Con AI Platform Pipelines, puoi orchestrare i tuoi flussi di lavoro di machine learning (ML) come pipeline riutilizzabili e riproducibili. AI Platform Pipelines ti evita la difficoltà di configurare Kubeflow Pipelines con TensorFlow Extended su Google Kubernetes Engine.
Questa guida descrive diverse opzioni per il deployment di AI Platform Pipelines su GKE. Puoi eseguire il deployment di Kubeflow Pipelines su un cluster GKE esistente o crearne uno nuovo. Se vuoi riutilizzare un cluster GKE esistente, assicurati che soddisfi i seguenti requisiti:
- Il cluster deve avere almeno 3 nodi. Ogni nodo deve avere almeno 2 CPU e 4 GB di memoria disponibili.
- L'ambito di accesso del cluster deve concedere l'accesso completo a tutte le API Cloud oppure il cluster deve utilizzare un account di servizio personalizzato.
- Nel cluster non deve essere già installato Kubeflow Pipelines.
Seleziona l'opzione di implementazione migliore per la tua situazione:
- Utilizza AI Platform Pipelines per creare un nuovo cluster GKE con accesso completo a Google Cloud e per eseguire il deployment di Kubeflow Pipelines nel cluster. Questa opzione semplifica il deployment e l'utilizzo di AI Platform Pipelines.
- Crea un nuovo cluster GKE con accesso granulare aGoogle Cloud ed esegui il deployment di Kubeflow Pipelines su questo cluster. Questa opzione ti consente di specificare le Google Cloud risorse e le API a cui hanno accesso i carichi di lavoro sul tuo cluster.
- Esegui il deployment di AI Platform Pipelines in un cluster GKE esistente. Questa opzione descrive come eseguire il deployment di AI Platform Pipelines su un cluster GKE esistente.
Prima di iniziare
Prima di seguire questa guida, controlla che il tuo Google Cloud progetto sia configurato correttamente e che tu disponga delle autorizzazioni sufficienti per eseguire il deployment di AI Platform Pipelines.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Segui le istruzioni riportate di seguito per verificare se ti sono stati assegnati i ruoli necessari per eseguire il deployment di AI Platform Pipelines.
-
Apri una sessione di Cloud Shell.
Cloud Shell si apre in un frame nella parte inferiore della console Google Cloud.
-
Per eseguire il deployment di AI Platform Pipelines, devi disporre dei ruoli Visualizzatore (
roles/viewer) e Amministratore Kubernetes Engine (roles/container.admin) nel progetto o di altri ruoli che includono le stesse autorizzazioni, come il ruolo Proprietario (roles/owner). Esegui il comando seguente in Cloud Shell per elencare i principali che dispongono dei ruoli Visualizzatore e Amministratore di Kubernetes Engine.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
Sostituisci PROJECT_ID con l'ID del tuo progetto Google Cloud.
Utilizza l'output di questo comando per verificare che il tuo account abbia i ruoli Visualizzatore e Amministratore Kubernetes Engine.
-
Se vuoi concedere l'accesso granulare al cluster, devi anche disporre del ruolo Amministratore account di servizio (
roles/iam.serviceAccountAdmin) nel progetto o di altri ruoli che includono le stesse autorizzazioni, come il ruolo Editor (roles/editor) o Proprietario (roles/owner) nel progetto. Esegui il seguente comando in Cloud Shell per elencare i principali che dispongono del ruolo Amministratore account di servizio.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
Sostituisci PROJECT_ID con l'ID del tuo progetto Google Cloud.
Utilizza l'output di questo comando per verificare che il tuo account abbia il ruolo Amministratore account di servizio.
-
Se non ti sono stati concessi i ruoli richiesti, contatta l'amministratore del progetto Google Cloud per ulteriore assistenza.
Scopri di più sulla concessione dei ruoli di Identity and Access Management.
-
Esegui il deployment di AI Platform Pipelines con accesso completo a Google Cloud
AI Platform Pipelines semplifica la configurazione e l'utilizzo di Kubeflow Pipelines creando un cluster GKE per te e eseguendo il deployment di Kubeflow Pipelines sul cluster. Quando AI Platform Pipelines crea un
cluster GKE per te, questo cluster utilizza l'account di servizio Compute Engine predefinito. Per fornire al cluster l'accesso completo alle Google Cloud risorse e alle API che hai attivato nel progetto, puoi concedere al cluster l'accesso all'https://www.googleapis.com/auth/cloud-platform ambito di accesso. La concessione dell'accesso in questo modo consente alle pipeline di ML in esecuzione sul tuo cluster di accedere alle API Google Cloud, ad esempio AI Platform Training e AI Platform Prediction. Sebbene questa procedura semplifichi la configurazione di AI Platform Pipelines, potrebbe concedere agli sviluppatori della pipeline un accesso eccessivo a risorse e API. Google Cloud
Segui le istruzioni riportate di seguito per eseguire il deployment di AI Platform Pipelines con accesso completo alle risorse e alle API. Google Cloud
Apri le pipeline della piattaforma AI nella console Google Cloud.
