En esta página se presenta la recuperación tras fallos en Cloud SQL.
Información general
En Google Cloud, la recuperación tras desastres (DR) de bases de datos consiste en proporcionar continuidad del procesamiento, sobre todo cuando una región falla o deja de estar disponible. Cloud SQL es un servicio regional (cuando Cloud SQL está configurado para alta disponibilidad). Por lo tanto, si la región de Google Cloud que aloja una base de datos de Cloud SQL no está disponible, la base de datos de Cloud SQL tampoco lo estará.
Para continuar con el procesamiento, debes hacer que la base de datos esté disponible en una región secundaria lo antes posible. El plan de recuperación tras desastres requiere que configures una réplica de lectura entre regiones en Cloud SQL. También se puede realizar una conmutación por error basada en la exportación o importación, o en la copia de seguridad o restauración, pero este método lleva más tiempo, sobre todo en el caso de bases de datos de gran tamaño.
Los siguientes casos prácticos de empresas son ejemplos que justifican una configuración de conmutación por error entre regiones:
- El acuerdo de nivel de servicio de la aplicación empresarial es superior al acuerdo de nivel de servicio de Cloud SQL regional (99,99% de disponibilidad en función de tu edición de Cloud SQL). Si cambias a otra región, puedes mitigar una interrupción.
- Todos los niveles de la aplicación empresarial ya son multirregionales y pueden seguir procesando datos cuando se produce una interrupción en una región. La configuración de conmutación por error entre regiones ayuda a mantener la disponibilidad de una base de datos.
- El objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) necesarios se miden en minutos en lugar de en horas. La conmutación por error a otra región es más rápida que la recreación de una base de datos.
En general, hay dos variantes del proceso de recuperación ante desastres:
- Una base de datos pasa a una región secundaria. Una vez que la base de datos esté lista y la use una aplicación, se convertirá en la nueva base de datos principal y seguirá siéndolo.
- Una base de datos pasa a una región secundaria, pero vuelve a la región principal después de que esta se recupere de un fallo.
En esta Google Cloud descripción general de la recuperación tras fallos de bases de datos SQL se describe la segunda variante, en la que se recupera una base de datos que ha fallado y se vuelve a la región principal. Esta variante del proceso de recuperación ante desastres es especialmente útil para las bases de datos que deben ejecutarse en la región principal debido a la latencia de la red o porque algunos recursos solo están disponibles en la región principal. Con esta variante, la base de datos se ejecuta en la región secundaria solo durante el tiempo que dure la interrupción en la región principal.
Arquitectura de recuperación tras fallos
En el siguiente diagrama se muestra la arquitectura mínima que admite la recuperación ante desastres de la base de datos de una instancia de Cloud SQL de alta disponibilidad:
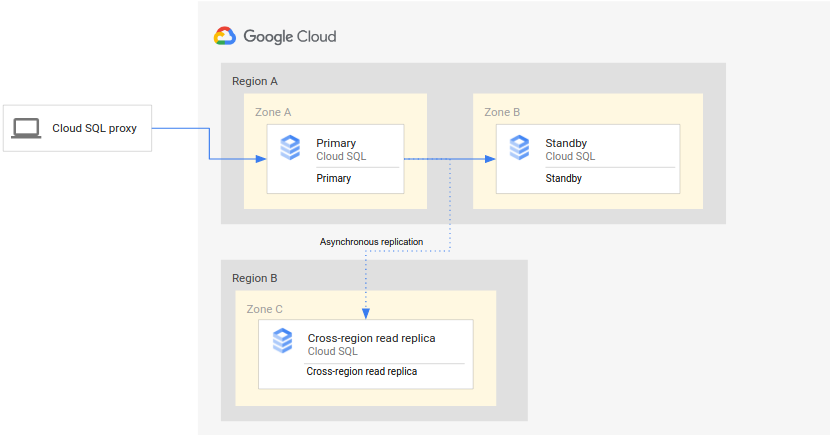
La arquitectura funciona de la siguiente manera:
- Dos instancias de Cloud SQL (una principal y otra de espera) se encuentran en dos zonas independientes de una misma región (la región principal). Las instancias se sincronizan mediante discos persistentes regionales.
- Una instancia de Cloud SQL (la réplica de lectura interregional) se encuentra en una segunda región (la región secundaria). En el caso de la recuperación ante desastres, la réplica de lectura entre regiones se configura para sincronizarse (mediante la replicación asíncrona) con la instancia principal mediante una configuración de réplica de lectura.
Las instancias principal y de espera comparten el mismo disco regional, por lo que sus estados son idénticos.
Como esta configuración usa la replicación asíncrona, es posible que la réplica de lectura entre regiones se retrase con respecto a la instancia principal. Por lo tanto, cuando se produce una conmutación por error, es probable que el RPO de la réplica de lectura entre regiones no sea cero.
Proceso de recuperación tras fallos
El proceso de recuperación tras fallos (DR) se inicia cuando la región principal deja de estar disponible. Para reanudar el procesamiento en una región secundaria, debes activar una conmutación por error de la instancia principal promocionando una réplica de lectura entre regiones. El proceso de recuperación ante desastres prescribe los pasos operativos que se deben llevar a cabo, ya sea de forma manual o automática, para mitigar el fallo de la región y establecer una instancia principal en funcionamiento en una región secundaria.
En el siguiente diagrama se muestra el proceso de recuperación ante desastres:
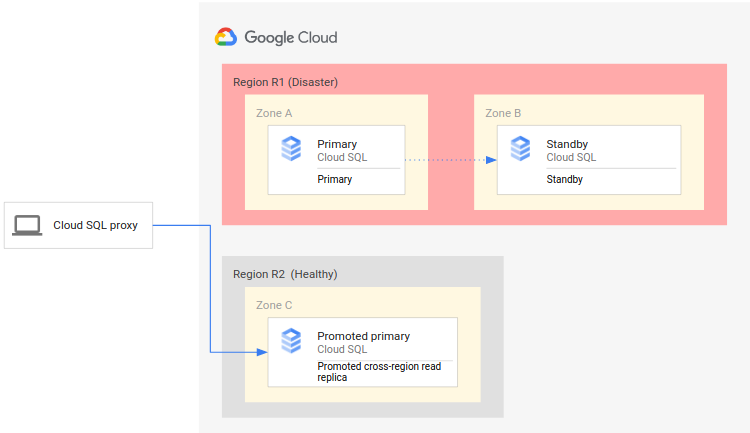
El proceso de recuperación ante desastres consta de los siguientes pasos:
- La región principal (R1), en la que se ejecuta la instancia principal, deja de estar disponible.
- El equipo de Operaciones reconoce formalmente el desastre y decide si es necesario realizar una conmutación por error.
- Si es necesario realizar una conmutación por error, puedes promocionar la réplica de lectura entre regiones de la región secundaria (R2) para que sea la nueva instancia principal.
- Las conexiones de cliente se vuelven a configurar para reanudar el procesamiento en la nueva instancia principal y acceder a la instancia principal en R2.
Este proceso inicial vuelve a establecer una base de datos principal operativa. Sin embargo, no establece una arquitectura de recuperación ante desastres completa, en la que la nueva instancia principal tiene una instancia de espera y una réplica de lectura entre regiones.
Un proceso de recuperación ante desastres completo asegura que la instancia única, la nueva principal, tenga habilitada la alta disponibilidad y una réplica de lectura entre regiones. Un proceso de recuperación ante desastres completo también proporciona una alternativa a la implementación original en la región principal original.
Conmutación por error a una región secundaria
Un proceso de recuperación ante desastres completo amplía el proceso básico añadiendo pasos para establecer una arquitectura de recuperación ante desastres completa después de la conmutación por error. En el siguiente diagrama se muestra una arquitectura de recuperación tras desastres de base de datos completa después de la conmutación por error:
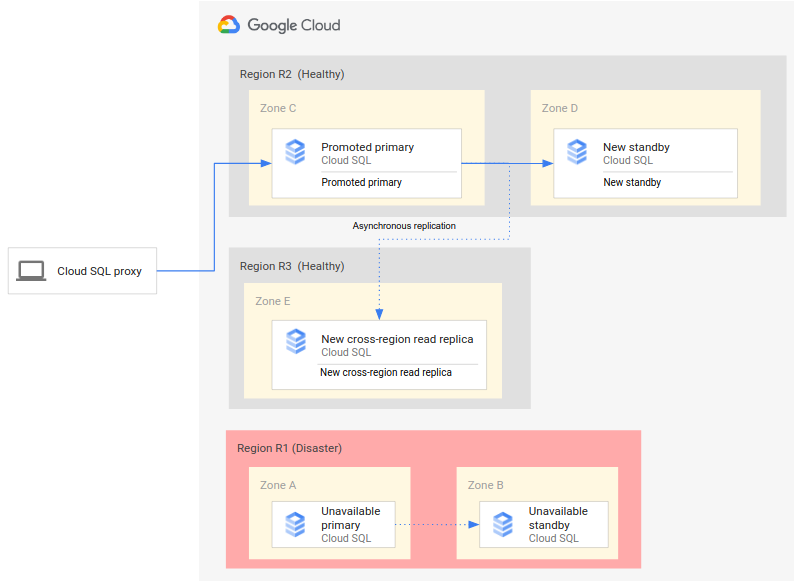
El proceso completo de recuperación ante desastres de la base de datos consta de los siguientes pasos:
- La región principal (R1), que ejecuta la base de datos principal, deja de estar disponible.
