Memastikan keandalan dan kualitas penyiapan Patroni dengan ketersediaan tinggi sangat penting untuk mempertahankan operasi database yang berkelanjutan dan meminimalkan waktu henti.
Halaman ini memberikan panduan komprehensif untuk menguji cluster Patroni Anda, yang mencakup berbagai skenario kegagalan, konsistensi replikasi, dan mekanisme failover.
Menguji penyiapan Patroni
Hubungkan ke salah satu instance patroni Anda (alloydb-patroni1,
alloydb-patroni2, atau alloydb-patroni3) dan buka
folder patroni AlloyDB Omni.
cd /alloydb/
Periksa log Patroni.
docker compose logs alloydbomni-patroni
Entri terakhir harus mencerminkan informasi tentang node Patroni. Anda
akan melihat sesuatu yang mirip dengan berikut ini.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock
alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock
alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock
Hubungkan ke instance yang menjalankan Linux yang memiliki konektivitas jaringan ke
instance Patroni utama Anda, alloydb-patroni1, dan dapatkan informasi tentang
instance tersebut. Anda mungkin perlu menginstal alat jq dengan menjalankan
sudo apt-get install jq -y.
Memanggil endpoint Patroni HTTP API di node Patroni akan menampilkan berbagai detail
tentang status dan konfigurasi instance PostgreSQL tertentu yang dikelola
oleh Patroni, termasuk informasi status cluster, linimasa, informasi WAL, dan
pemeriksaan kondisi yang menunjukkan apakah node dan cluster sudah aktif dan berjalan
dengan benar.
Menguji konfigurasi HAProxy
Di komputer yang memiliki browser dan konektivitas jaringan ke node HAProxy Anda,
buka alamat berikut: http://haproxy:7000. Atau, Anda dapat
menggunakan alamat IP eksternal instance HAProxy, bukan nama host-nya.
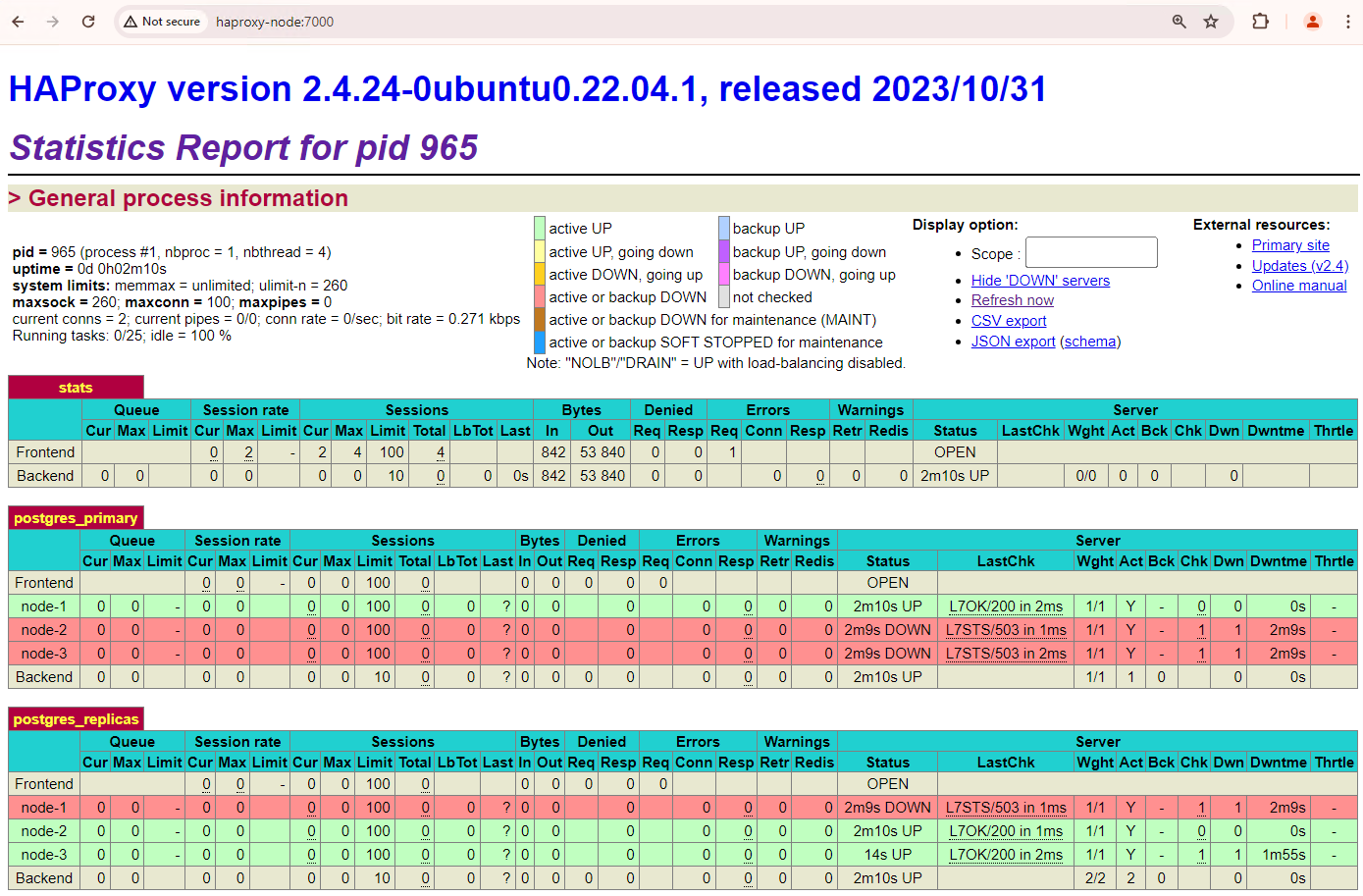
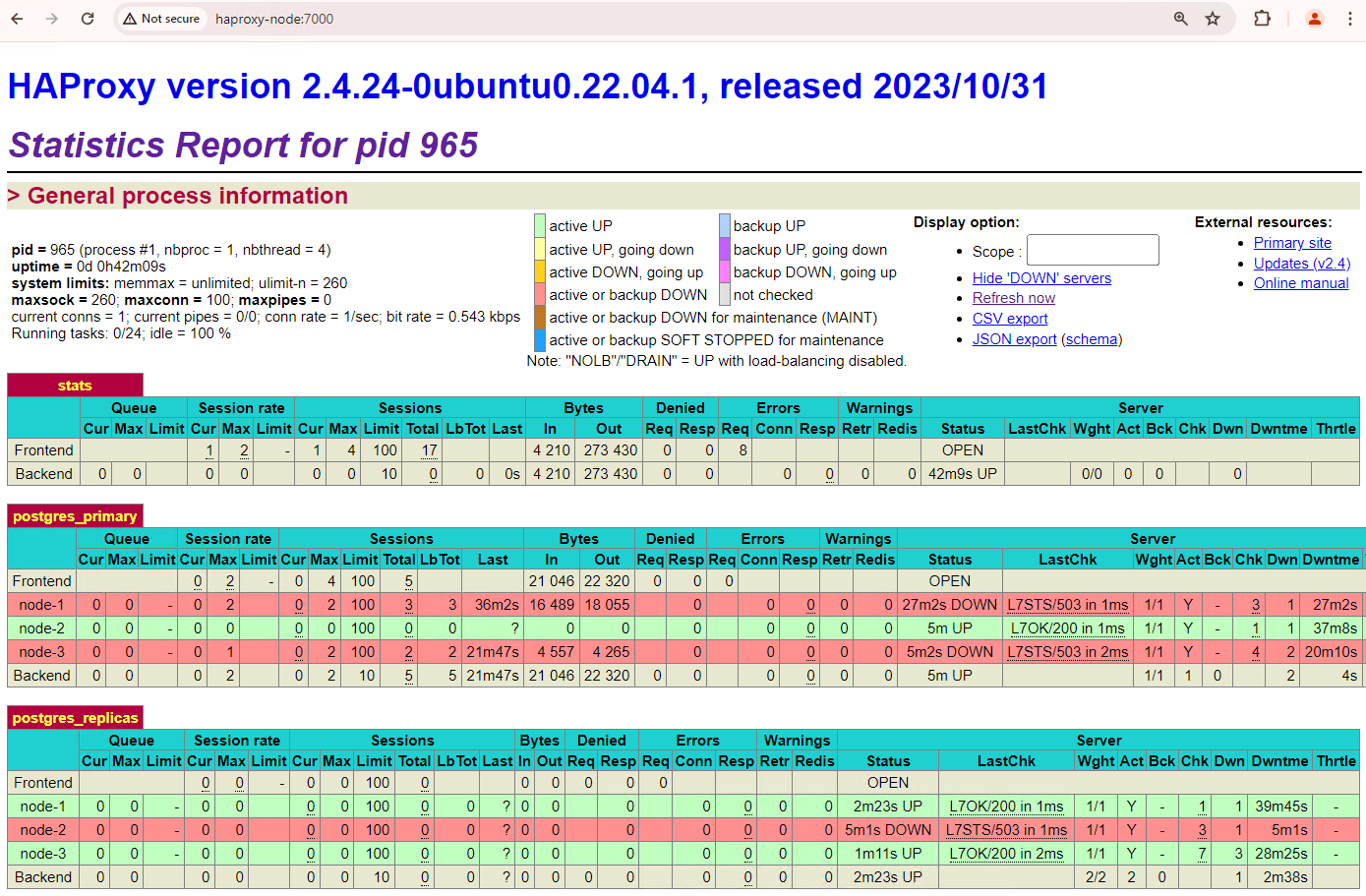
Anda akan melihat sesuatu yang mirip dengan screenshot berikut.
Gambar 1. Halaman status HAProxy yang menampilkan status respons dan latensi node Patroni.
Di dasbor HAProxy, Anda dapat melihat status kondisi dan latensi
node Patroni utama, patroni1, dan dua replika, patroni2 dan
patroni3.