Nella barra degli strumenti di AI Platform Pipelines, fai clic su Nuova istanza. Kubeflow Pipelines si apre in Google Cloud Marketplace.
Fai clic su Configura. Si apre il modulo Esegui il deployment di Kubeflow Pipelines.
Se viene visualizzato il link Crea un nuovo cluster, fai clic su Crea un nuovo cluster. In caso contrario, vai al passaggio successivo.

Seleziona la Zona cluster in cui deve trovarsi il cluster. Per decidere quale zona utilizzare, leggi le best practice per la selezione della regione.
Seleziona Consenti l'accesso alle seguenti API Cloud per concedere alle applicazioni in esecuzione nel cluster GKE l'accesso alle risorse Google Cloud . Se selezioni questa casella, accordi al tuo cluster l'accesso all'ambito di accesso
https://www.googleapis.com/auth/cloud-platform. Questo ambito di accesso fornisce l'accesso completo alle Google Cloud risorse che hai attivato nel progetto. Concedere al cluster l'accesso alle risorse Google Cloud in questo modo ti evita di dover creare e gestire un account di servizio o creare un secret Kubernetes.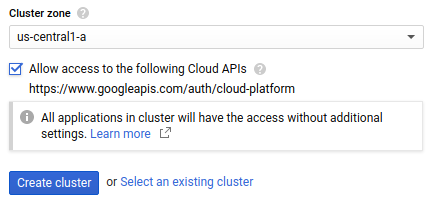
Fai clic su Crea cluster. Questo passaggio potrebbe richiedere diversi minuti.
Gli spazi dei nomi vengono utilizzati per gestire le risorse in grandi cluster GKE. Se non prevedi di utilizzare spazi dei nomi nel cluster, seleziona default nell'elenco a discesa Spazio dei nomi.
Se prevedi di utilizzare gli spazi dei nomi nel tuo cluster GKE, crea uno spazio dei nomi utilizzando l'elenco a discesa Spazio dei nomi. Per creare uno spazio dei nomi:
- Seleziona Crea uno spazio dei nomi nell'elenco a discesa Spazio dei nomi. Viene visualizzata la casella Nuovo nome dello spazio dei nomi.
- Inserisci il nome dello spazio dei nomi in Nuovo nome dello spazio dei nomi.
Per saperne di più sugli spazi dei nomi, leggi un post del blog sull'organizzazione di Kubernetes con gli spazi dei nomi.
Nella casella Nome istanza app, inserisci un nome per l'istanza Kubeflow Pipelines.
Lo spazio di archiviazione gestito ti consente di archiviare i metadati e gli elementi della pipeline di ML utilizzando Cloud SQL e Cloud Storage, anziché su dischi permanenti Compute Engine. L'utilizzo di servizi gestiti per archiviare gli artefatti e i metadati della pipeline semplifica il backup e il ripristino dei dati del cluster. Per eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito, seleziona Utilizza lo spazio di archiviazione gestito e fornisci le seguenti informazioni:
Bucket Cloud Storage per l'archiviazione degli artefatti: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia gli artefatti della pipeline in un bucket Cloud Storage. Specifica il nome del bucket in cui vuoi che Kubeflow Pipelines memorizzi gli elementi. Se il bucket specificato non esiste, il programma di deployment di Kubeflow Pipelines ne crea automaticamente uno per te nella regione
us-central1.Nome di connessione dell'istanza Cloud SQL: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia i metadati della pipeline in un database MySQL su Cloud SQL. Specifica il nome della connessione per l'istanza MySQL Cloud SQL.
Nome utente del database: specifica il nome utente del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Attualmente, l'utente del database deve disporre dei privilegi MySQL
ALLper eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito. Se lasci vuoto questo campo, il valore predefinito è root.Password del database: specifica la password del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Se lasci vuoto questo campo, Kubeflow Pipelines si connette al database senza fornire una password, il che non va a buon fine se è obbligatoria una password per il nome utente specificato.
