Architecture
Le schéma suivant illustre l'architecture de haut niveau d'un pipeline d'extraction, chargement et transformation sans serveur utilisant Workflows.

Dans le schéma précédent, considérons une plate-forme de vente au détail qui collecte régulièrement des événements de vente sous forme de fichiers depuis divers magasins, puis écrit les fichiers dans un bucket Cloud Storage. Les événements permettent de fournir des métriques commerciales via l'importation et le traitement des données dans BigQuery. Cette architecture fournit un système d'orchestration fiable et sans serveur pour importer vos fichiers dans BigQuery. Elle se divise en deux modules :
- Liste de fichiers : gère la liste des fichiers non traités ajoutés à un bucket Cloud Storage dans une collection Firestore.
Ce module fonctionne via une fonction Cloud Run déclenchée par un événement de stockage Object Finalize (Finalisation de l'objet), lequel est généré lorsqu'un nouveau fichier est ajouté au bucket Cloud Storage. Le nom de fichier est ajouté au tableau
filesde la collection nomméenewdans Firestore. Workflow : exécute les workflows planifiés. Cloud Scheduler déclenche un workflow qui exécute une série d'étapes selon une syntaxe basée sur YAML pour orchestrer le chargement, puis transformer les données dans BigQuery en appelant Cloud Run Functions. Les étapes du workflow appellent Cloud Run Functions pour exécuter les tâches suivantes :
- Créer et démarrer une tâche de chargement BigQuery.
- Interroger l'état de la tâche de chargement.
- Créer et démarrer la tâche de requête de transformation.
- Interroger l'état de la tâche de transformation.
L'utilisation de transactions pour gérer la liste des nouveaux fichiers dans Firestore permet de garantir qu'aucun fichier ne manque lorsqu'un workflow les importe dans BigQuery. Les exécutions distinctes du workflow deviennent idempotentes lorsque vous stockez les métadonnées et l'état de la tâche dans Firestore.
Préparer votre environnement
Pour préparer votre environnement, créez une base de données Firestore, clonez les exemples de code du dépôt GitHub, créez des ressources à l'aide de Terraform, modifiez le fichier YAML Workflows et installez les exigences pour le générateur de fichiers.
Pour créer une base de données Firestore, procédez comme suit :
Dans la console Google Cloud , accédez à la page Firestore.
Cliquez sur Sélectionner le mode natif.
Dans le menu Sélectionner un emplacement, sélectionnez la région dans laquelle vous souhaitez héberger la base de données Firestore. Nous vous recommandons de choisir une région proche de votre emplacement physique.
Cliquez sur Créer une base de données.
Dans Cloud Shell, clonez le dépôt source :
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadDans Cloud Shell, créez les ressources suivantes à l'aide de Terraform :
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveRemplacez les éléments suivants :
PROJECT_ID: ID de votre projet Google CloudREGION: emplacement géographique Google Cloudspécifique dans lequel héberger vos ressources, par exempleus-central1ZONE: emplacement d'une région dans laquelle héberger vos ressources (par exemple,us-central1-b)
Un message semblable au suivant doit s'afficher :
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform peut vous aider à créer, modifier et mettre à niveau une infrastructure à grande échelle de manière sécurisée et prévisible. Les ressources suivantes sont créées dans votre projet :
- Des comptes de service disposant des droits requis pour garantir un accès sécurisé à vos ressources
- Un ensemble de données BigQuery nommé
serverless_elt_datasetet une table nomméeword_countpour charger les fichiers entrants - Un bucket Cloud Storage nommé
${project_id}-ordersbucketpour les fichiers d'entrée de préproduction - Les cinq fonctions Cloud Run suivantes :
file_add_handlerajoute le nom des fichiers intégrés au bucket Cloud Storage dans la collection Firestore.create_jobcrée une tâche de chargement BigQuery et associe les fichiers de la collection Firebase avec la tâche.create_querycrée une requête BigQuery.poll_bigquery_jobobtient l'état d'une tâche BigQuery.run_bigquery_jobdémarre une tâche BigQuery.