- El equipo de Operaciones reconoce formalmente el desastre y decide si es necesario realizar una conmutación por error.
- Si es necesario realizar una conmutación por error, puedes promocionar la réplica de lectura entre regiones de la región secundaria (R2) para que sea la nueva instancia principal.
- Las conexiones de cliente se vuelven a configurar para acceder y procesar en la nueva instancia principal (R2).
- Se crea y se inicia una nueva instancia de espera en R2, que se añade a la instancia principal. La instancia de espera está en una zona diferente a la de la instancia principal. La instancia principal ahora tiene alta disponibilidad porque se ha creado una instancia de espera.
- En una tercera región (R3), se crea una réplica de lectura entre regiones y se adjunta a la instancia principal. En este punto, se habrá recreado una arquitectura completa de recuperación tras desastres y estará operativa.
Si la región principal original (R1) vuelve a estar disponible antes de que se implemente el paso 6, la réplica de lectura entre regiones se puede colocar en la región R1, en lugar de en la región R3, inmediatamente. En este caso, la conmutación por error a la región principal original (R1) es menos compleja y requiere menos pasos.
Evitar un estado de cerebro dividido
Si se produce un fallo en la región principal (R1), no significa que la instancia principal original y su instancia de espera se apaguen, se eliminen o se hagan inaccesibles automáticamente cuando R1 vuelva a estar disponible. Si R1 vuelve a estar disponible, los clientes podrían leer y escribir datos (incluso por accidente) en la instancia principal original. En este caso, se puede producir una situación de cerebro dividido, en la que algunos clientes acceden a datos obsoletos de la antigua base de datos principal y otros acceden a datos actualizados de la nueva base de datos principal, lo que puede provocar problemas en tu empresa.
Para evitar una situación de cerebro dividido, debes asegurarte de que los clientes ya no puedan acceder a la instancia principal original después de que R1 esté disponible. Lo ideal es que hagas que la instancia principal original sea inaccesible antes de que los clientes empiecen a usar la nueva instancia principal y, a continuación, elimines la instancia principal original.
Crear una copia de seguridad inicial después de una conmutación por error
Cuando promocionas la réplica de lectura entre regiones para que sea la nueva principal en una conmutación por error, es posible que las transacciones de la nueva principal no estén totalmente sincronizadas con las transacciones de la principal original. Por lo tanto, esas transacciones no están disponibles en la nueva instancia.
Como práctica recomendada, le aconsejamos que cree una copia de seguridad de la nueva instancia principal inmediatamente al inicio de la conmutación por error y antes de que los clientes accedan a la base de datos. Esta copia de seguridad representa un estado coherente y conocido en el momento de la conmutación por error. Estas copias de seguridad pueden ser importantes por motivos normativos o para volver a un estado conocido si los clientes tienen problemas al acceder al nuevo elemento principal.
Volver a la región principal original
Como se ha indicado anteriormente, en este documento se describen los pasos para volver a la región original (R1). Hay dos versiones diferentes del proceso de reserva.
- Si has creado la réplica de lectura entre regiones en una región terciaria (R3), debes crear otra réplica de lectura entre regiones (la segunda) en la región principal (R1).
- Si has creado la réplica de lectura entre regiones en la región principal (R1), no es necesario que crees otra réplica de lectura entre regiones en R1.
Una vez que se haya creado la réplica de lectura entre regiones en R1, la instancia de Cloud SQL podrá volver a R1. Como esta alternativa se activa manualmente y no se basa en una interrupción, puedes elegir el día y la hora adecuados para esta actividad de mantenimiento.
