|
|
|
Questo tutorial mostra l'ottimizzazione dell'obiettivo condizionale dello strumento di ottimizzazione di AI Platform.
Set di dati
Il set di dati Census Income utilizzato da questo esempio per l'addestramento è ospitato dal repository di machine learning dell'Università della California di Irvine.
Utilizzando i dati del censimento che contengono l'età, il livello di istruzione, lo stato civile e la professione di una persona (le funzionalità), l'obiettivo sarà prevedere se la persona guadagna o meno 50.000 dollari all'anno (l'etichetta target). Addestrerai un modello di regressione logistica che, date le informazioni di un individuo, restituisce un numero compreso tra 0 e 1. Questo numero può essere interpretato come la probabilità che la persona abbia un reddito annuo superiore a 50.000 dollari.
Obiettivo
Questo tutorial mostra come utilizzare AI Platform Optimizer per ottimizzare la ricerca degli iperparametri per i modelli di machine learning.
Questo esempio implementa una demo di apprendimento automatico che ottimizza un modello di classificazione su un set di dati del censimento utilizzando AI Platform Optimizer con gli algoritmi integrati di AI Platform Training. Utilizzerai AI Platform Optimizer per ottenere i valori degli iperparametri suggeriti e inviare job di addestramento del modello con questi valori tramite gli algoritmi integrati di AI Platform Training.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud:
- AI Platform Training
- Cloud Storage
Scopri i prezzi di AI Platform Training e i prezzi di Cloud Storage e utilizza il Calcolatore prezzi per generare una stima dei costi in base all'utilizzo previsto.
PIP installa pacchetti e dipendenze
Installa dipendenze aggiuntive non installate nell'ambiente del notebook.
- Utilizza la versione GA principale più recente del framework.
! pip install -U google-api-python-client
! pip install -U google-cloud
! pip install -U google-cloud-storage
! pip install -U requests
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Configurare il progetto Google Cloud
I passaggi che seguono sono obbligatori, indipendentemente dall'ambiente del tuo notebook.
Assicurati che la fatturazione sia attivata per il tuo progetto.
Se esegui questo notebook localmente, devi installare Google Cloud SDK.
Inserisci l'ID progetto nella cella di seguito. Quindi esegui la cella per assicurarti che Cloud SDK utilizzi il progetto corretto per tutti i comandi in questo notebook.
Nota: Jupyter esegue le righe con prefisso ! come comandi shell e interpola le variabili Python con prefisso $ in questi comandi.
PROJECT_ID = "[project-id]" #@param {type:"string"}
! gcloud config set project $PROJECT_ID
Autentica il tuo account Google Cloud
Se utilizzi AI Platform Notebooks, il tuo ambiente è già autenticato. Salta questi passaggi.
Per la cella di seguito dovrai autenticarti due volte.
import sys
# If you are running this notebook in Colab, run this cell and follow the
# instructions to authenticate your Google Cloud account. This provides access
# to your Cloud Storage bucket and lets you submit training jobs and prediction
# requests.
if 'google.colab' in sys.modules:
from google.colab import auth as google_auth
google_auth.authenticate_user()
# If you are running this tutorial in a notebook locally, replace the string
# below with the path to your service account key and run this cell to
# authenticate your Google Cloud account.
else:
%env GOOGLE_APPLICATION_CREDENTIALS your_path_to_credentials.json
# Log in to your account on Google Cloud
! gcloud auth application-default login
! gcloud auth login
Importare librerie
import json
import time
import datetime
from googleapiclient import errors
Tutorial
Configurazione
Questa sezione definisce alcuni parametri e metodi util per chiamare le API AI Platform Optimizer. Per iniziare, inserisci le seguenti informazioni.
