이 페이지에서는 백업에서 인스턴스를 복원하거나 point-in-time recovery(PITR)를 수행하기 전에 검토할 정보를 제공합니다.
복원 중에는 어떻게 되나요?
인스턴스를 복원하면 기본 인스턴스의 다음 데이터가 새 인스턴스로 복원됩니다.
- 데이터베이스
- 사용자
복원 작업으로 인해 인스턴스가 재시작됩니다.
PITR(point-in-time recovery)
PITR(point-in-time recovery)은 인스턴스를 특정 시점으로 복구하는 데 도움이 됩니다. 예를 들어 오류로 데이터가 손실된 경우 오류가 발생하기 전의 시점으로 데이터베이스를 복구할 수 있습니다.
PITR은 항상 새 인스턴스를 만듭니다. 기존 인스턴스에서 PITR을 수행할 수 없습니다. 새로운 인스턴스는 클론 생성 방식과 유사하게 소스 인스턴스의 설정을 상속합니다.
Cloud SQL은 PITR에 트랜잭션 로그를 사용합니다. 인스턴스에 PITR을 사용 설정한 후 백업에서 인스턴스를 복원하면 Cloud SQL에서 복원된 인스턴스에서 PITR을 사용할 수 있는 트랜잭션 로그를 삭제합니다.
인스턴스에 대한 로그가 디스크 대신 Cloud Storage에 저장되도록 하려면 다음 작업을 완료합니다.
- 인스턴스의 네트워크 아키텍처를 확인합니다. 인스턴스가 이전 네트워크 아키텍처에 있는 경우 새 네트워크 아키텍처로 업그레이드합니다.
- 디스크의 로그 크기로 인해 인스턴스에 성능 문제가 발생하면 PITR을 비활성화하고 다시 사용 설정합니다.
PITR 수행에 대한 단계별 안내는 PITR(point-in-time recovery) 사용을 참조하세요.
사용 불가 인스턴스 복원
PITR을 사용하면 사용 불가 Cloud SQL 인스턴스를 복원할 수 있습니다. PITR은 일반적으로 5분 이하의 목표 복구 시간(RPO)을 제공합니다.
인스턴스를 사용할 수 없으면 API를 사용하여 인스턴스를 복원할 수 있는 가장 빠른 복구 시간과 가장 늦은 복구 시간을 가져와 해당 시점으로 복구를 수행하면 됩니다. 인스턴스가 구성된 영역에 액세스할 수 없으면 원하는 영역의 값을 제공하여 인스턴스를 다른 기본 또는 보조 영역으로 복원할 수 있습니다.
Cloud SQL 인스턴스를 오후 4시(EST)에 사용할 수 없게 되었다고 가정해 보겠습니다. 최근 복구 시간이 오후 3시 55분(EST)인 경우 이 시점까지 인스턴스를 복구할 수 있습니다.
PITR을 사용하여 삭제된 인스턴스 복원
PITR을 사용하여 삭제된 Cloud SQL 인스턴스를 복원할 수 있습니다. 이 기능을 사용하려면 인스턴스를 삭제하기 전에 인스턴스에서 PITR 및 보관된 백업을 사용 설정해야 합니다. 사용 설정하면 인스턴스를 삭제한 후에도 PITR 로그가 보관됩니다.
인스턴스가 삭제된 후에도 PITR 로그는 인스턴스가 활성 상태일 때 정의된 보관 설정을 계속 따릅니다. PITR 로그는 인스턴스가 삭제된 후 보관 설정에 따라 순차적으로 만료됩니다. 연속 기간은 삭제 전 인스턴스에 설정된 PITR 보관 기간에 따라 정의됩니다. 예를 들어 Cloud SQL Enterprise Plus 버전 인스턴스의 PITR 보관 기간이 14일로 설정된 경우 인스턴스 삭제 후 14일이 지나면 최신 PITR 로그가 삭제됩니다. PITR 로그가 만료되면 복구할 수 없습니다.
Cloud SQL에서 인스턴스를 삭제한 후에도 인스턴스 이름을 재사용할 수 있으므로 보관된 PITR 로그는 Google Cloud 에서 다음 필드를 사용하여 식별할 수 있습니다.
instance_deletion_timelog_retention_days
이러한 필드를 사용하면 PITR 로그가 삭제된 인스턴스에 속하는지 식별할 수 있습니다.
PITR 복구 기간은 PITR을 사용하여 인스턴스를 복원할 수 있는 가장 이른 복구 시간과 가장 늦은 복구 시간으로 정의됩니다. 삭제된 인스턴스의 가장 빠른 복구 시간과 가장 늦은 복구 시간을 확인하려면 가장 빠른 복구 시간과 가장 늦은 복구 시간 가져오기를 참고하세요.
인스턴스 삭제 후 PITR을 사용하여 인스턴스를 복원하려면 삭제된 인스턴스에서 PITR 수행을 참고하세요.
복원 실행에 대한 일반적인 도움말
백업을 사용하여 같은 인스턴스 또는 다른 인스턴스로 인스턴스를 복원할 때는 다음 사항을 유의하세요.
- 복원 작업은 대상 인스턴스의 모든 데이터를 덮어씁니다.
- 복원 작업 중에는 대상 인스턴스에 연결할 수 없으며 기존 연결은 끊어집니다.
- 읽기 복제본이 있는 인스턴스로 복원하는 경우 복원이 완료된 후 모든 복제본을 삭제하고 다시 만들어야 합니다.
- 복원 작업은 인스턴스를 다시 시작합니다.
복원 실행에 관한 단계별 안내는 다음을 참조하세요.
다른 인스턴스로 복원할 때 도움말 및 요구사항
다른 인스턴스로 백업을 복원할 때 다음 제한사항 및 권장사항을 유의하세요.
대상 인스턴스의 데이터베이스 버전은 백업이 실행된 인스턴스의 버전과 같아야 합니다.
Cloud SQL은 항상 대상 인스턴스의 스토리지 용량을 구성된 디스크와 백업 디스크 모두의 최대 크기 값으로 설정합니다. 백업 디스크는 백업이 작성될 때의 디스크 크기입니다.
대상 인스턴스의 스토리지 용량은 최소한 백업되는 인스턴스의 용량 이상이어야 합니다. 사용되는 스토리지의 크기는 중요하지 않습니다. 콘솔의 Cloud SQL 인스턴스 페이지에서 인스턴스의 스토리지 용량을 확인할 수 있습니다. 이 요구사항은 단일 데이터베이스 PITR을 수행하는지 여부에 적용됩니다.
대상 인스턴스는
RUNNABLE상태여야 합니다.대상 인스턴스의 코어 개수 또는 메모리 양은 백업이 실행된 인스턴스와 다를 수 있습니다.
대상 인스턴스가 소스 인스턴스와 다른 리전에 있을 수 있습니다.
서비스 중단 시 특정 프로젝트의 백업 목록을 계속 검색할 수 있습니다. 서비스 중단 시 백업 보기를 참조하세요.
복원 비율 제한
프로젝트마다 리전별로 인스턴스당 30분 간격으로 복원 작업이 최대 3개까지 허용됩니다. 복원 작업이 실패하면 이 할당량에 포함되지 않습니다. 이 한도에 도달하면 작업이 실패하고 작업을 다시 실행할 수 있는 시기를 알려주는 오류 메시지가 표시됩니다.
Cloud SQL에서 복원에 비율 제한을 수행하는 방법을 살펴보겠습니다.
Cloud SQL에서는 버킷의 토큰을 사용하여 한 번에 사용할 수 있는 복원 작업 수를 결정합니다. 백업마다 각 타겟 프로젝트와 타겟 리전에 대한 버킷이 있습니다. 동일한 프로젝트의 타겟 인스턴스가 같은 리전에 있으면 버킷 하나를 공유합니다. 버킷마다 복원 작업에 사용할 수 있는 토큰이 최대 3개 있습니다. 10분마다 새 토큰이 버킷에 추가됩니다. 버킷이 가득 차면 토큰이 오버플로됩니다.
복원 작업을 실행할 때마다 버킷에서 토큰이 부여됩니다. 작업이 성공하면 토큰이 버킷에서 삭제됩니다. 실패하면 토큰은 버킷으로 반환됩니다. 다음 다이어그램에서는 작동 방식을 보여줍니다.

예를 들어 다음 그림에서 Backup1, Backup2, Backup3은 동일한 소스 인스턴스의 백업입니다.