Prefisso del nome del database: specifica il prefisso del nome del database. Il valore del prefisso deve iniziare con una lettera e contenere solo lettere minuscole, numeri e trattini bassi.
Durante la procedura di deployment, Kubeflow Pipelines crea due database, "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se nella tua istanza MySQL esistono database con questi nomi, Kubeflow Pipelines riutilizza i database esistenti. Se questo valore non viene specificato, il nome dell'istanza dell'app viene utilizzato come prefisso del nome del database.
Fai clic su Esegui il deployment. Questo passaggio potrebbe richiedere diversi minuti.
Per accedere alla dashboard delle pipeline, apri AI Platform Pipelines nella console Google Cloud.
Poi, fai clic su Apri la dashboard delle pipeline per la tua istanza AI Platform Pipelines.
Esegui il deployment di AI Platform Pipelines con accesso granulare a Google Cloud
Le pipeline ML accedono alle risorse Google Cloud utilizzando l'account di servizio e l'ambito di accesso del pool di nodi del cluster GKE. Al momento, per limitare l'accesso del tuo cluster a risorse Google Cloud specifiche, devi eseguire il deployment di AI Platform Pipelines su un cluster GKE che utilizza un account di servizio gestito dall'utente.
Segui le istruzioni riportate nelle sezioni seguenti per creare e configurare un account di servizio, creare un cluster GKE utilizzando l'account di servizio ed eseguire il deployment di Kubeflow Pipelines nel cluster GKE.
Crea un account di servizio per il tuo cluster GKE
Segui le istruzioni riportate di seguito per configurare un account di servizio per il tuo cluster GKE.
Apri una sessione di Cloud Shell.
Cloud Shell si apre in un frame nella parte inferiore della console Google Cloud.
Esegui i seguenti comandi in Cloud Shell per creare il tuo account di servizio e concedergli l'accesso sufficiente per eseguire le pipeline di AI Platform. Scopri di più sui ruoli necessari per eseguire AI Platform Pipelines con un account di servizio gestito dall'utente.
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewerSostituisci quanto segue:
- SERVICE_ACCOUNT_NAME: il nome dell'account di servizio da creare.
- PROJECT_ID: il progetto Google Cloud in cui è stato creato l'account di servizio.
Concedi al tuo account di servizio l'accesso a qualsiasi Google Cloud risorsa o API richiesta dalle tue pipeline di ML. Scopri di più sui ruoli di Identity and Access Management e sulla gestione degli account di servizio.
Concedi al tuo account utente il ruolo Utente account di servizio (
iam.serviceAccountUser) nel tuo account di servizio.gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
Sostituisci quanto segue:
- SERVICE_ACCOUNT_NAME: il nome del tuo account di servizio.
- PROJECT_ID: il tuo progetto Google Cloud.
- USERNAME: il tuo nome utente su Google Cloud.
Configura il cluster GKE
Segui le istruzioni riportate di seguito per configurare il cluster GKE.
Apri Google Kubernetes Engine nella console Google Cloud.
Fai clic sul pulsante Crea cluster. Viene visualizzato il modulo Impostazioni di base del cluster.
Inserisci il nome del cluster.
Per Tipo di località, seleziona A livello di zona, quindi seleziona la zona che preferisci per il tuo cluster. Per decidere quale zona utilizzare, consulta le best practice per la selezione della regione.
Nel riquadro di navigazione, in Pool di nodi, fai clic su default-pool. Viene visualizzato il modulo Dettagli del pool di nodi.
Inserisci il numero di nodi da creare nel cluster. Il cluster deve avere almeno 3 nodi per eseguire il deployment di AI Platform Pipelines. Devi disporre di una quota di risorse disponibile per i nodi e le relative risorse (ad esempio le route del firewall).
Nel riquadro di navigazione, in Pool di nodi, fai clic su Nodi. Si apre il modulo Nodi.
Scegli la configurazione della macchina predefinita da utilizzare per le istanze. Per eseguire il deployment di AI Platform Pipelines, devi selezionare un tipo di macchina con almeno 2 CPU e 4 GB di memoria, ad esempio
n1-standard-2. Ogni tipo di macchina viene fatturato in modo diverso. Per informazioni sui prezzi dei tipi di macchine, consulta il foglio di prezzi dei tipi di macchine.Nel riquadro di navigazione, in Pool di nodi, fai clic su Sicurezza. Viene visualizzato il modulo Sicurezza del nodo.
Dall'elenco a discesa Account di servizio, seleziona l'account di servizio che hai creato in precedenza in questa guida.