Por lo tanto, para conseguir una recuperación ante desastres completa que tenga una réplica de lectura principal, una de espera y una entre regiones, necesitas dos conmutaciones por error. La primera conmutación por error se activa por la interrupción (una conmutación por error real) y la segunda restablece la implementación inicial (una conmutación por error).
La recuperación de la región principal original (R1) consta de los siguientes pasos:
- Promueve la réplica interregional recién creada en la región principal original (R1).
- Vuelve a configurar tus aplicaciones para que se conecten a la nueva instancia principal.
- Crea una réplica entre regiones para la nueva instancia principal en la región de recuperación ante desastres (R2).
- (Opcional) Para evitar que se ejecuten varias instancias principales independientes, limpia la instancia principal de la región de recuperación ante desastres (R2).
Réplicas en cascada
Cloud SQL te permite crear réplicas para realizar pruebas de recuperación tras fallos y para situaciones de recuperación entre regiones. Puedes crear una réplica con la marca cascadable-replica en una región diferente a la de su instancia principal. Si se produce un desastre en la región de la instancia principal, puedes iniciar la conmutación por error a la réplica en cascada.
Cuando la instancia principal original vuelva a estar online y funcione como una réplica correcta, puedes usar la operación de cambio para volver a la instancia principal original.
Una réplica en cascada tiene dos funciones adicionales que no tienen otras réplicas de lectura:
- Puedes adjuntar réplicas de lectura adicionales (réplicas en cascada) a la réplica de lectura en cascada. Cloud SQL envía el tráfico de replicación entre regiones a la réplica en cascada solo una vez y, a continuación, la réplica en cascada reenvía el tráfico a sus réplicas de la misma región. Esta arquitectura puede ahorrar costes de transferencia de datos de red entre regiones cuando necesites tener varias réplicas en otra región.
- Puedes usar la réplica de lectura en cascada como destino de las operaciones de cambio y conmutación por error en escenarios de recuperación tras fallos entre regiones. Estas operaciones reconfiguran la réplica en cascada para que sea la instancia principal de un clúster.
Puedes probar la recuperación ante desastres de dos formas:
- Promoción de tu réplica
- Recuperación tras desastres avanzada
Recuperación tras fallos avanzada
Si usas la edición Enterprise Plus de Cloud SQL, puedes aprovechar las ventajas de la recuperación tras desastres avanzada, que simplifica la recuperación y la restauración tras una conmutación por error entre regiones. Tal como se describe en el proceso de recuperación ante desastres, cuando llevas a cabo una recuperación ante desastres, eliminas la conexión entre la región con errores de la instancia principal antigua y la región operativa de la instancia principal nueva. Con la recuperación ante desastres, para restaurar las conexiones a la región de implementación original y recuperar tu antigua instancia principal, debes seguir una serie de pasos manuales de conmutación por error.
Con la recuperación tras desastres avanzada, cuando se produce un fallo en una región, puedes invocar una conmutación por error de réplica.
Con la conmutación por error de réplicas, puedes promocionar una réplica de lectura entre regiones de forma similar a la recuperación tras fallos normal, pero promocionando la réplica de recuperación tras fallos designada.
En Cloud SQL para SQL Server, puedes crear una réplica de recuperación ante desastres creando una réplica entre regiones de la instancia principal con la marca cascadable-replica. La promoción de la réplica de recuperación ante desastres es inmediata.
Además, cuando creas una instancia principal o designas una réplica de recuperación ante desastres para una instancia principal, Cloud SQL crea un endpoint de escritura.
Un endpoint de escritura es un nombre de DNS que se resuelve en la dirección IP de la instancia principal.
Cuando se promociona la réplica de recuperación tras desastres, el endpoint de escritura se actualiza para que apunte a la instancia principal recién promocionada. De esta forma, se asegura de que las aplicaciones que intenten conectarse mediante el endpoint de escritura se redirijan a la instancia promocionada.
En lugar de eliminar la instancia principal antigua, esta sigue formando parte de la topología de replicación asíncrona de Cloud SQL. La instancia principal antigua (instancia A) se convierte en una réplica de su réplica de recuperación ante desastres (instancia B) después de que esta se haya convertido en la nueva instancia principal.
Una vez que la instancia principal antigua (A) se haya convertido en una réplica, puedes llevar a cabo el paso final de la recuperación ante desastres avanzada. Puedes restaurar tu implementación de Cloud SQL a su estado original y restaurar la instancia principal antigua (A) a su función anterior como instancia principal sin perder datos. Para llevar a cabo esta restauración sin pérdida de datos de la instancia principal antigua (A), puedes usar la operación switchover. Cuando realizas un cambio, no se pierden datos, ya que la instancia principal (B) permanece en modo de solo lectura hasta que su réplica de recuperación ante desastres (A) se pone al día con la instancia principal (B). Una vez que la réplica de recuperación ante desastres (A) haya recibido todas sus actualizaciones de replicación, la réplica de recuperación ante desastres (A) asumirá el rol de instancia principal, mientras que la instancia principal anterior (B) se volverá a configurar automáticamente como réplica de recuperación ante desastres de la instancia principal actual (A). Las instancias vuelven a sus roles originales, por lo que la topología vuelve a su estado original antes de la recuperación ante desastres y la conmutación por error de la réplica.
Durante la recuperación ante desastres avanzada, todas las instancias implicadas en las operaciones de conmutación por error y de cambio de réplica conservan sus direcciones IP.
También puedes usar la operación de cambio de la recuperación ante desastres avanzada para realizar simulaciones de recuperación ante desastres rutinarias con el fin de probar y preparar tu topología de Cloud SQL para la conmutación por error entre regiones antes de que se produzca un desastre. Si se produce un desastre real, puedes llevar a cabo la conmutación por error de la réplica interregional que ya has probado.
Réplica de recuperación tras fallos
Como componente obligatorio de la recuperación ante desastres avanzada, la réplica de recuperación ante desastres tiene las siguientes características:
- Una réplica de recuperación ante desastres es una réplica de lectura entre regiones conectada directamente.
- Puedes cambiar la designación de la réplica de recuperación ante desastres varias veces.
- Una réplica de recuperación ante desastres es una réplica en cascada que se crea con la marca
cascadable-replica. Para actuar como réplica de recuperación ante desastres, la réplica en cascada debe estar en una región distinta a la de la instancia principal. - No puedes tener más de una réplica de recuperación ante desastres en una región.
- Puedes cambiar la designación de la réplica de recuperación ante desastres en cualquier momento, excepto durante una operación de cambio o de conmutación por error de la réplica.
Además, para reducir el tiempo de recuperación tras un desastre después de usar la recuperación ante desastres avanzada, te recomendamos que hagas lo siguiente:
- Configura la réplica de recuperación ante desastres con el mismo tamaño que la instancia principal.
- Si la instancia principal tiene habilitada la alta disponibilidad, te recomendamos que también la habilites en la réplica de recuperación ante desastres. Para ello, primero verifica que la instancia principal tenga habilitada la alta disponibilidad. A continuación, realiza el cambio a la réplica de recuperación ante desastres. Una vez completada la operación de cambio, habilita la alta disponibilidad en la nueva instancia principal. Después, puedes volver a la instancia principal anterior. La réplica de recuperación ante desastres conserva su configuración de alta disponibilidad incluso después de volver a ser una réplica.
Conmutación por error de réplica
En resumen, una conmutación por error de réplica consta de los siguientes eventos:
- Crea y asigna una réplica de recuperación ante desastres.
- La región principal deja de estar disponible.
- Realiza la conmutación por error de la réplica a la réplica de recuperación ante desastres.
- El endpoint de escritura se actualiza y empieza a apuntar a la nueva instancia principal.
- Cuando la instancia principal original vuelve a estar online, se convierte en una réplica de lectura de la nueva instancia principal.
- Puedes usar la operación de cambio para restaurar la topología original de tu implementación.
Para ver los detalles y los diagramas de una operación de conmutación por error de réplica, haz clic en las siguientes pestañas.
Asignar réplica de recuperación ante desastres
Antes de realizar una conmutación por error de réplica, has asignado una réplica de recuperación ante desastres a la instancia principal y es posible que hayas probado el proceso realizando una conmutación.

Se produce una interrupción del servicio
La región principal, que ejecuta la base de datos principal, deja de estar disponible.

Conmutación por error de réplica
Después de determinar que es necesario llevar a cabo una recuperación tras fallos, realiza una conmutación por error de la réplica a tu réplica de recuperación tras fallos.