Anda dapat menjalankan kueri untuk memeriksa statistik replikasi di cluster Anda. Dari
klien seperti pgAdmin, hubungkan ke server database utama Anda melalui
HAProxy dan jalankan kueri berikut.
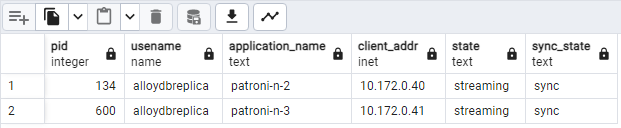
Anda akan melihat sesuatu yang mirip dengan diagram berikut, yang menunjukkan bahwa
patroni2 dan patroni3 melakukan streaming dari patroni1.
Gambar 2. Output pg_stat_replication yang menampilkan status replikasi
node Patroni.
Menguji failover otomatis
Di bagian ini, di cluster tiga node, kita akan menyimulasikan gangguan pada node utama dengan menghentikan penampung Patroni yang terpasang dan berjalan. Anda dapat menghentikan layanan Patroni di server utama untuk menyimulasikan gangguan atau menerapkan beberapa aturan firewall untuk menghentikan komunikasi ke node tersebut.
Di instance Patroni utama, buka folder Patroni AlloyDB Omni.
cd /alloydb/
Hentikan penampung.
docker compose down
Anda akan melihat sesuatu yang mirip dengan output berikut. Tindakan ini akan
memastikan bahwa penampung dan jaringan telah dihentikan.