# Update to your username
USER = '[user-id]' #@param {type: 'string'}
STUDY_ID = '{}_study_{}'.format(USER, datetime.datetime.now().strftime('%Y%m%d_%H%M%S')) #@param {type: 'string'}
REGION = 'us-central1'
def study_parent():
return 'projects/{}/locations/{}'.format(PROJECT_ID, REGION)
def study_name(study_id):
return 'projects/{}/locations/{}/studies/{}'.format(PROJECT_ID, REGION, study_id)
def trial_parent(study_id):
return study_name(study_id)
def trial_name(study_id, trial_id):
return 'projects/{}/locations/{}/studies/{}/trials/{}'.format(PROJECT_ID, REGION,
study_id, trial_id)
def operation_name(operation_id):
return 'projects/{}/locations/{}/operations/{}'.format(PROJECT_ID, REGION, operation_id)
print('USER: {}'.format(USER))
print('PROJECT_ID: {}'.format(PROJECT_ID))
print('REGION: {}'.format(REGION))
print('STUDY_ID: {}'.format(STUDY_ID))
Crea il client API
La cella seguente crea il client API generato automaticamente utilizzando il servizio di rilevamento API di Google. Lo schema dell'API in formato JSON è ospitato in un bucket Cloud Storage.
from google.cloud import storage
from googleapiclient import discovery
_OPTIMIZER_API_DOCUMENT_BUCKET = 'caip-optimizer-public'
_OPTIMIZER_API_DOCUMENT_FILE = 'api/ml_public_google_rest_v1.json'
def read_api_document():
client = storage.Client(PROJECT_ID)
bucket = client.get_bucket(_OPTIMIZER_API_DOCUMENT_BUCKET)
blob = bucket.get_blob(_OPTIMIZER_API_DOCUMENT_FILE)
return blob.download_as_string()
ml = discovery.build_from_document(service=read_api_document())
print('Successfully built the client.')
Configurazione dello studio
In questo tutorial, AI Platform Optimizer crea uno studio e richiede prove. Per ogni prova, creerai un job di addestramento con algoritmo integrato di AI Platform per l'addestramento del modello utilizzando gli iperparametri suggeriti. Una misurazione per ogni prova viene registrata come modello accuracy.
Le funzionalità del parametro condizionale fornite da AI Platform Optimizer definiscono uno spazio di ricerca ad albero per gli iperparametri. L'iperparametro di primo livello è model_type, che può essere scelto tra LINEAR e WIDE_AND_DEEP. Ogni tipo di modello ha iperparametri di secondo livello corrispondenti da ottimizzare:
- Se
model_typeèLINEAR,learning_rateè sintonizzato. - Se
model_typeèWIDE_AND_DEEP, vengono sintonizzati sialearning_ratechednn_learning_rate.
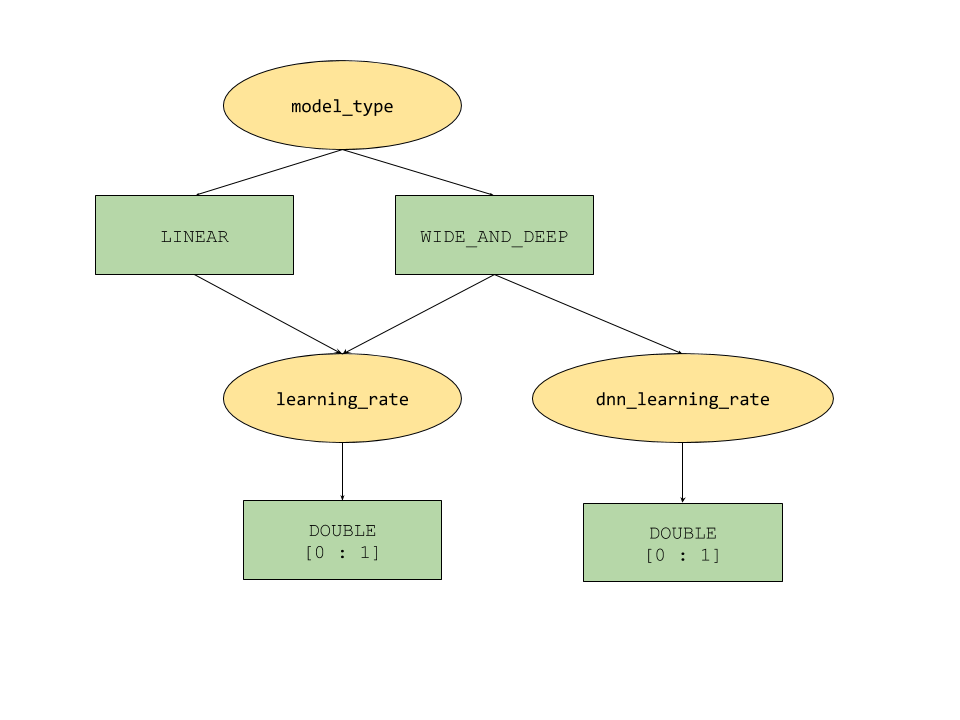
Di seguito è riportata una configurazione di studio di esempio, creata come dizionario Python gerarchico. È già compilato. Esegui la cella per configurare lo studio.