Récupérez les URL des fonctions Cloud Run
create_job,create_query,poll_jobetrun_bigquery_jobque vous avez déployées à l'étape précédente.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
Le résultat ressemble à ce qui suit :
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Notez ces URL, car vous en aurez besoin lorsque vous déploierez votre workflow.
Créer et déployer un workflow
Dans Cloud Shell, ouvrez le fichier source du workflow,
workflow.yaml:Remplacez les éléments suivants :
CREATE_JOB_URL: URL de la fonction permettant de créer un jobPOLL_BIGQUERY_JOB_URL: URL de la fonction permettant d'interroger l'état d'une tâche en cours d'exécutionRUN_BIGQUERY_JOB_URL: URL de la fonction permettant de démarrer une tâche de chargement BigQueryCREATE_QUERY_URL: URL de la fonction permettant de démarrer une requête BigQueryBQ_REGION: région BigQuery dans laquelle les données sont stockées, par exempleUS.BQ_DATASET_TABLE_NAME: nom de la table de l'ensemble de données BigQuery au formatPROJECT_ID.serverless_elt_dataset.word_count
Déployez le fichier
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlRemplacez les éléments suivants :
WORKFLOW_NAME: nom unique du workflowWORKFLOW_REGION: région dans laquelle le workflow est déployé (par exemple,us-central1).WORKFLOW_DESCRIPTION: description du workflow.
Créez un environnement virtuel Python 3 et installez les éléments requis pour le générateur de fichiers :
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Générer des fichiers à importer
Le script Python gen.py génère un contenu aléatoire au format Avro. Le schéma est identique à la table BigQuery word_count. Ces fichiers Avro sont copiés dans le bucket Cloud Storage spécifié.
Dans Cloud Shell, générez les fichiers :
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
Remplacez les éléments suivants :
RECORDS_PER_FILE: nombre d'enregistrements dans un seul fichierNUM_FILES: nombre total de fichiers à importerFILE_PREFIX: préfixe des noms des fichiers générés
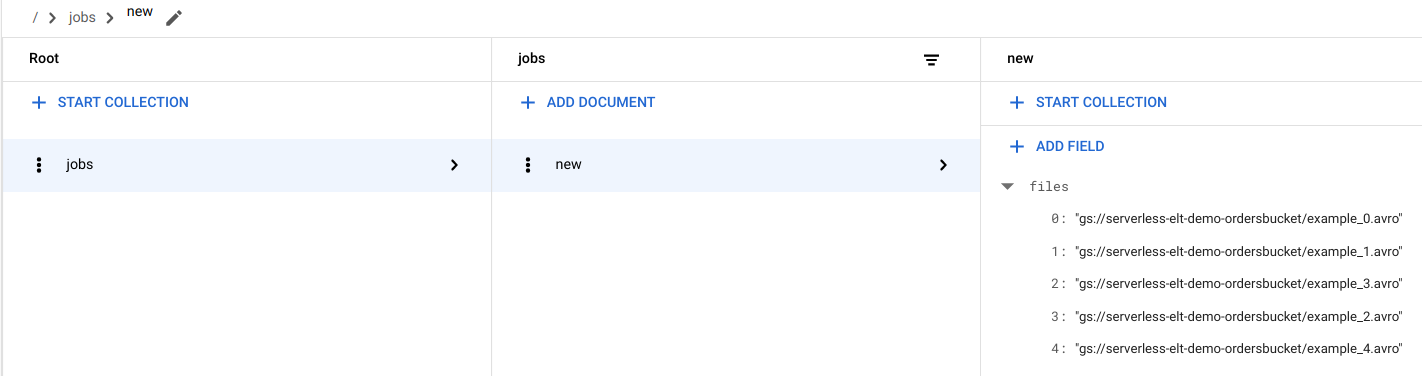
Afficher les entrées de fichier dans Firestore
Lorsque les fichiers sont copiés dans Cloud Storage, la fonction Cloud Run handle_new_file est déclenchée. Cette fonction ajoute la liste de fichiers au tableau de liste de fichiers dans le document new de la collection jobs dans Firestore.
Pour afficher la liste des fichiers, accédez à la page Données Firestore dans la console Google Cloud .