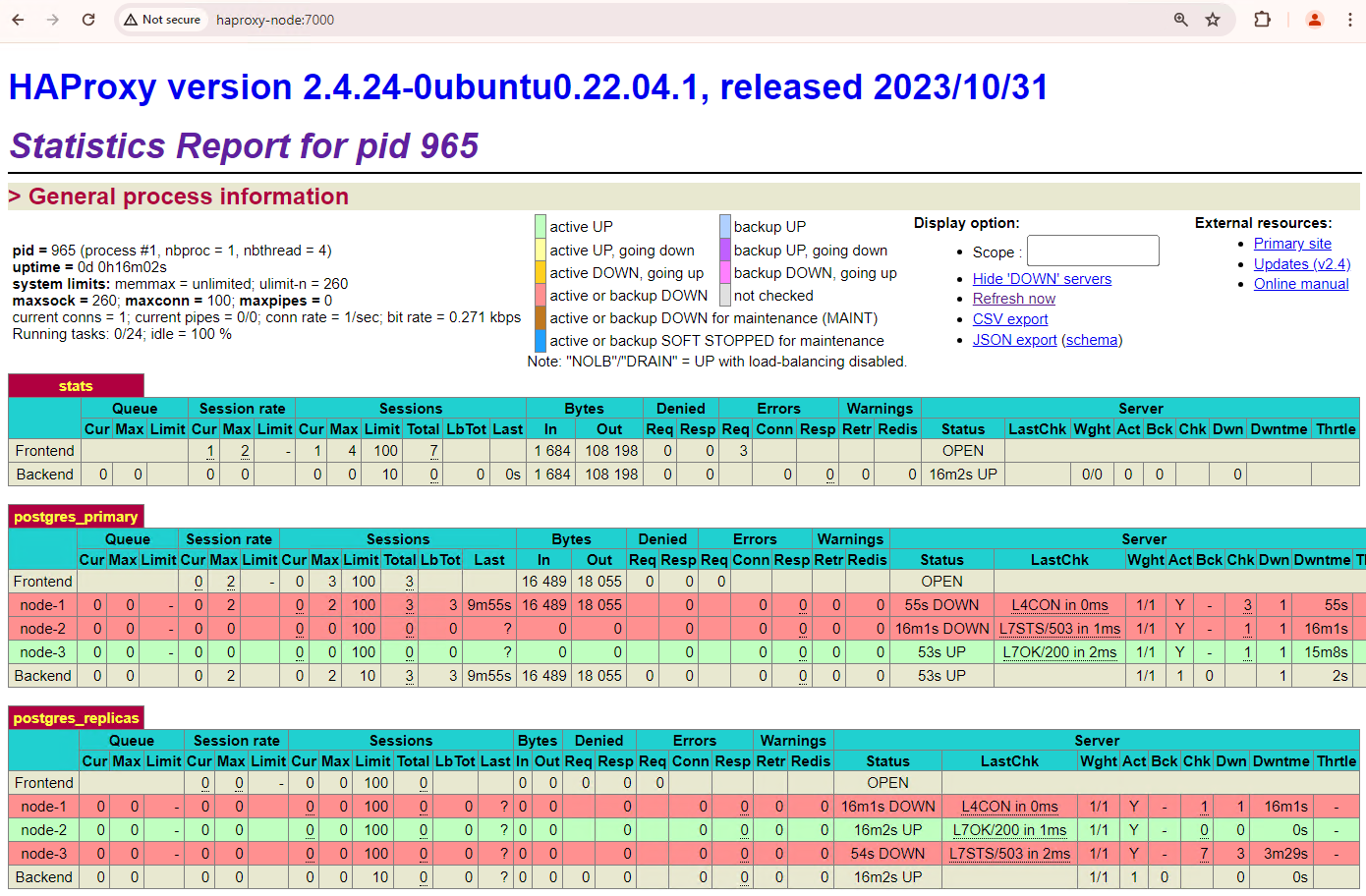
Muat ulang dasbor HAProxy dan lihat cara failover terjadi.
Gambar 3. Dasbor HAProxy yang menampilkan failover dari node primer
ke node standby.
Instance patroni3 menjadi primer baru, dan patroni2 adalah satu-satunya
replika yang tersisa. patroni1, yang sebelumnya merupakan server utama, tidak berfungsi dan health check-nya gagal.