In caso contrario, configura il cluster GKE come preferisci. Scopri di più sulla creazione di un cluster GKE.
Fai clic su Crea.
Installa Kubeflow Pipelines sul tuo cluster GKE
Segui le istruzioni riportate di seguito per configurare Kubeflow Pipelines su un cluster GKE.
Apri le pipeline della piattaforma AI nella console Google Cloud.
Nella barra degli strumenti di AI Platform Pipelines, fai clic su Nuova istanza. Kubeflow Pipelines si apre in Google Cloud Marketplace.
Fai clic su Configura. Si apre il modulo Esegui il deployment di Kubeflow Pipelines.
Nell'elenco a discesa Cluster, seleziona il cluster che hai creato in un passaggio precedente. Se il cluster che vuoi utilizzare non è idoneo per il deployment, verifica che soddisfi i requisiti per il deployment di Kubeflow Pipelines.
Gli spazi dei nomi vengono utilizzati per gestire le risorse in grandi cluster GKE. Se non prevedi di utilizzare spazi dei nomi nel cluster, seleziona default nell'elenco a discesa Spazio dei nomi.
Se prevedi di utilizzare gli spazi dei nomi nel tuo cluster GKE, crea uno spazio dei nomi utilizzando l'elenco a discesa Spazio dei nomi. Per creare uno spazio dei nomi:
- Seleziona Crea uno spazio dei nomi nell'elenco a discesa Spazio dei nomi. Viene visualizzata la casella Nuovo nome dello spazio dei nomi.
- Inserisci il nome dello spazio dei nomi in Nuovo nome dello spazio dei nomi.
Per saperne di più sugli spazi dei nomi, leggi un post del blog sull'organizzazione di Kubernetes con gli spazi dei nomi.
Nella casella Nome istanza app, inserisci un nome per l'istanza Kubeflow Pipelines.
Lo spazio di archiviazione gestito ti consente di archiviare i metadati e gli elementi della pipeline di ML utilizzando Cloud SQL e Cloud Storage, anziché su dischi permanenti Compute Engine. L'utilizzo di servizi gestiti per archiviare gli artefatti e i metadati della pipeline semplifica il backup e il ripristino dei dati del cluster. Per eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito, seleziona Utilizza lo spazio di archiviazione gestito e fornisci le seguenti informazioni:
Bucket Cloud Storage per l'archiviazione degli artefatti: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia gli artefatti della pipeline in un bucket Cloud Storage. Specifica il nome del bucket in cui vuoi che Kubeflow Pipelines memorizzi gli elementi. Se il bucket specificato non esiste, il programma di deployment di Kubeflow Pipelines ne crea automaticamente uno per te nella regione
us-central1.Nome di connessione dell'istanza Cloud SQL: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia i metadati della pipeline in un database MySQL su Cloud SQL. Specifica il nome della connessione per l'istanza MySQL Cloud SQL.
Nome utente del database: specifica il nome utente del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Attualmente, l'utente del database deve disporre dei privilegi MySQL
ALLper eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito. Se lasci vuoto questo campo, il valore predefinito è root.Password del database: specifica la password del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Se lasci vuoto questo campo, Kubeflow Pipelines si connette al database senza fornire una password, il che non va a buon fine se è obbligatoria una password per il nome utente specificato.
Prefisso del nome del database: specifica il prefisso del nome del database. Il valore del prefisso deve iniziare con una lettera e contenere solo lettere minuscole, numeri e trattini bassi.
Durante la procedura di deployment, Kubeflow Pipelines crea due database, "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se nella tua istanza MySQL esistono database con questi nomi, Kubeflow Pipelines riutilizza i database esistenti. Se questo valore non viene specificato, il nome dell'istanza dell'app viene utilizzato come prefisso del nome del database.
Fai clic su Esegui il deployment. Questo passaggio potrebbe richiedere diversi minuti.
Per accedere alla dashboard delle pipeline, apri AI Platform Pipelines nella console Google Cloud.
Poi, fai clic su Apri la dashboard delle pipeline per la tua istanza AI Platform Pipelines.
Esegui il deployment di AI Platform Pipelines in un cluster GKE esistente
Per utilizzare Google Cloud Marketplace per eseguire il deployment di Kubeflow Pipelines su un cluster GKE, devono essere soddisfatte le seguenti condizioni:
- Il cluster deve avere almeno 3 nodi. Ogni nodo deve avere almeno 2 CPU e 4 GB di memoria disponibili.
- L'ambito di accesso del cluster deve concedere l'accesso completo a tutte le API Cloud oppure il cluster deve utilizzare un account di servizio personalizzato.