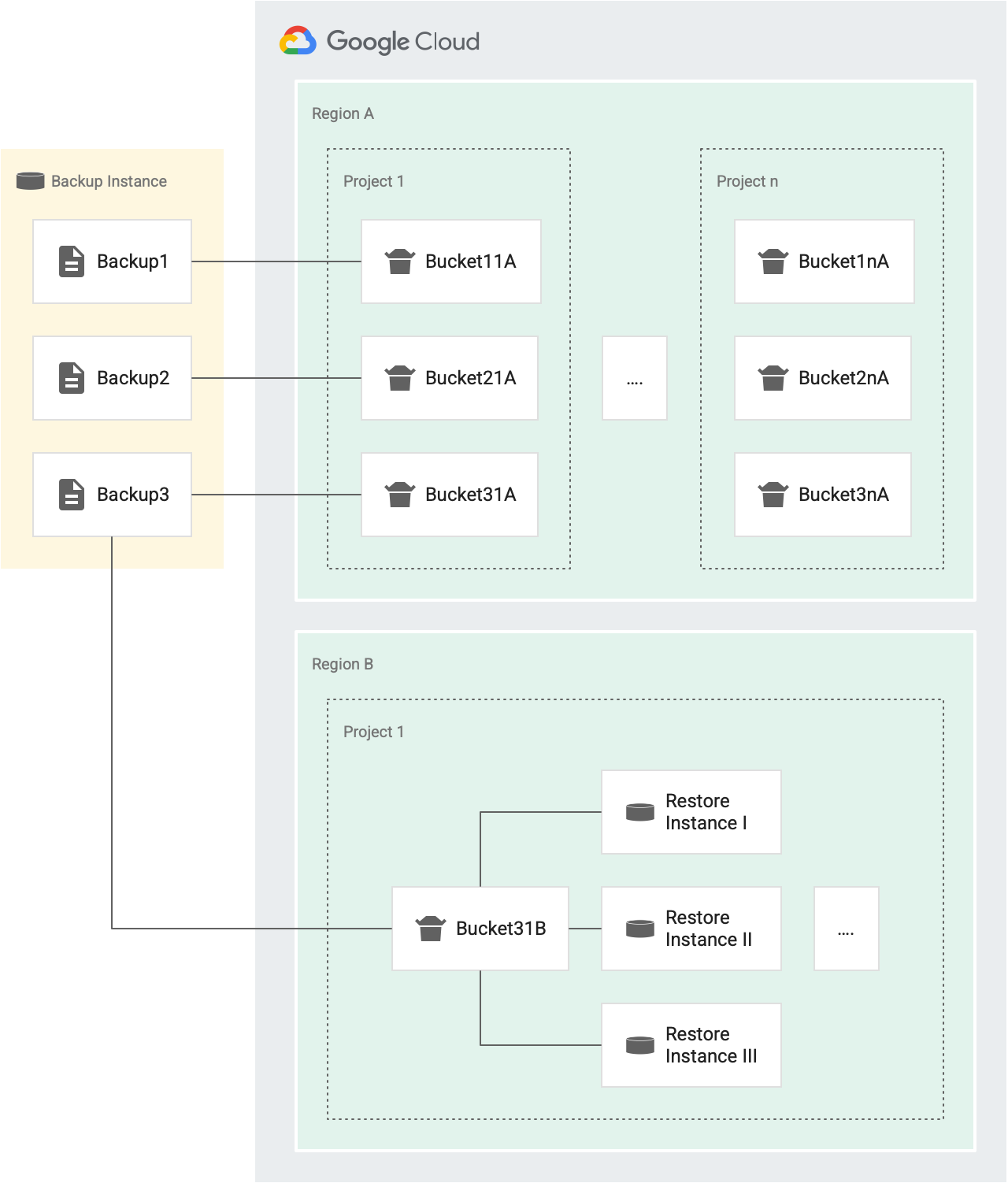
- 각 백업(Backup1, Backup2, Backup3)에는 리전 A의 프로젝트 1에 있는 여러 인스턴스(Bucket11A, Bucket21A, Bucket31A)를 타겟팅하는 복원 작업에 사용되는 자체 토큰 버킷이 있습니다. 각 백업에는 자체 버킷이 있으므로 30분마다 3회씩 각 백업을 동일한 인스턴스로 복원할 수 있습니다.
- 백업마다 별도의 프로젝트와 별도의 리전에 사용되는 버킷이 있습니다.
예를 들어 리전 하나에 프로젝트가 5개 있는 경우 해당 리전에는 프로젝트마다 백업 하나에 사용되는 버킷 5개가 있습니다. 앞의 그림에는 리전 A에 프로젝트 1과 프로젝트 n이라는 프로젝트 두 개가 있습니다.
- Backup1에는 리전 A의 복원 작업에 사용되는 토큰 버킷이 두 개 있습니다. 프로젝트 1(Bucket11A)에 버킷 하나, 프로젝트 n(Bucket1nA)에 버킷 하나가 있습니다.
- 마찬가지로 Backup3에는 리전 A의 복원 작업에 사용되는 버킷이 두 개 있습니다. 프로젝트 1(Bucket31A)에 하나, 프로젝트 n(Bucket3nA)에 하나가 있습니다.
- 동일한 타겟 프로젝트와 동일한 타겟 리전의 모든 인스턴스에서 버킷 하나를 공유하므로 Backup3에는 리전 B의 Project1에 사용되는 버킷이 하나 있습니다.