Patroni melakukan dan mengelola failover melalui kombinasi pemantauan, konsensus, dan orkestrasi otomatis. Segera setelah node
primer gagal memperbarui masa berlakunya dalam waktu tunggu yang ditentukan, atau jika node tersebut melaporkan
kegagalan, node lain dalam cluster akan mengenali kondisi ini melalui
sistem konsensus. Node yang tersisa berkoordinasi untuk memilih replika yang paling sesuai untuk dipromosikan sebagai yang utama baru. Setelah replika kandidat dipilih,
Patroni mempromosikan node ini menjadi replika utama dengan menerapkan perubahan yang diperlukan,
seperti memperbarui konfigurasi PostgreSQL dan memutar ulang semua
catatan WAL yang belum diproses. Kemudian, node utama yang baru memperbarui sistem konsensus dengan
statusnya dan replika lainnya mengonfigurasi ulang dirinya untuk mengikuti
node utama yang baru, termasuk mengganti sumber replikasinya dan berpotensi
mengejar transaksi baru. HAProxy mendeteksi primary baru dan
mengarahkan ulang koneksi klien dengan tepat, sehingga memastikan gangguan minimal.
Dari klien seperti pgAdmin, hubungkan ke server database Anda melalui HAProxy dan periksa statistik replikasi di cluster Anda setelah failover.
Anda akan melihat sesuatu yang mirip dengan diagram berikut, yang menunjukkan bahwa hanya
patroni2 yang sedang melakukan streaming.
Output pg_stat_replication Gambar 4. yang menunjukkan status replikasi
node Patroni setelah failover.
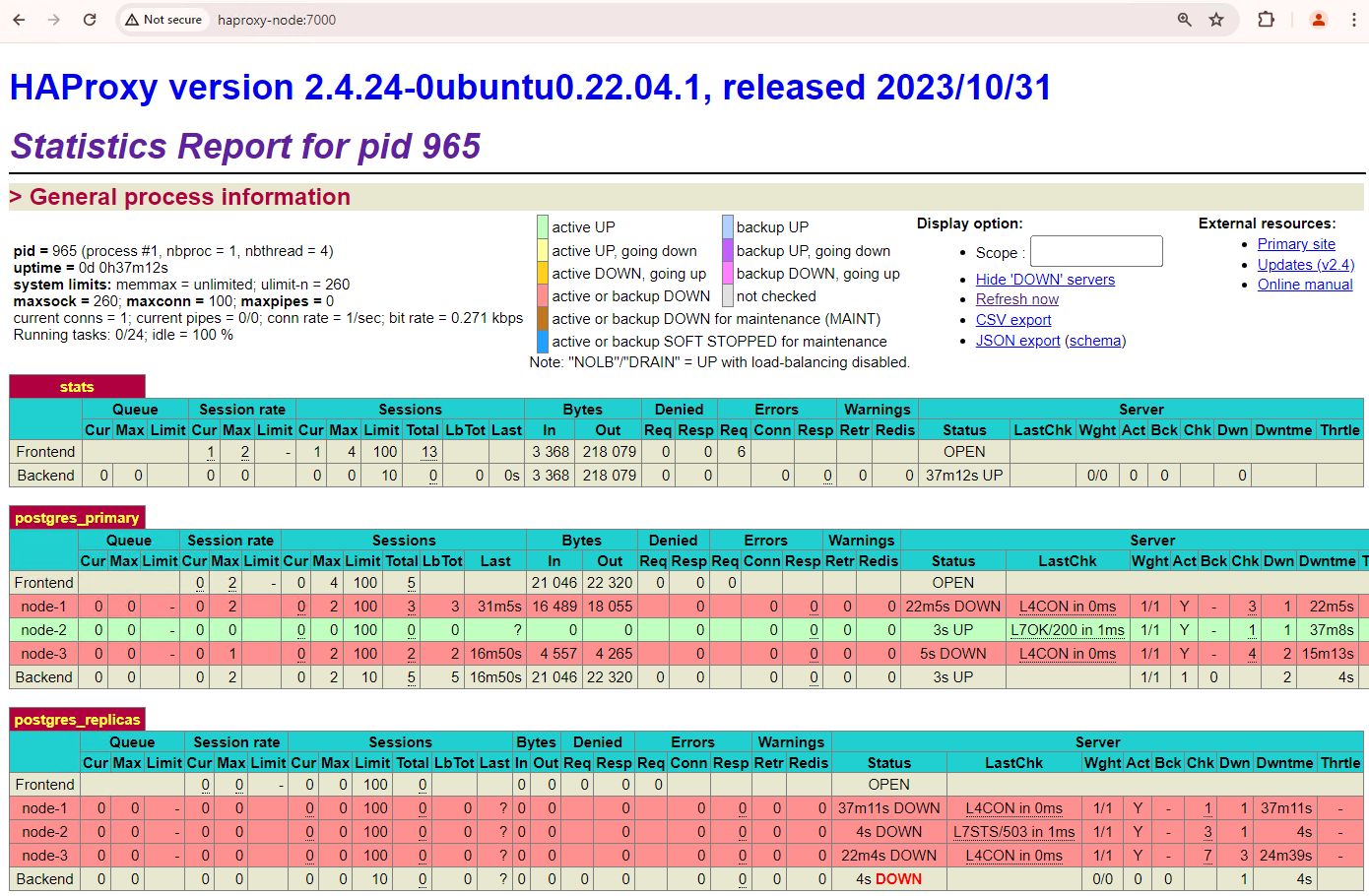
Cluster tiga node Anda dapat bertahan dari satu pemadaman lagi. Jika Anda menghentikan node utama saat ini, patroni3, failover lain akan terjadi.
Gambar 5. Dasbor HAProxy yang menampilkan failover dari node utama,
patroni3, ke node standby, patroni2.
Pertimbangan penggantian
Fallback adalah proses untuk mengaktifkan kembali node sumber sebelumnya setelah terjadi failover. Pengalihan otomatis umumnya tidak direkomendasikan dalam cluster database dengan ketersediaan tinggi karena beberapa masalah penting, seperti pemulihan yang tidak lengkap, risiko skenario split-brain, dan jeda replikasi.
Di cluster Patroni, jika Anda mengaktifkan dua node yang Anda simulasikan pemadaman listriknya, node tersebut akan bergabung kembali ke cluster sebagai replika standby.
Gambar 6. Dasbor HAProxy yang menampilkan pemulihan patroni1 dan
patroni3 sebagai node standby.
Sekarang patroni1 dan patroni3 direplikasi dari patroni2 primer saat ini.
Gambar 7. Output pg_stat_replication yang menunjukkan status replikasi
node Patroni setelah fallback.
Jika ingin melakukan failback secara manual ke primer awal, Anda dapat melakukannya dengan
menggunakan antarmuka command line patronictl. Dengan memilih penggantian manual, Anda dapat memastikan proses pemulihan yang lebih andal, konsisten, dan terverifikasi secara menyeluruh, sehingga menjaga integritas dan ketersediaan sistem database Anda.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[[["\u003cp\u003eThis guide outlines how to test a Patroni cluster for reliability, including failure scenarios, replication consistency, and failover mechanisms.