param_learning_rate = {
'parameter': 'learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['LINEAR', 'WIDE_AND_DEEP']
},
}
param_dnn_learning_rate = {
'parameter': 'dnn_learning_rate',
'type' : 'DOUBLE',
'double_value_spec' : {
'min_value' : 0.00001,
'max_value' : 1.0
},
'scale_type' : 'UNIT_LOG_SCALE',
'parent_categorical_values' : {
'values': ['WIDE_AND_DEEP']
},
}
param_model_type = {
'parameter': 'model_type',
'type' : 'CATEGORICAL',
'categorical_value_spec' : {'values': ['LINEAR', 'WIDE_AND_DEEP']},
'child_parameter_specs' : [param_learning_rate, param_dnn_learning_rate,]
}
metric_accuracy = {
'metric' : 'accuracy',
'goal' : 'MAXIMIZE'
}
study_config = {
'algorithm' : 'ALGORITHM_UNSPECIFIED', # Let the service choose the `default` algorithm.
'parameters' : [param_model_type,],
'metrics' : [metric_accuracy,],
}
study = {'study_config': study_config}
print(json.dumps(study, indent=2, sort_keys=True))
Creare lo studio
A questo punto, crea lo studio che eseguirai successivamente per ottimizzare l'obiettivo.
# Creates a study
req = ml.projects().locations().studies().create(
parent=study_parent(), studyId=STUDY_ID, body=study)
try :
print(req.execute())
except errors.HttpError as e:
if e.resp.status == 409:
print('Study already existed.')
else:
raise e
Imposta i parametri di input/output
Imposta quindi i seguenti parametri di output.
OUTPUT_BUCKET e OUTPUT_DIR sono il bucket e la directory Cloud Storage utilizzati come "job_dir" per i job di AI Platform Training. OUTPUT_BUCKET deve essere un bucket nel progetto e OUTPUT_DIR è il nome che vuoi assegnare alla cartella di output nel bucket.
job_dir sarà nel formato "gs://$OUTPUT_BUCKET/$OUTPUT_DIR/"
TRAINING_DATA_PATH è il percorso del set di dati di addestramento di input.
# `job_dir` will be `gs://${OUTPUT_BUCKET}/${OUTPUT_DIR}/${job_id}`
OUTPUT_BUCKET = '[output-bucket-name]' #@param {type: 'string'}
OUTPUT_DIR = '[output-dir]' #@param {type: 'string'}
TRAINING_DATA_PATH = 'gs://caip-optimizer-public/sample-data/raw_census_train.csv' #@param {type: 'string'}
print('OUTPUT_BUCKET: {}'.format(OUTPUT_BUCKET))
print('OUTPUT_DIR: {}'.format(OUTPUT_DIR))
print('TRAINING_DATA_PATH: {}'.format(TRAINING_DATA_PATH))
# Create the bucket in Cloud Storage
! gcloud storage buckets create gs://$OUTPUT_BUCKET/ --project=$PROJECT_ID
Valutazione delle metriche
Questa sezione definisce i metodi per eseguire la valutazione di prova.
