このページでは、Vertex AI RAG Engine の概要と動作について説明します。
| 説明 | コンソール |
|---|---|
| Vertex AI SDK を使用して Vertex AI RAG Engine タスクを実行する方法については、Python の RAG クイックスタートをご覧ください。 |
概要
Vertex AI RAG Engine は Vertex AI Platform のコンポーネントであり、検索拡張生成(RAG)を容易にします。Vertex AI RAG Engine は、コンテキスト拡張型大規模言語モデル(LLM)アプリケーションを開発するためのデータ フレームワークでもあります。コンテキストの拡張は、LLM をデータに適用するときに行われます。これは、検索拡張生成(RAG)を実装します。
LLM の一般的な問題は、プライベート データ(組織のデータ)を理解していないことです。Vertex AI RAG Engine を使用すると、追加の非公開情報で LLM のコンテキストを拡充できます。これは、モデルがハルシネーションを低減し、質問に正確に答えることができるためです。
追加の情報源と LLM が持つ既存の知識を組み合わせることで、より優れたコンテキストが提供されます。クエリとともにコンテキストが改善されることで、LLM のレスポンスの品質が向上します。
次の図は、Vertex AI RAG Engine を理解するための主なコンセプトを示しています。
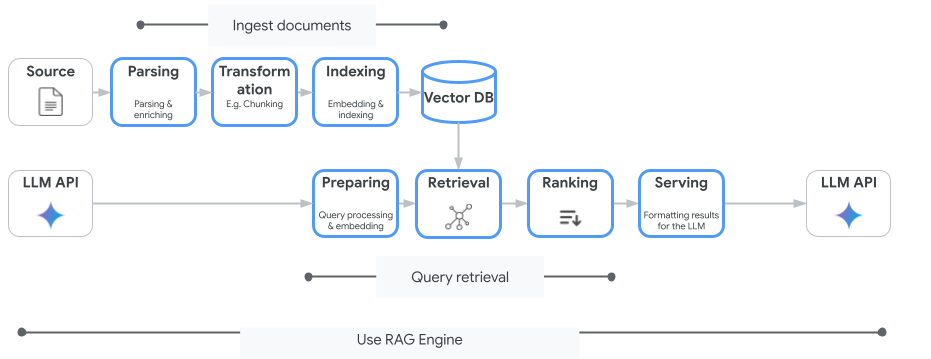
これらのコンセプトは、検索拡張生成(RAG)プロセスの順序で記載されています。
データの取り込み: さまざまなデータソースからデータを取得します。たとえば、ローカル ファイル、Cloud Storage、Google ドライブが該当します。
データ変換: インデックス登録の準備としてデータを変換します。たとえば、データはチャンクに分割されます。
エンベディング: 単語やテキストの断片の数値表現。これらの数値は、テキストの意味論的意味とコンテキストを捉えています。類似または関連する単語やテキストは、エンベディングが類似する傾向があります。つまり、高次元ベクトル空間内で近接します。
データのインデックス登録: Vertex AI RAG Engine は、コーパスと呼ばれるインデックスを作成します。インデックスは、検索用に最適化されるようにナレッジベースを構造化します。たとえば、インデックスは、膨大な参考書の詳細な目次のようなものです。
取得: ユーザーが質問をするか、プロンプトを指定すると、Vertex AI RAG Engine の検索コンポーネントがナレッジベースを検索し、クエリに関連する情報を探します。
生成: 取得した情報は、生成 AI モデルが事実に基づいた関連性の高いレスポンスを生成するためのガイドとして、元のユーザークエリに追加されるコンテキストになります。
サポートされているリージョン
Vertex AI RAG Engine は、次のリージョンでサポートされています。
| リージョン | ロケーション | 説明 | リリース ステージ |
|---|---|---|---|
us-central1 |
アイオワ | v1 バージョンと v1beta1 バージョンがサポートされています。 |
許可リスト |
us-east4 |
バージニア | v1 バージョンと v1beta1 バージョンがサポートされています。 |
GA |
europe-west3 |
フランクフルト(ドイツ) | v1 バージョンと v1beta1 バージョンがサポートされています。 |
GA |
europe-west4 |
エームスハーヴェン(オランダ) | v1 バージョンと v1beta1 バージョンがサポートされています。 |
GA |
us-central1がAllowlistに変更されました。Vertex AI RAG Engine を試す場合は、他のリージョンをお試しください。本番環境のトラフィックをus-central1にオンボーディングする予定がある場合は、vertex-ai-rag-engine-support@google.comにお問い合わせください。
Vertex AI RAG Engine を削除する
次のコードサンプルは、 Google Cloud コンソール、Python、REST で Vertex AI RAG Engine を削除する方法を示しています。
フィードバックを送信する
Google サポートとチャットするには、Vertex AI RAG Engine サポート グループにアクセスしてください。
メールを送信するには、メールアドレス vertex-ai-rag-engine-support@google.com を使用します。
次のステップ
- Vertex AI SDK を使用して Vertex AI RAG Engine タスクを実行する方法について、Python の RAG クイックスタートで学習する。
- グラウンディングについて、グラウンディングの概要で確認する。
- RAG からのレスポンスの詳細については、Vertex AI RAG Engine の検索と生成の出力をご覧ください。
- RAG アーキテクチャについて確認するには: