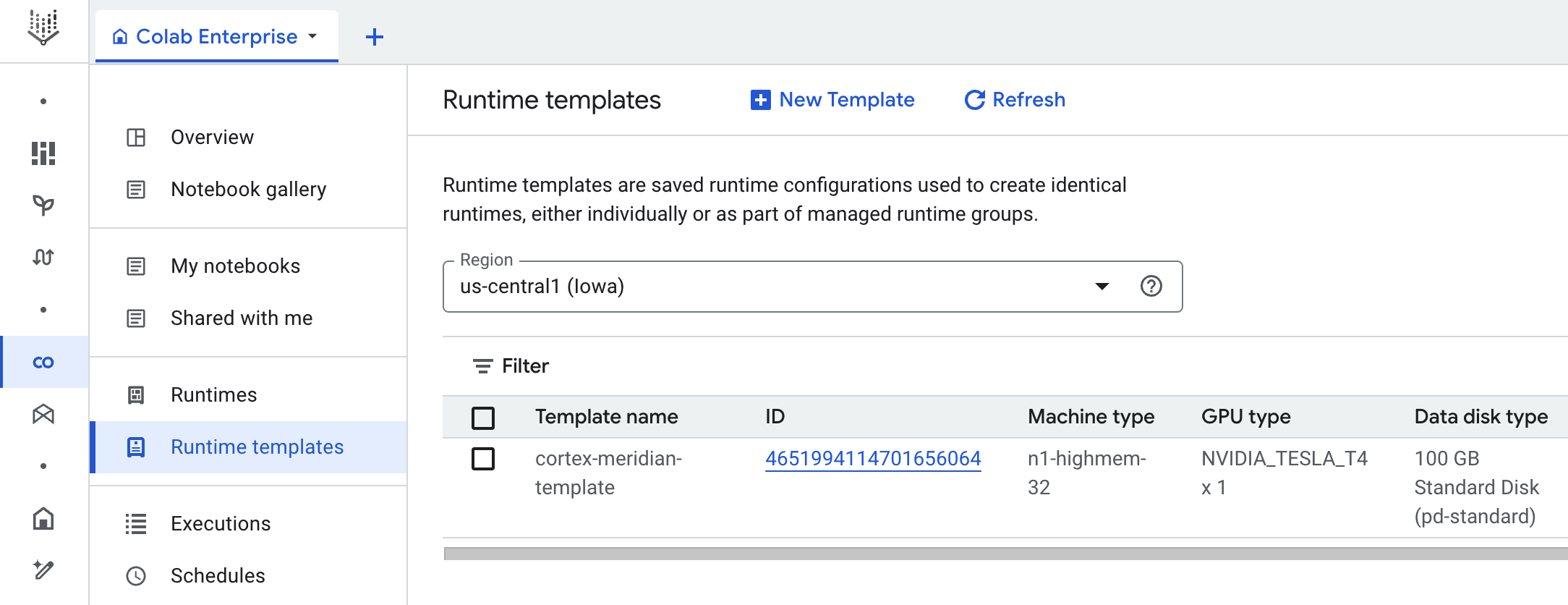
Cuando se activa la canalización de extremo a extremo con el flujo de trabajo, se crea una ejecución. Esto ejecutará una copia del notebook de Jupyter actual desde Cloud Storage con la configuración más reciente.
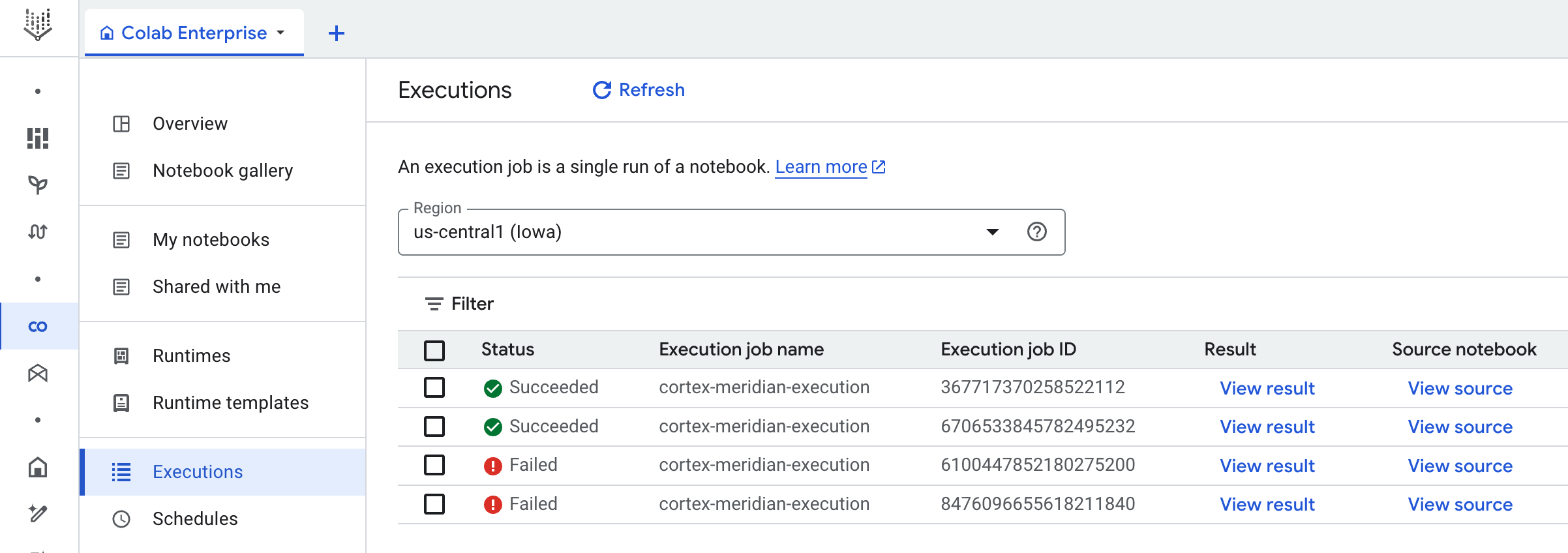
Flujo de trabajo: Un flujo de trabajo de Cloud llamado
cortex-meridian-execute-notebookorganiza la ejecución de la canalización completa de Cortex para Meridian. El flujo de trabajo llamará a la API de Colab Enterprise, que crea un tiempo de ejecución basado en la plantilla de tiempo de ejecución y ejecuta una ejecución de notebook con la configuración actual. Por último, guarda todos los resultados en Cloud Storage.
Figura 8: Workflows para Meridian. Tienes dos opciones de configuración opcionales disponibles para el flujo de trabajo:
- Si puedes proporcionar una nueva configuración de Cortex para Meridian en formato JSON como entrada para el flujo de trabajo Si lo haces, el flujo creará una copia de seguridad de la configuración anterior y la actualizará con tu entrada. Consulta REPLACE para obtener más información.
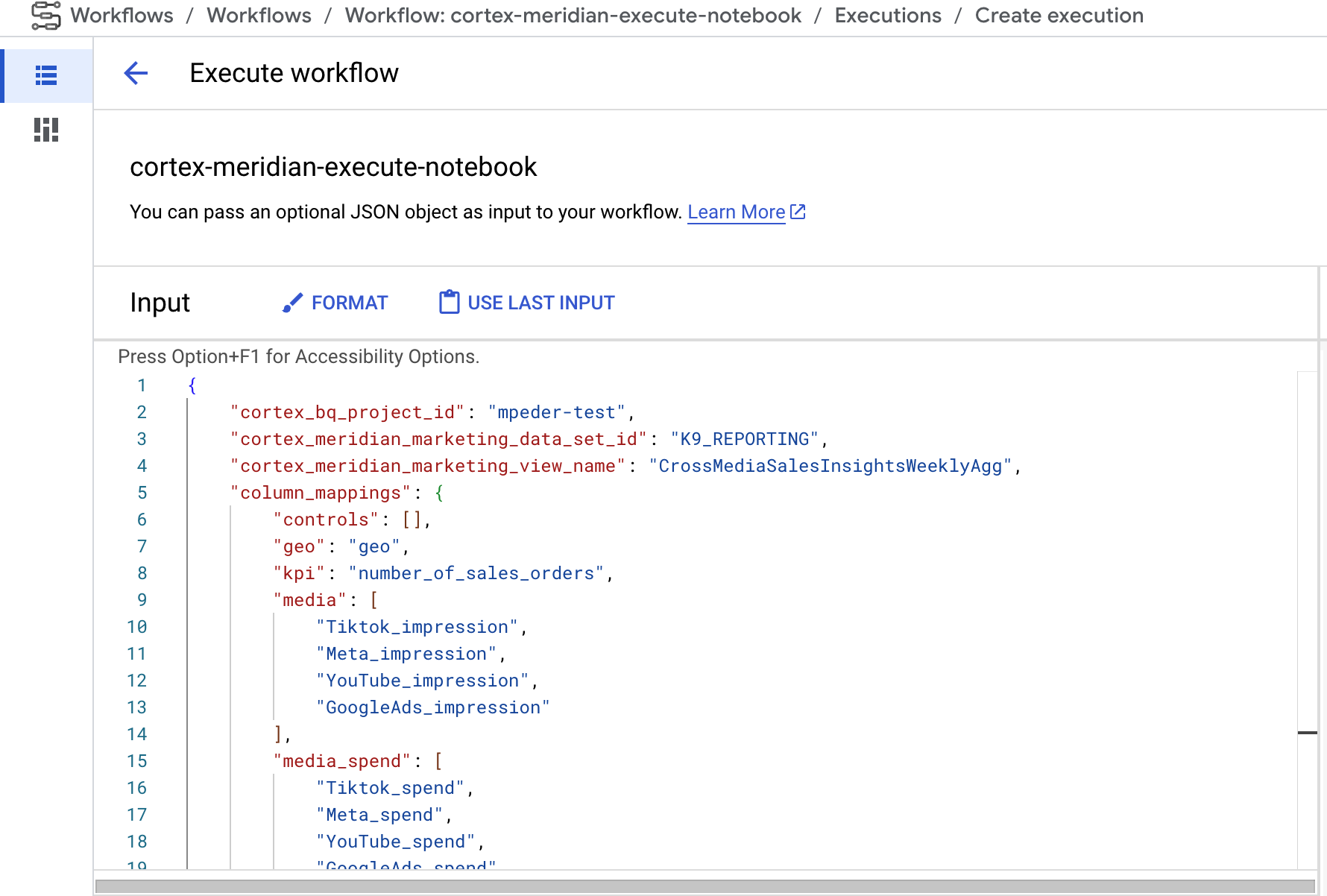
Figura 9. Ejemplo de cómo modificar y ejecutar un nuevo JSON de entrada. - El paso
pre_notebook_executiones un excelente lugar para iniciar cualquier tarea adicional que necesites automatizar antes de ejecutar el notebook. Por ejemplo, cargar datos de fuentes externas a Google Cloud Cortex Framework
Cuenta de servicio: Se requiere una cuenta de servicio dedicada durante la implementación. Esto es necesario para ejecutar el flujo de trabajo y el notebook en Colab Enterprise.
Parámetros de implementación adicionales para Meridian
El archivo config.json configura los parámetros necesarios para ejecutar Meridian con Cortex Framework. Este archivo contiene los siguientes parámetros para Cortex para Meridian:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
En la siguiente tabla, se describen el valor y la descripción de cada parámetro de Meridian:
| Parámetro | Significado | Valor predeterminado | Descripción |
k9.deployMeridian
|
Indica si se implementará Meridian. | false
|
Elige si se implementará Cortex para Meridian como parte de una implementación de Data Foundation. |
k9.Meridian.salesDataSourceType
|
Es la fuente de los datos de ventas. | - | Elige entre BYOD, SAP o OracleEBS
|
k9.Meridian.salesDatasetID
|
Es el ID de tu conjunto de datos de ventas. | - | Es el ID de tu conjunto de datos de ventas. Varía según la configuración relacionada de Cortex Data Foundation. |
k9.Meridian.deploymentType
|
Define si la implementación es limpia o incremental. | - | Elige entre initial y incremental.
|
k9.Meridian.defaultNotebookFile
|
Archivo de notebook de Jupyter. | meridian_cortex_marketing.ipynb
|
Nombre del archivo de notebook ubicado en la carpeta notebooks de Cloud Storage.
|
k9.Meridian.defaultConfigFile
|
Es el archivo de configuración para ejecutar el notebook. | cortex_meridian_config.json
|
Contiene la configuración de Cortex para Meridian que se usa cuando se ejecuta el notebook.
Debe estar ubicado en la carpeta configuration de Cloud Storage.
|
k9.Meridian.gcsBucketNameSuffix
|
Sufijo del bucket de Cortex para Meridian Cloud Storage. | cortex-meridian
|
El nombre completo del bucket será {PROJECT_ID}-cortex-meridian de forma predeterminada. |
k9.Meridian.workflow.template
|
Es la plantilla del flujo de trabajo. | create_notebook_execution_run.yaml
|
Es la plantilla para crear el flujo de trabajo. El flujo de trabajo se usa para iniciar la ejecución de un notebook. |
k9.Meridian.workflow.name
|
Es el nombre del flujo de trabajo. | cortex-meridian-execute-notebook
|
Nombre que se muestra en el portal de Google Cloud para el flujo de trabajo. |
k9.Meridian.workflow.region
|
Es la región de implementación del flujo de trabajo. | us-central1
|
Es la región de implementación del flujo de trabajo. Por lo general, elige el mismo que el resto de tu implementación. |
k9.Meridian.runnerServiceAccount
|
Es el nombre de la cuenta de servicio de Cortex para Meridian. | cortex-meridian-colab-runner
|
Es el nombre de la cuenta de servicio que se usa para ejecutar el flujo de trabajo y las ejecuciones de Colab Enterprise. |
k9.Meridian.colabEnterprise.region
|
Es la región de implementación para las ejecuciones de Colab Enterprise. | us-central1
|
Es la región de implementación para las ejecuciones de Colab Enterprise. Por lo general, elige la misma que el resto de tu implementación. |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
Es el nombre de la plantilla de entorno de ejecución de Colab Enterprise. | cortex-meridian-template
|
Es el nombre de la plantilla de entorno de ejecución de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
Es el tipo de máquina para el entorno de ejecución del notebook de Colab Enterprise. | n1-highmem-32
|
Es el tipo de máquina para el entorno de ejecución del notebook de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
Cantidad de núcleos. | 1
|
Es la cantidad de núcleos del acelerador de GPU para el entorno de ejecución del notebook de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
Es el tipo de acelerador para el tiempo de ejecución del notebook de Colab Enterprise. | NVIDIA_TESLA_T4
|
Es el tipo de GPU. |
k9.Meridian.colabEnterprise.executionName
|
Nombre de la ejecución del entorno de ejecución del notebook de Colab Enterprise. | cortex-meridian-execution
|
Es el nombre que aparecerá en la interfaz web de Colab Enterprise - Ejecuciones. |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
Nombre de la carpeta para las ejecuciones del tiempo de ejecución. | notebook-run-logs
|
Las ejecuciones del notebook de Colab almacenarán aquí los registros y las copias de ejecución del notebook. |
Flujo de trabajo
Los flujos de trabajo son la interfaz principal para iniciar las ejecuciones de Cortex para Meridian. Se implementa un flujo de trabajo predeterminado llamado cortex-meridian-execute-notebook como parte de Cortex para Meridian.
Ejecución del notebook
Para iniciar una nueva ejecución de Cortex para Meridian, sigue estos pasos:
- Ve al notebook
cortex-meridian-execute-notebooken Workflows. - Haz clic en Ejecutar para iniciar una nueva ejecución.
- Para las ejecuciones iniciales, deja el campo de entrada vacío para usar la configuración predeterminada almacenada en el archivo de configuración
cortex_meridian_config.jsonen Cloud Storage. - Vuelve a hacer clic en Ejecutar para continuar.
Después de una breve demora, se mostrará el estado de ejecución del flujo de trabajo:
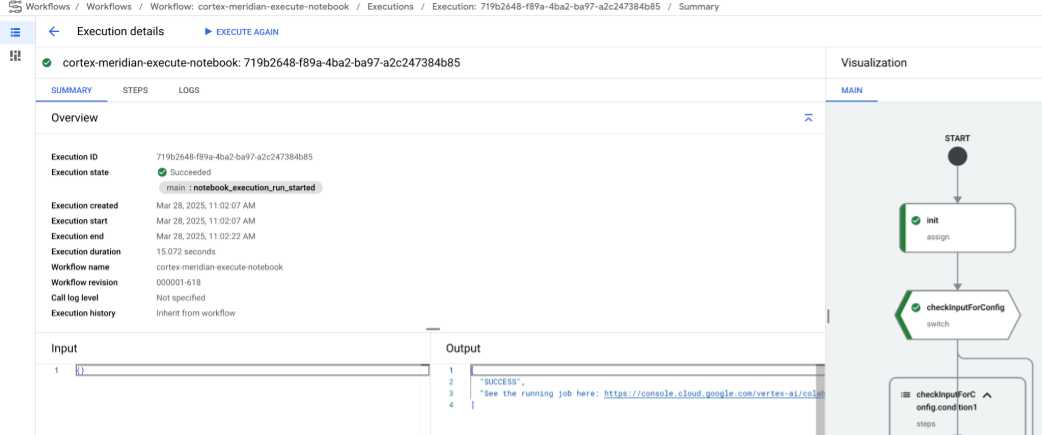
Figura 10. Ejemplo de detalles de ejecución. Realiza un seguimiento del progreso de la ejecución del notebook en Colab Enterprise.