- Nel cluster non deve essere già installato Kubeflow Pipelines.
Scopri di più su come configurare il cluster GKE per AI Platform Pipelines.
Segui le istruzioni riportate di seguito per configurare Kubeflow Pipelines su un cluster GKE.
Apri le pipeline della piattaforma AI nella console Google Cloud.
Nella barra degli strumenti di AI Platform Pipelines, fai clic su Nuova istanza. Kubeflow Pipelines si apre in Google Cloud Marketplace.
Fai clic su Configura. Si apre il modulo Esegui il deployment di Kubeflow Pipelines.
Nell'elenco a discesa Cluster, seleziona il cluster. Se il cluster che vuoi utilizzare non è idoneo per il deployment, verifica che soddisfi i requisiti per il deployment di Kubeflow Pipelines.
Gli spazi dei nomi vengono utilizzati per gestire le risorse in grandi cluster GKE. Se il cluster non utilizza spazi dei nomi, seleziona default nell'elenco a discesa Spazio dei nomi.
Se il cluster utilizza gli spazi dei nomi, selezionane uno esistente o creane uno utilizzando l'elenco a discesa Spazio dei nomi. Per creare uno spazio dei nomi:
- Seleziona Crea uno spazio dei nomi nell'elenco a discesa Spazio dei nomi. Viene visualizzata la casella Nuovo nome dello spazio dei nomi.
- Inserisci il nome dello spazio dei nomi in Nuovo nome dello spazio dei nomi.
Per saperne di più sugli spazi dei nomi, leggi un post del blog sull'organizzazione di Kubernetes con gli spazi dei nomi.
Nella casella Nome istanza app, inserisci un nome per l'istanza Kubeflow Pipelines.
Lo spazio di archiviazione gestito ti consente di archiviare i metadati e gli elementi della pipeline di ML utilizzando Cloud SQL e Cloud Storage, anziché su dischi permanenti Compute Engine. L'utilizzo di servizi gestiti per archiviare gli artefatti e i metadati della pipeline semplifica il backup e il ripristino dei dati del cluster. Per eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito, seleziona Utilizza lo spazio di archiviazione gestito e fornisci le seguenti informazioni:
Bucket Cloud Storage per l'archiviazione degli artefatti: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia gli artefatti della pipeline in un bucket Cloud Storage. Specifica il nome del bucket in cui vuoi che Kubeflow Pipelines memorizzi gli elementi. Se il bucket specificato non esiste, il programma di deployment di Kubeflow Pipelines ne crea automaticamente uno per te nella regione
us-central1.Nome di connessione dell'istanza Cloud SQL: con lo spazio di archiviazione gestito, Kubeflow Pipelines archivia i metadati della pipeline in un database MySQL su Cloud SQL. Specifica il nome della connessione per l'istanza MySQL Cloud SQL.
Nome utente del database: specifica il nome utente del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Attualmente, l'utente del database deve disporre dei privilegi MySQL
ALLper eseguire il deployment di Kubeflow Pipelines con lo spazio di archiviazione gestito. Se lasci vuoto questo campo, il valore predefinito è root.Password del database: specifica la password del database da utilizzare per Kubeflow Pipelines quando ti connetti all'istanza MySQL. Se lasci vuoto questo campo, Kubeflow Pipelines si connette al database senza fornire una password, il che non va a buon fine se è obbligatoria una password per il nome utente specificato.
Prefisso del nome del database: specifica il prefisso del nome del database. Il valore del prefisso deve iniziare con una lettera e contenere solo lettere minuscole, numeri e trattini bassi.
Durante la procedura di deployment, Kubeflow Pipelines crea due database, "DATABASE_NAME_PREFIX_pipeline" e "DATABASE_NAME_PREFIX_metadata". Se nella tua istanza MySQL esistono database con questi nomi, Kubeflow Pipelines riutilizza i database esistenti. Se questo valore non viene specificato, il nome dell'istanza dell'app viene utilizzato come prefisso del nome del database.
Fai clic su Esegui il deployment. Questo passaggio potrebbe richiedere diversi minuti.
Per accedere alla dashboard delle pipeline, apri AI Platform Pipelines nella console Google Cloud.
Poi, fai clic su Apri la dashboard delle pipeline per la tua istanza AI Platform Pipelines.
Passaggi successivi
- Orchestra il processo di ML come una pipeline.
- Utilizza l'interfaccia utente di Kubeflow Pipelines per eseguire una pipeline.
- Scopri di più su AI Platform Pipelines e ML Pipelines.