Per ogni prova, invia un job di algoritmo integrato di AI Platform per addestrare un modello di machine learning utilizzando gli iperparametri suggeriti da AI Platform Optimizer. Ogni job scrive il file di riepilogo del modello in Cloud Storage al termine dell'esecuzione. Puoi recuperare l'accuratezza del modello dalla directory dei job e riportarla come final_measurement della prova.
import logging
import math
import subprocess
import os
import yaml
from google.cloud import storage
_TRAINING_JOB_NAME_PATTERN = '{}_condition_parameters_{}_{}'
_IMAGE_URIS = {'LINEAR' : 'gcr.io/cloud-ml-algos/linear_learner_cpu:latest',
'WIDE_AND_DEEP' : 'gcr.io/cloud-ml-algos/wide_deep_learner_cpu:latest'}
_STEP_COUNT = 'step_count'
_ACCURACY = 'accuracy'
def EvaluateTrials(trials):
"""Evaluates trials by submitting training jobs to AI Platform Training service.
Args:
trials: List of Trials to evaluate
Returns: A dict of <trial_id, measurement> for the given trials.
"""
trials_by_job_id = {}
mesurement_by_trial_id = {}
# Submits a AI Platform Training job for each trial.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
model_type = _GetSuggestedParameterValue(trial, 'model_type', 'stringValue')
learning_rate = _GetSuggestedParameterValue(trial, 'learning_rate',
'floatValue')
dnn_learning_rate = _GetSuggestedParameterValue(trial, 'dnn_learning_rate',
'floatValue')
job_id = _GenerateTrainingJobId(model_type=model_type,
trial_id=trial_id)
trials_by_job_id[job_id] = {
'trial_id' : trial_id,
'model_type' : model_type,
'learning_rate' : learning_rate,
'dnn_learning_rate' : dnn_learning_rate,
}
_SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate)
# Waits for completion of AI Platform Training jobs.
while not _JobsCompleted(trials_by_job_id.keys()):
time.sleep(60)
# Retrieves model training result(e.g. global_steps, accuracy) for AI Platform Training jobs.
metrics_by_job_id = _GetJobMetrics(trials_by_job_id.keys())
for job_id, metric in metrics_by_job_id.items():
measurement = _CreateMeasurement(trials_by_job_id[job_id]['trial_id'],
trials_by_job_id[job_id]['model_type'],
trials_by_job_id[job_id]['learning_rate'],
trials_by_job_id[job_id]['dnn_learning_rate'],
metric)
mesurement_by_trial_id[trials_by_job_id[job_id]['trial_id']] = measurement
return mesurement_by_trial_id
def _CreateMeasurement(trial_id, model_type, learning_rate, dnn_learning_rate, metric):
if not metric[_ACCURACY]:
# Returns `none` for trials without metrics. The trial will be marked as `INFEASIBLE`.
return None
print(
'Trial {0}: [model_type = {1}, learning_rate = {2}, dnn_learning_rate = {3}] => accuracy = {4}'.format(
trial_id, model_type, learning_rate,
dnn_learning_rate if dnn_learning_rate else 'N/A', metric[_ACCURACY]))
measurement = {
_STEP_COUNT: metric[_STEP_COUNT],
'metrics': [{'metric': _ACCURACY, 'value': metric[_ACCURACY]},]}
return measurement
def _SubmitTrainingJob(job_id, trial_id, model_type, learning_rate, dnn_learning_rate=None):
"""Submits a built-in algo training job to AI Platform Training Service."""
try:
if model_type == 'LINEAR':
subprocess.check_output(_LinearCommand(job_id, learning_rate), stderr=subprocess.STDOUT)
elif model_type == 'WIDE_AND_DEEP':
subprocess.check_output(_WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate), stderr=subprocess.STDOUT)
print('Trial {0}: Submitted job [https://console.cloud.google.com/ai-platform/jobs/{1}?project={2}].'.format(trial_id, job_id, PROJECT_ID))
except subprocess.CalledProcessError as e:
logging.error(e.output)
def _GetTrainingJobState(job_id):
"""Gets a training job state."""
