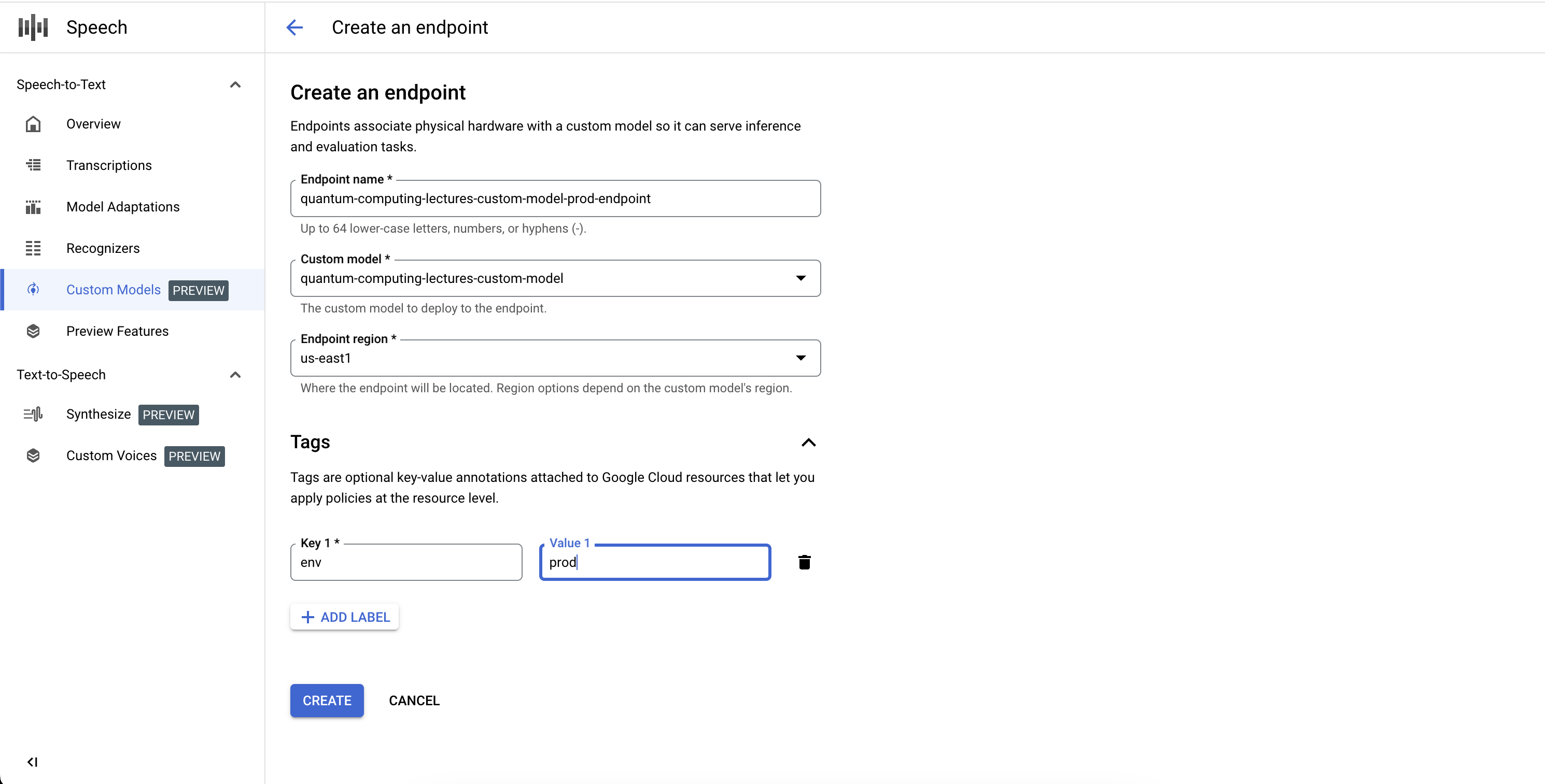
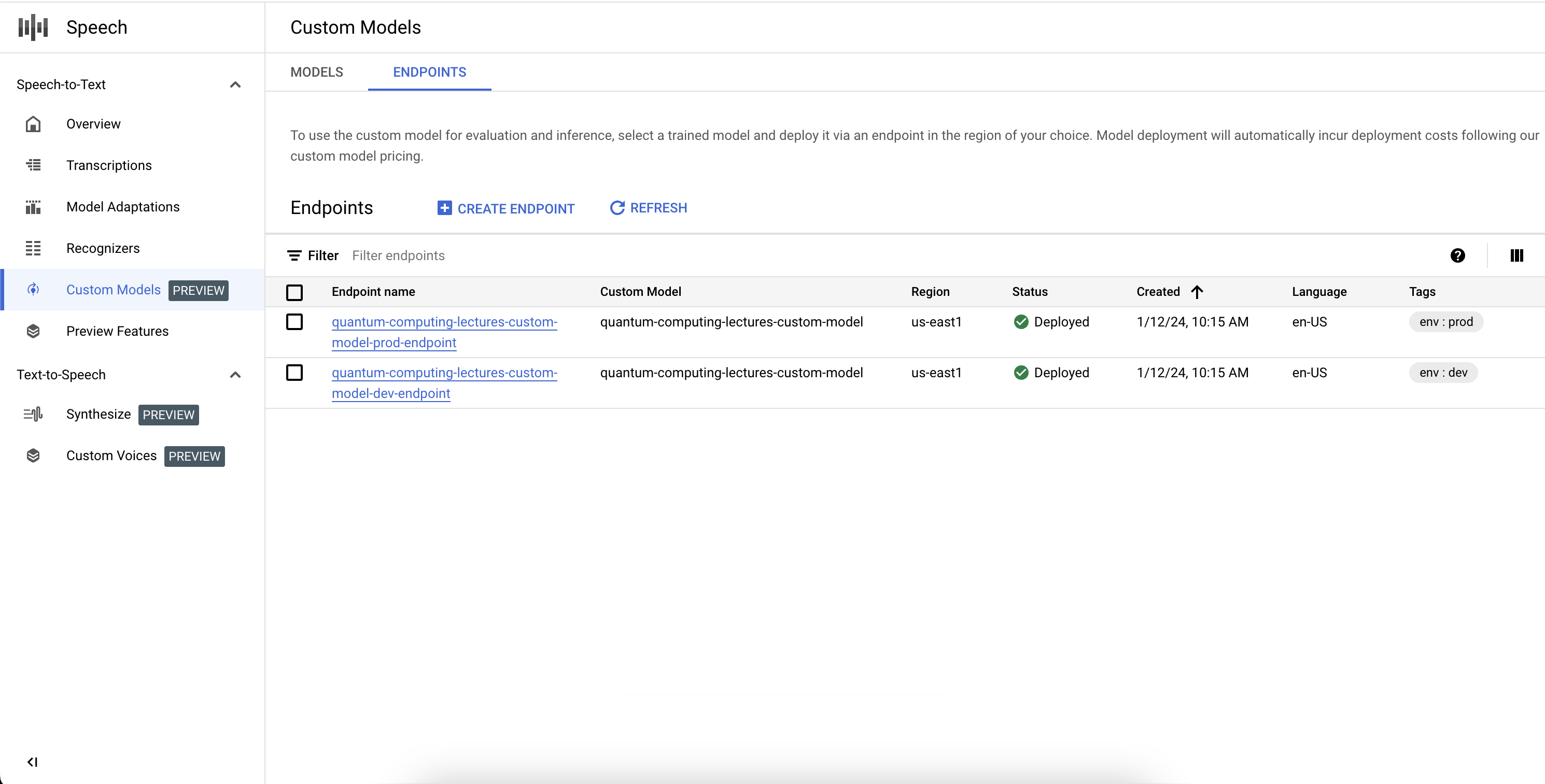
在生产应用或基准化分析工作流中使用经过训练的自定义 Speech-to-Text 模型。您必须通过专用端点部署和公开模型,创建的端点部分用于在所选区域中部署模型。您可以通过识别器对象自动获取程序化访问权限。您可以直接通过 V2 API 或在 Google Cloud 控制台中使用模型。您可以在与训练模型不同的区域中部署模型,但系统会在端点指定的区域中创建模型的副本。
如需使用自定义语音模型,您需要通过专用端点进行部署和公开。通过创建端点,您可以在所选区域中部署模型。您通过识别器对象自动获得程序化访问权限,从而直接通过 V2 API 进行推理或在 Google Cloud 控制台中使用。
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["很难理解","hardToUnderstand","thumb-down"],["信息或示例代码不正确","incorrectInformationOrSampleCode","thumb-down"],["没有我需要的信息/示例","missingTheInformationSamplesINeed","thumb-down"],["翻译问题","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2025-07-24。"],[],[],null,["# Deploy and manage endpoints\n\n| **Preview**\n|\n|\n| This feature is subject to the \"Pre-GA Offerings Terms\" in the General Service Terms section\n| of the [Service Specific Terms](/terms/service-terms#1).\n|\n| Pre-GA features are available \"as is\" and might have limited support.\n|\n| For more information, see the\n| [launch stage descriptions](/products#product-launch-stages).\n\nUse a trained Custom Speech-to-Text model in your production application or benchmarking workflows. You must deploy and expose the model through a dedicated endpoint, created in part to deploy the model in your chosen region. You automatically get