Pasos del flujo de trabajo
El flujo de trabajo cortex-meridian-execute-notebook contiene los siguientes pasos:
| Step | Subpaso | Descripción |
init
|
-
|
Inicializa los parámetros. |
checkInputForConfig
|
-
|
Verifica si se proporcionó un nuevo archivo JSON de configuración como entrada del flujo de trabajo. |
logBackupConfigFileName
|
Registra el nombre del archivo de configuración de la copia de seguridad. | |
backupConfigFile
|
Realiza una copia de seguridad del archivo de configuración en Cloud Storage. | |
logBackupResult
|
Registra el resultado de la llamada a la API de Cloud Storage. | |
updateGCSConfigFile
|
Actualiza el archivo de configuración en Cloud Storage con los valores nuevos. | |
pre_notebook_execution
|
-
|
Este paso está vacío de forma predeterminada. Está disponible para que la personalices. Por ejemplo, la carga de datos o cualquier otro paso pertinente antes de ejecutar el bloc de notas. Para obtener más información, consulta Descripción general de Workflows y Conectores de Workflows. |
create_notebook_execution_run
|
-
|
Crea la ejecución del notebook de Colab Enterprise (a través de una secuencia de comandos de shell en Cloud Build). |
notebook_execution_run_started
|
-
|
Genera el resultado de la finalización. |
Personaliza el flujo de trabajo de ejecución de Meridian
Puedes personalizar la ejecución de Meridian proporcionando tu propio archivo de configuración JSON en el campo de entrada de Workflows:
- Ingresa el JSON completo de la configuración modificada en el campo de entrada.
- Luego, el flujo de trabajo hará lo siguiente:
- Reemplaza el archivo
cortex_meridian_config.jsonexistente en Cloud Storage por el JSON proporcionado. - Crea una copia de seguridad del archivo de configuración original en el directorio
Cloud Storage/configuration. - El nombre del archivo de copia de seguridad seguirá el formato
cortex_meridian_config_workflow_backup_workflow_execution_id.json, en el que workflow_execution_id es un identificador único para la ejecución actual del flujo de trabajo (por ejemplo,cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json).
- Reemplaza el archivo
Descripción general del notebook de Jupyter
El notebook de Python meridian_cortex_marketing.ipynb, ubicado en la carpeta notebooks de tu bucket de Cloud Storage, controla la funcionalidad principal de cargar datos de entrada para ejecutar el modelo de Meridian.
El flujo de ejecución del notebook consta de los siguientes pasos:
- Instala los paquetes necesarios (incluido Meridian) y, luego, importa las bibliotecas requeridas.
- Carga funciones auxiliares para interactuar con Cloud Storage y BigQuery.
- Recupera la configuración de ejecución del archivo
configuration/cortex_meridian_config.jsonen Cloud Storage. - Carga datos de Cortex Framework desde la vista Cortex Framework Data Foundation en BigQuery.
- Configura la especificación del modelo de Meridian y asigna los modelos de datos de la Data Foundation de Cortex Framework para marketing y ventas al esquema de entrada del modelo de Meridian.
- Ejecuta el muestreo de Meridian y genera un informe de resumen, que se guarda en Cloud Storage (
/reporting). - Ejecuta el optimizador de presupuesto para el escenario predeterminado y genera el informe de resumen en Cloud Storage (
/reporting). - Guarda el modelo en Cloud Storage (
/models). - Guarda los resultados en formato CSV en Cloud Storage (
/csv). - Genera un informe de resumen y guárdalo en Cloud Storage (
/reporting).
Importa un notebook para su ejecución y edición manual
Para personalizar o ejecutar el notebook de forma manual, impórtalo desde Cloud Storage:
- Ve a Colab Enterprise.
- Haz clic en Mis notebooks.
- Haz clic en Importar.
- Selecciona Cloud Storage como la fuente de importación y, luego, selecciona el notebook de Cloud Storage.
- Haz clic en Importar.
Se cargará y abrirá el notebook.
Resultados de las ejecuciones de notebooks
Para revisar los resultados de la ejecución del notebook, abre una copia completa del notebook con todos los resultados de las celdas:
- Ve a Ejecuciones en Colab Enterprise.
- Selecciona la región correspondiente en el menú desplegable.
- Junto a la ejecución del notebook para la que deseas ver los resultados, haz clic en Ver resultado.
- Colab Enterprise abrirá el resultado de la ejecución del notebook en una pestaña nueva.
- Para ver el resultado, haz clic en la pestaña nueva.
Plantilla de entorno de ejecución
Google Cloud Colab Enterprise usa plantillas de entorno de ejecución para definir entornos de ejecución preconfigurados. La implementación de Cortex para Meridian incluye una plantilla de tiempo de ejecución predefinida, adecuada para ejecutar el notebook de Meridian. Esta plantilla se usa automáticamente para crear entornos de ejecución para las ejecuciones de notebooks.
Si es necesario, puedes crear manualmente plantillas de entorno de ejecución adicionales.