\u003c/p\u003e\n"],["\u003cp\u003eYou can inspect the Patroni logs and use the Patroni HTTP API to view cluster health, configuration, and the state of each PostgreSQL instance.\u003c/p\u003e\n"],["\u003cp\u003eThe HAProxy dashboard provides a real-time view of the health and latency of each Patroni node within the cluster.\u003c/p\u003e\n"],["\u003cp\u003eSimulating a primary node outage by stopping the container demonstrates the automatic failover process, where a standby node is promoted to primary and HAProxy redirects client connections accordingly.\u003c/p\u003e\n"],["\u003cp\u003eWhile automatic fallback is not advised, manual fallback to the initial primary node is possible using the \u003ccode\u003epatronictl\u003c/code\u003e command-line interface to ensure a controlled and verified recovery.\u003c/p\u003e\n"]]],[],null,["# Test your high availability setup\n\nSelect a documentation version: 15.7.0keyboard_arrow_down\n\n- [Current (16.8.0)](/alloydb/omni/current/docs/high-availability/test)\n- [16.8.0](/alloydb/omni/16.8.0/docs/high-availability/test)\n- [16.3.0](/alloydb/omni/16.3.0/docs/high-availability/test)\n- [15.12.0](/alloydb/omni/15.12.0/docs/high-availability/test)\n- [15.7.1](/alloydb/omni/15.7.1/docs/high-availability/test)\n- [15.7.0](/alloydb/omni/15.7.0/docs/high-availability/test)\n\n\u003cbr /\u003e\n\n| **Note:** Your use of AlloyDB Omni is subject to the agreement between you and Google that governs Google Cloud offerings. If you do not have a Google Cloud account, or have not otherwise entered into an agreement with Google that governs Google Cloud offerings, please do not proceed or download this software until you have done so. To create a Google Cloud account, see [the Google Cloud homepage](/docs/get-started).\n\n\u003cbr /\u003e\n\nEnsuring the reliability and quality of your high availability Patroni setup is\ncrucial for maintaining continuous database operations and minimizing downtime.\nThis page provides a comprehensive guide to testing your Patroni cluster,\ncovering various failure scenarios, replication consistency, and failover\nmechanisms.\n\nTest your Patroni setup\n-----------------------\n\n1. Connect to any of your patroni instances (`alloydb-patroni1`,\n `alloydb-patroni2`, or `alloydb-patroni3`) and navigate to the\n AlloyDB Omni patroni folder.\n\n ```\n cd /alloydb/\n ```\n2. Inspect the Patroni logs.\n\n ```\n docker compose logs alloydbomni-patroni\n ```\n\n The last entries should reflect information about the Patroni node. You\n should see something similar to the following. \n\n alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock\n alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock\n alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock\n\n3. Connect to any instance running Linux that has network connectivity to your\n primary Patroni instance, `alloydb-patroni1`, and get information about the\n instance. You might need to install the `jq` tool by running\n `sudo apt-get install jq -y`.\n\n ```\n curl -s http://alloydb-patroni1:8008/patroni | jq .