cmd = ['gcloud', 'ai-platform', 'jobs', 'describe', job_id,
'--project', PROJECT_ID,
'--format', 'json']
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT, timeout=3)
except subprocess.CalledProcessError as e:
logging.error(e.output)
return json.loads(output)['state']
def _JobsCompleted(jobs):
"""Checks if all the jobs are completed."""
all_done = True
for job in jobs:
if _GetTrainingJobState(job) not in ['SUCCEEDED', 'FAILED', 'CANCELLED']:
print('Waiting for job[https://console.cloud.google.com/ai-platform/jobs/{0}?project={1}] to finish...'.format(job, PROJECT_ID))
all_done = False
return all_done
def _RetrieveAccuracy(job_id):
"""Retrices the accuracy of the trained model for a built-in algorithm job."""
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.get_bucket(OUTPUT_BUCKET)
blob_name = os.path.join(OUTPUT_DIR, job_id, 'model/deployment_config.yaml')
blob = storage.Blob(blob_name, bucket)
try:
blob.reload()
content = blob.download_as_string()
accuracy = float(yaml.safe_load(content)['labels']['accuracy']) / 100
step_count = int(yaml.safe_load(content)['labels']['global_step'])
return {_STEP_COUNT: step_count, _ACCURACY: accuracy}
except:
# Returns None if failed to load the built-in algo output file.
# It could be due to job failure and the trial will be `INFEASIBLE`
return None
def _GetJobMetrics(jobs):
accuracies_by_job_id = {}
for job in jobs:
accuracies_by_job_id[job] = _RetrieveAccuracy(job)
return accuracies_by_job_id
def _GetSuggestedParameterValue(trial, parameter, value_type):
param_found = [p for p in trial['parameters'] if p['parameter'] == parameter]
if param_found:
return param_found[0][value_type]
else:
return None
def _GenerateTrainingJobId(model_type, trial_id):
return _TRAINING_JOB_NAME_PATTERN.format(STUDY_ID, model_type, trial_id)
def _GetJobDir(job_id):
return os.path.join('gs://', OUTPUT_BUCKET, OUTPUT_DIR, job_id)
def _LinearCommand(job_id, learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['LINEAR'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--model_type=classification',
'--batch_size=250',
'--max_steps=1000',
'--learning_rate={}'.format(learning_rate),
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
def _WideAndDeepCommand(job_id, learning_rate, dnn_learning_rate):
return ['gcloud', 'ai-platform', 'jobs', 'submit', 'training', job_id,
'--scale-tier', 'BASIC',
'--region', 'us-central1',
'--master-image-uri', _IMAGE_URIS['WIDE_AND_DEEP'],
'--project', PROJECT_ID,
'--job-dir', _GetJobDir(job_id),
'--',
'--preprocess',
'--test_split=0',
'--use_wide',
'--embed_categories',
'--model_type=classification',
'--batch_size=250',
'--learning_rate={}'.format(learning_rate),
'--dnn_learning_rate={}'.format(dnn_learning_rate),
'--max_steps=1000',
'--training_data_path={}'.format(TRAINING_DATA_PATH)]
Configurazione per la richiesta di suggerimenti/prove
client_id: l'identificatore del client che richiede il suggerimento. Se più richieste di suggerimenti per le prove hanno lo stesso client_id, il servizio restituirà la prova suggerita identica se la prova è PENDING e fornirà una nuova prova se l'ultima prova suggerita è stata completata.
suggestion_count_per_request: il numero di suggerimenti (prove) richiesti in una singola richiesta.
max_trial_id_to_stop: il numero di prove da esplorare prima dell'interruzione. È impostato su 4 per ridurre il tempo di esecuzione del codice, quindi non aspettarti una convergenza. Per la convergenza, probabilmente dovrebbe essere di circa 20 (una buona regola empirica è moltiplicare la dimensionalità totale per 10).