programmatic access through a recognizer object. It is used directly through the V2 API or in the Google Cloud console. You can deploy your model in a region different from where it was trained, but a copy of the model is created in the region specified by the endpoint.\n\nTo use a custom speech model, you need to deploy and expose it through a dedicated endpoint. By creating an endpoint, you're deploying the model in the region of your choice. You're automatically granted programmatic access through a recognizer object to be used directly through the V2 API for inference or in the Google Cloud console.\n\nBefore you begin\n----------------\n\nEnsure you have signed up for a Google Cloud account, created a project, and trained a custom speech model.\n\n1. Go to **Speech** in the Google Cloud console, and navigate to Speech-to-Text.\n2. Navigate within the **Custom Models** section of the navigation bar on the left.\n\nCreate an endpoint\n------------------\n\n1. Navigate to the **Endpoints** tab of the **Custom Models** section.\n2. Click **New Endpoint**.\n3. Define a name for your endpoint. This acts as a unique identifier for your endpoint resource and is used to invoke your custom speech model for inference.\n4. Define the region where you want your custom speech model to be deployed. If the model was trained in a different region than the one defined in the endpoint configuration, a new model copy is created automatically.\n5. Select the trained custom speech model from the list that you want to expose through the endpoint.\n6. Click **Create** and after a few moments your custom speech model is deployed in your endpoint, ready to be used for inference and benchmarking.\n\nList your endpoints\n-------------------\n\nYou can manage the associated endpoints in the console by selecting the Endpoints tab under the Custom Models section. You can also list the endpoints that you created in the console, along with their current state and associated custom Speech-to-Text model.\n\nDelete an endpoint\n------------------\n\nBefore you start, make sure that there is no traffic routed through your endpoint, because deleting it will stop it from serving any requests.\n\n1. Navigate to the **Endpoints** tab of the **Custom Models** section.\n2. Under the **Endpoints** tab, click to expand options and then click **Delete**. In a few moments, the endpoint is deleted and no longer serves any traffic.\n\nBenchmark the model\n-------------------\n\nUsing the Custom Speech-to-Text model and your benchmarking dataset to assess the accuracy of your model, follow the [Measure and improve accuracy guide](/speech-to-text/docs/measure-accuracy)."]]