\n ```\n\n You should see something similar to the following displayed. \n\n {\n \"state\": \"running\",\n \"postmaster_start_time\": \"2024-05-16 14:12:30.031673+00:00\",\n \"role\": \"master\",\n \"server_version\": 150005,\n \"xlog\": {\n \"location\": 83886408\n },\n \"timeline\": 1,\n \"replication\": [\n {\n \"usename\": \"alloydbreplica\",\n \"application_name\": \"patroni2\",\n \"client_addr\": \"10.172.0.40\",\n \"state\": \"streaming\",\n \"sync_state\": \"async\",\n \"sync_priority\": 0\n },\n {\n \"usename\": \"alloydbreplica\",\n \"application_name\": \"patroni3\",\n \"client_addr\": \"10.172.0.41\",\n \"state\": \"streaming\",\n \"sync_state\": \"async\",\n \"sync_priority\": 0\n }\n ],\n \"dcs_last_seen\": 1715870011,\n \"database_system_identifier\": \"7369600155531440151\",\n \"patroni\": {\n \"version\": \"3.3.0\",\n \"scope\": \"my-patroni-cluster\",\n \"name\": \"patroni1\"\n }\n }\n\nCalling the Patroni HTTP API endpoint on a Patroni node exposes various details\nabout the state and configuration of that particular PostgreSQL instance managed\nby Patroni, including cluster state information, timeline, WAL information, and\nhealth checks indicating whether the nodes and cluster are up and running\ncorrectly.\n\nTest your HAProxy setup\n-----------------------\n\n1. On a machine with a browser and network connectivity to your HAProxy node,\n go to the following address: `http://haproxy:7000`. Alternatively, you can\n use the external IP address of the HAProxy instance instead of its hostname.\n\n You should see something similar to the following screenshot.\n\n **Figure 1.** HAProxy status page showing health status and latency of\n Patroni nodes.\n\n In the HAProxy dashboard you can see the health status and latency of your\n primary Patroni node, `patroni1`, and of the two replicas, `patroni2` and\n `patroni3`.\n2. You can perform queries to check the replication stats in your cluster. From\n a client such as pgAdmin, connect to your primary database server through\n HAProxy and run the following query.\n\n SELECT\n pid, usename, application_name, client_addr, state, sync_state\n FROM\n pg_stat_replication;\n\n You should see something similar to the following diagram, showing that\n `patroni2` and `patroni3` are streaming from `patroni1`.\n\n **Figure 2.** pg_stat_replication output showing the replication state of\n the Patroni nodes.\n\nTest automatic failover\n-----------------------\n\nIn this section, in your three node cluster, we simulate an outage on the\nprimary node by stopping the attached running Patroni container. You can either\nstop the Patroni service on the primary to simulate an outage or enforce\nsome firewall rules to stop communication to that node.\n\n1. On the primary Patroni instance, navigate to the AlloyDB Omni\n Patroni folder.\n\n ```\n cd /alloydb/\n ```\n2. Stop the container.\n\n ```\n docker compose down\n ```\n\n You should see something similar to the following output. This should\n validate that the container and network were stopped. \n\n [+] Running 2/2\n ✔ Container alloydb-patroni Removed\n ✔ Network alloydbomni-patroni_default Removed\n\n3. Refresh the HAProxy dashboard and see how failover takes place.\n\n **Figure 3.** HAProxy dashboard showing the failover from the primary node\n to the standby node.