client_id = 'client1' #@param {type: 'string'}
suggestion_count_per_request = 2 #@param {type: 'integer'}
max_trial_id_to_stop = 4 #@param {type: 'integer'}
print('client_id: {}'.format(client_id))
print('suggestion_count_per_request: {}'.format(suggestion_count_per_request))
print('max_trial_id_to_stop: {}'.format(max_trial_id_to_stop))
Richiedere ed eseguire prove di AI Platform Optimizer
Esegui le prove.
current_trial_id = 0
while current_trial_id < max_trial_id_to_stop:
# Request trials
resp = ml.projects().locations().studies().trials().suggest(
parent=trial_parent(STUDY_ID),
body={'client_id': client_id, 'suggestion_count': suggestion_count_per_request}).execute()
op_id = resp['name'].split('/')[-1]
# Polls the suggestion long-running operations.
get_op = ml.projects().locations().operations().get(name=operation_name(op_id))
while True:
operation = get_op.execute()
if 'done' in operation and operation['done']:
break
time.sleep(1)
# Featches the suggested trials.
trials = []
for suggested_trial in get_op.execute()['response']['trials']:
trial_id = int(suggested_trial['name'].split('/')[-1])
trial = ml.projects().locations().studies().trials().get(name=trial_name(STUDY_ID, trial_id)).execute()
if trial['state'] not in ['COMPLETED', 'INFEASIBLE']:
print("Trial {}: {}".format(trial_id, trial))
trials.append(trial)
# Evaluates trials - Submit model training jobs using AI Platform Training built-in algorithms.
measurement_by_trial_id = EvaluateTrials(trials)
# Completes trials.
for trial in trials:
trial_id = int(trial['name'].split('/')[-1])
current_trial_id = trial_id
measurement = measurement_by_trial_id[trial_id]
print(("=========== Complete Trial: [{0}] =============").format(trial_id))
if measurement:
# Completes trial by reporting final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'final_measurement' : measurement}).execute()
else:
# Marks trial as `infeasbile` if when missing final measurement.
ml.projects().locations().studies().trials().complete(
name=trial_name(STUDY_ID, trial_id),
body={'trial_infeasible' : True}).execute()
[FACOLTATIVO] Creare prove utilizzando i tuoi parametri
Oltre a richiedere suggerimenti (metodo suggest) dei parametri dal servizio, l'API di AI Platform Optimizer consente agli utenti di creare prove (metodo suggest) utilizzando i propri parametri.create AI Platform Optimizer contribuirà a registrare gli esperimenti eseguiti dagli utenti e a utilizzare le informazioni per generare nuovi suggerimenti.
Ad esempio, se esegui un job di addestramento del modello utilizzando i tuoi model_type e learning_rate anziché quelli suggeriti da AI Platform Optimizer, puoi creare una prova per il job nell'ambito dello studio.
# User has to leave `trial.name` unset in CreateTrial request, the service will
# assign it.
custom_trial = {
"clientId": "client1",
"finalMeasurement": {
"metrics": [
{
"metric": "accuracy",
"value": 0.86
}
],
"stepCount": "1000"
},
"parameters": [
{
"parameter": "model_type",
"stringValue": "LINEAR"
},
{
"floatValue": 0.3869103706121445,
"parameter": "learning_rate"
}
],
"state": "COMPLETED"
}
trial = ml.projects().locations().studies().trials().create(
parent=trial_parent(STUDY_ID), body=custom_trial).execute()
print(json.dumps(trial, indent=2, sort_keys=True))
Elenca le prove
Elenca i risultati di ogni addestramento di prova di ottimizzazione.
resp = ml.projects().locations().studies().trials().list(parent=trial_parent(STUDY_ID)).execute()
print(json.dumps(resp, indent=2, sort_keys=True))
Pulizia
Per eliminare tutte le risorse Google Cloud utilizzate in questo progetto, puoi eliminare il progetto Google Cloud utilizzato per il tutorial.