Déclencher le workflow
Workflows associe une série de tâches sans serveur provenant deGoogle Cloud et de services d'API. Les étapes individuelles de ce workflow s'exécutent en tant que fonctions Cloud Run et l'état est stocké dans Firestore. Tous les appels à Cloud Run Functions sont authentifiés à l'aide du compte de service du workflow.
Dans Cloud Shell, exécutez le workflow suivant :
gcloud workflows execute WORKFLOW_NAME
Le schéma suivant illustre les étapes utilisées dans le workflow :

Le workflow se divise en deux parties : le workflow principal et le sous-workflow. Le workflow principal gère la création de tâches et l'exécution conditionnelle, tandis que le sous-workflow exécute une tâche BigQuery. Le workflow effectue les opérations suivantes :
- La fonction Cloud Run
create_jobcrée un objet de tâche, récupère la liste des fichiers ajoutés à Cloud Storage à partir du document Firestore, puis associe les fichiers à la tâche de chargement. S'il n'y a pas de fichiers à charger, la fonction ne crée pas de job. - La fonction Cloud Run
create_queryassocie la requête devant être exécutée avec la région BigQuery dans laquelle la requête doit être exécutée. La fonction crée la tâche dans Firestore et renvoie l'ID de la tâche. - La fonction Cloud Run
run_bigquery_jobobtient l'ID du job qui doit être exécuté, puis appelle l'API BigQuery pour envoyer le job. - Au lieu d'attendre la fin de la tâche dans la fonction Cloud Run, vous pouvez interroger régulièrement son état.
- La fonction Cloud Run
poll_bigquery_jobfournit l'état du job. Elle est appelée à plusieurs reprises jusqu'à la fin de la tâche. - Pour ajouter un délai entre les appels à la fonction Cloud Run
poll_bigquery_job, une routinesleepest appelée à partir des Workflows.
- La fonction Cloud Run
Afficher l'état de la tâche
Vous pouvez afficher la liste des fichiers et l'état du job.
Dans la consoleGoogle Cloud , accédez à la page Données de Firestore.
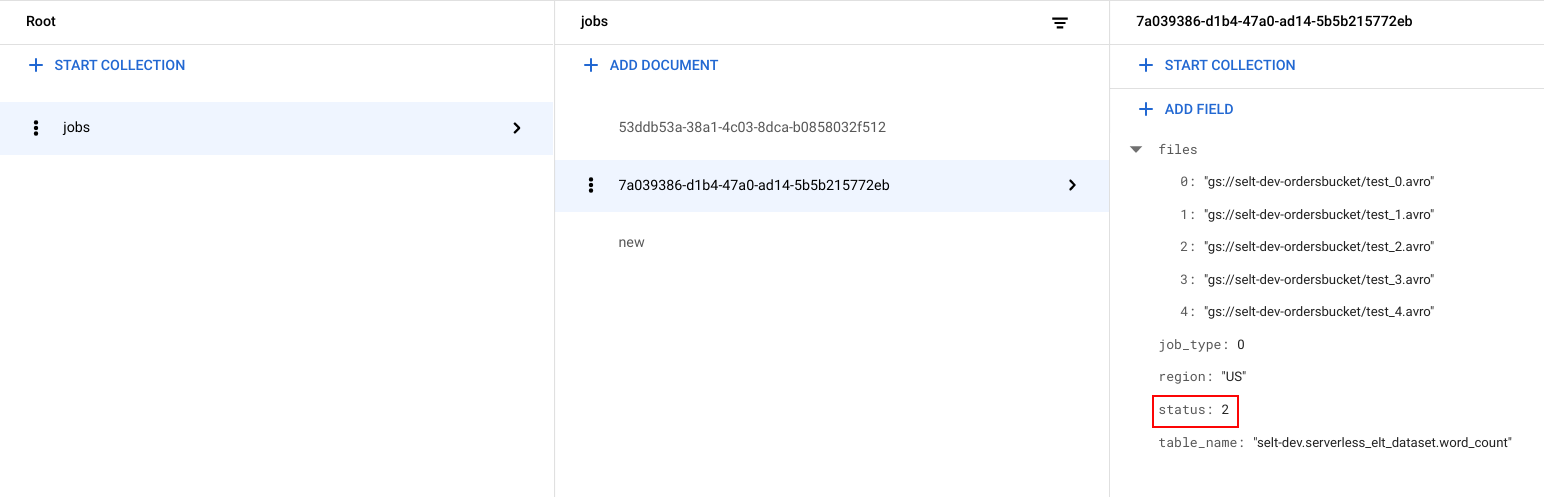
Un identifiant unique (UUID) est généré pour chaque tâche. Pour afficher les en-têtes
job_typeetstatus, cliquez sur l'ID de la tâche. Une tâche peut être de l'un des types suivants, et se trouver dans l'un des états suivants :job_type: type de tâche en cours d'exécution par le workflow avec l'une des valeurs suivantes :- 0 : charger les données dans BigQuery.