\n\n The `patroni3` instance became the new primary, and `patroni2` is the only\n remaining replica. The previous primary, `patroni1`, is down and health\n checks fail for it.\n\n Patroni performs and manages the failover through a combination of\n monitoring, consensus, and automated orchestration. As soon as the primary\n node fails to renew its lease within a specified timeout, or if it reports a\n failure, the other nodes in the cluster recognize this condition through the\n consensus system. The remaining nodes coordinate to select the most suitable\n replica to promote as the new primary. Once a candidate replica is selected,\n Patroni promotes this node to primary by applying the necessary changes,\n such as updating the PostgreSQL configuration and replaying any outstanding\n WAL records. Then, the new primary node updates the consensus system with\n its status and the other replicas reconfigure themselves to follow the new\n primary, including switching their replication source and potentially\n catching up with any new transactions. HAProxy detects the new primary and\n redirects client connections accordingly, ensuring minimal disruption.\n4. From a client such as pgAdmin, connect to your database server through\n HAProxy and check the replication stats in your cluster after failover.\n\n SELECT\n pid, usename, application_name, client_addr, state, sync_state\n FROM\n pg_stat_replication;\n\n You should see something similar to the following diagram, showing that only\n `patroni2` is streaming now.\n\n **Figure 4.** pg_stat_replication output showing the replication state of\n the Patroni nodes after failover.\n5. Your three node cluster can survive one more outage. If you stop the current\n primary node, `patroni3`, another failover takes place.\n\n **Figure 5.** HAProxy dashboard showing the failover from the primary node,\n `patroni3`, to the standby node, `patroni2`.\n\nFallback considerations\n-----------------------\n\nFallback is the process to reinstate the former source node after a failover\nhas occurred. Automatic fallback is generally not recommended in a high\navailability database cluster because of several critical concerns, such as\nincomplete recovery, risk of split-brain scenarios, and replication lag.\n\nIn your Patroni cluster, if you bring up the two nodes that you simulated an\noutage with, they will rejoin the cluster as standby replicas.\n\n**Figure 6.** HAProxy dashboard showing the restoration of `patroni1` and\n`patroni3` as standby nodes.\n\nNow `patroni1` and `patroni3` are replicating from the current primary\n`patroni2`.\n\n**Figure 7.** pg_stat_replication output showing the replication state of the\nPatroni nodes after fallback.\n\nIf you want to manually fall back to your initial primary, you can do that by\nusing the [patronictl](https://patroni.readthedocs.io/en/latest/patronictl.html)\ncommand-line interface. By opting for manual fallback, you can ensure a more\nreliable, consistent, and thoroughly verified recovery process, maintaining the\nintegrity and availability of your database systems."]]