La réplica de recuperación ante desastres se convierte en la instancia principal inmediatamente y empieza a aceptar lecturas y escrituras entrantes. El endpoint de escritura se actualiza y empieza a apuntar a la nueva instancia principal.

La réplica se convierte en la principal original
Una vez que se ha promovido la réplica, Cloud SQL comprueba periódicamente si la instancia principal original vuelve a estar online. Si la instancia principal original está online, Cloud SQL vuelve a crear la instancia principal antigua como réplica de la instancia ascendida. La instancia principal antigua conserva su dirección IP.
Si la instancia principal antigua no está activa durante 24 horas, Cloud SQL la elimina de la topología de replicación para asegurarse de que el registro de transacciones de la nueva instancia principal y sus otras réplicas no crezca sin límites.

Conmutación por recuperación al original
Después de realizar una conmutación por error de réplica, puedes restaurar la instancia principal en tu región original realizando la operación de conmutación, invirtiendo el mismo par de réplica de recuperación ante desastres e instancia principal.

Cambio
En resumen, una operación de cambio consta de los siguientes eventos:
- Crea y asigna una réplica de recuperación ante desastres.
- Inicias un cambio.
- Cuando la latencia de replicación se reduce a cero, la nueva instancia principal empieza a aceptar conexiones entrantes.
- La antigua instancia principal se convierte en una réplica de lectura.
- Si se está usando un endpoint de escritura de DNS, se actualiza para que apunte a la nueva instancia principal.
Para ver los detalles y los diagramas de una operación de cambio, haz clic en las siguientes pestañas.
Asignar réplica de recuperación ante desastres
Antes de iniciar la operación de *cambio*, debes asignar una réplica de recuperación ante desastres a la instancia principal.
Verifica que la instancia principal esté en buen estado. Solo puedes realizar un cambio cuando tanto la instancia principal como la réplica de recuperación ante desastres estén online.
Iniciar el cambio
Tú inicias el cambio. Cuando inicias un cambio, la replicación a la réplica de recuperación ante desastres cambia al modo síncrono. La réplica de recuperación ante desastres se pone al día con la instancia principal y cambia su estado a sincronizado. Cuando la latencia de replicación se reduce a cero, la réplica de recuperación ante desastres se convierte en la nueva instancia principal. La nueva instancia principal empieza a aceptar conexiones entrantes, incluidas las lecturas y escrituras de la aplicación.

Endpoint actualizado
Una vez que la réplica de recuperación ante desastres se haya convertido en la nueva instancia principal, se actualizará el endpoint de escritura de DNS y empezará a apuntar a la nueva instancia principal.
La antigua instancia principal se vuelve a configurar como réplica de lectura.
Escribir punto final
Un endpoint de escritura es un nombre de servicio de nombres de dominio (DNS) global que se resuelve automáticamente en la dirección IP de la instancia principal actual. Este endpoint redirige las conexiones entrantes a la nueva instancia principal automáticamente en caso de conmutación por error o conmutación de una réplica. Puede usar el endpoint de escritura en una cadena de conexión SQL en lugar de una dirección IP. Si usas un endpoint de escritura, no tendrás que hacer cambios en la conexión de la aplicación cuando se produzca una interrupción en una región.
Para usar un endpoint de escritura, es necesario que la API Cloud DNS esté habilitada en el proyecto en el que crees o tengas tu instancia principal de la edición Cloud SQL Enterprise Plus.
Cuando creas una instancia de la edición Enterprise Plus de Cloud SQL con una dirección IP privada y redes autorizadas, Cloud SQL genera automáticamente un endpoint de escritura para la instancia. Si ya tienes una instancia principal de la edición Enterprise Plus de Cloud SQL, Cloud SQL genera el endpoint de escritura cuando creas la réplica de recuperación ante desastres (una réplica entre regiones que creas con la marca cascadable-replica). Si la instancia principal cambia debido a una operación de cambio o de failover de réplica, Cloud SQL asigna el endpoint de escritura a la réplica de recuperación ante desastres cuando esta se convierte en la nueva instancia principal.
Para obtener más información sobre cómo usar un endpoint de escritura para conectarte a una instancia, consulta Conectarse a una instancia mediante un endpoint de escritura.
Siguientes pasos
- Usa la recuperación tras fallos avanzada.
- Consulta arquitecturas de referencia, diagramas, tutoriales y prácticas recomendadas sobre Google Cloud. Consulta nuestro Centro de arquitectura de Cloud.