- 1 : exécuter une requête dans BigQuery.
status: état actuel de la tâche avec l'une des valeurs suivantes :- 0 : la tâche a été créée, mais n'a pas démarré.
- 1 : la tâche est en cours d'exécution.
- 2 : la tâche a bien été exécutée.
- 3 : une erreur s'est produite et la tâche n'a pas abouti.
L'objet de tâche contient également des attributs de métadonnées tels que la région de l'ensemble de données BigQuery, le nom de la table BigQuery et, s'il s'agit d'une tâche de requête, la chaîne de requête en cours d'exécution.
Consulter les données dans BigQuery
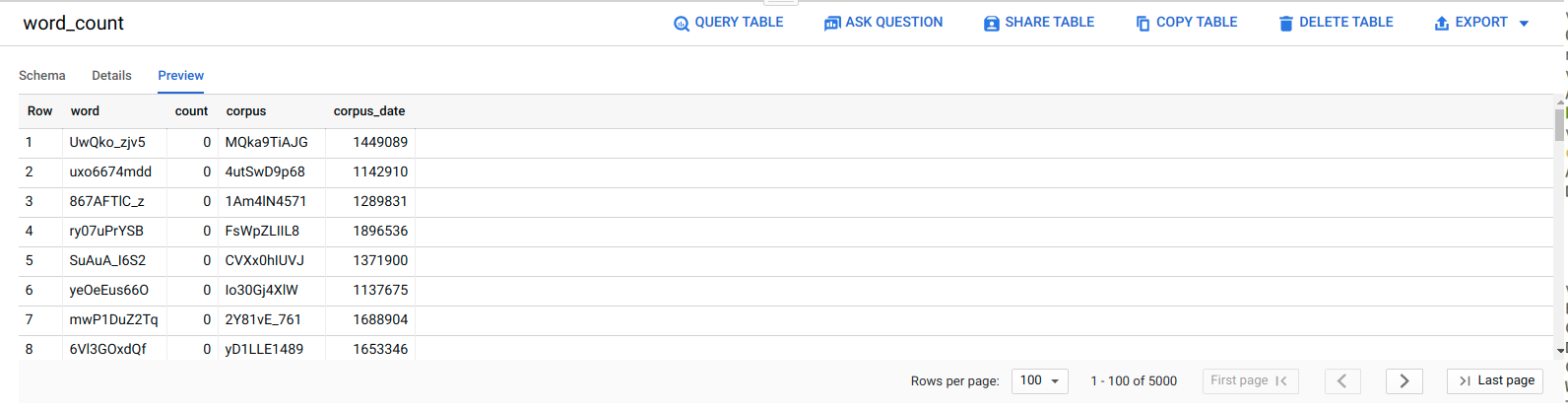
Pour vérifier que la tâche ELT a abouti, vérifiez que les données apparaissent dans la table.
Dans la console Google Cloud , accédez à la page Éditeur de BigQuery.
Cliquez sur la table
serverless_elt_dataset.word_count.Cliquez sur l'onglet Preview (Aperçu).
Planifier le workflow
Pour exécuter régulièrement le workflow de manière planifiée, vous pouvez utiliser Cloud Scheduler.