這個頁面說明 Spanner 的實際工作環境配額和限制。配額和限制可能會在 Google Cloud 控制台中交替使用。
配額與限制的值隨時可能變動。
檢查及編輯配額的權限
如要查看配額,必須具備
serviceusage.quotas.get
身分與存取權管理 (IAM) 權限。
如要變更配額,您必須具備 serviceusage.quotas.update IAM 權限。根據預設,擁有者、編輯者和配額管理員這些預先定義的角色都具備這項權限。
根據預設,「擁有者」和「編輯者」這些基本 IAM 角色和預先定義的「配額管理員」角色,都擁有這些權限。
查看配額
如要查看專案目前的資源配額,請使用Google Cloud 控制台:
提高配額
隨著 Spanner 使用量增加,您也可以要求更多配額。如果您預期用量將大幅攀升,請提前幾天提出申請,確保系統可以妥善調整您的配額。
您可能也需要提高用戶端配額覆寫。詳情請參閱建立消費者配額覆寫。
您可以使用 Google Cloud 控制台,提高目前的 Spanner 執行個體設定節點限制。
前往「配額」頁面。
在「服務」下拉式清單中,選取「Spanner API」。
如果系統未顯示「Spanner API」,表示 Spanner API 尚未啟用。詳情請參閱啟用 API。
選取要變更的配額。
按一下 [編輯配額]。
在隨即顯示的「Quota changes」(配額變更) 面板中,輸入新的配額限制。
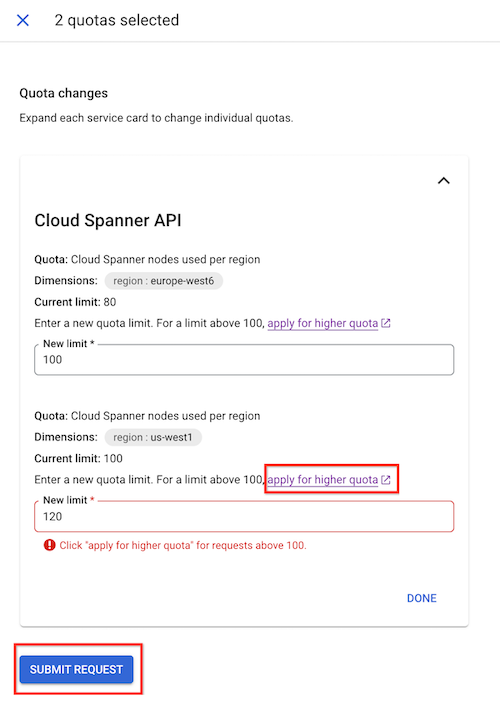
依序按一下「完成」和「提交要求」。
如果無法手動將節點上限提高至所需上限,請點選「申請更多配額」。填寫表單,向 Spanner 團隊提出要求。您會在提出要求後的 48 小時內收到回覆。
增加自訂執行個體設定的配額
您可以提高自訂執行個體設定的節點配額。
如要檢查自訂執行個體設定的節點限制,請檢查基本執行個體設定的節點限制。
如果自訂執行個體設定所需的節點限制少於 85,請按照上一節「提高配額」的說明操作。使用 Google Cloud 控制台,提高與自訂執行個體設定相關聯的基本執行個體設定節點限制。
如果自訂執行個體設定所需的節點數量超過 85 個,請填寫「Request a Quota Increase for your Spanner Nodes」(要求增加 Spanner 節點配額) 表單。在表單中指定自訂執行個體設定的 ID。
節點限制
| 值 | 限制 |
|---|---|
| 每個執行個體設定的節點數 |
預設限制會因專案和執行個體設定而異。如要變更專案配額限制或申請提高限制,請參閱「提高配額」。 |
執行個體限制
| 值 | 限制 |
|---|---|
| 執行個體 ID 長度 | 2 至 64 個字元 |
免費試用執行個體限制
Spanner 免費試用執行個體有下列額外限制。如要提高或移除這些限制,請將免費試用執行個體升級為付費執行個體。
| 值 | 限制 |
|---|---|
| 儲存空間容量 | 10 GiB |
| 資料庫限制 | 最多可建立五個資料庫 |
| 不支援的功能 | 備份與還原 |
| 服務水準協議 | 無服務水準協議 |
| 試用期長度 | 90 天免費試用期 |
地理區域分割限制
| 值 | 限制 |
|---|---|
| 每個執行個體的分區數量上限 | 20 |
| 每個資料庫的刊登位置數量上限 | 50 |
| 每個節點在分割區中的放置資料列數量上限 | 1 億 |
已儲存查詢的限制
| 值 | 限制 |
|---|---|
| 每個專案的儲存查詢數量上限 (包括其他 Google Cloud 產品的儲存查詢) | 10,000 |
| 每次查詢的大小上限 | 1 MiB |
執行個體設定限制
| 值 | 限制 |
|---|---|
| 每個專案的自訂執行個體設定數量上限 | 100 |
| 自訂執行個體設定 ID 長度 | 8 至 64 個字元 自訂執行個體設定 ID 的開頭必須是 |
資料庫限制
| 值 | 限制 |
|---|---|
| 每個執行個體的資料庫數 |
|
| 每個資料庫的角色數 | 100 |
| 資料庫 ID 長度 | 2 至 30 個字元 |
| 儲存空間大小1 |
在大多數區域、雙區域和多區域 Spanner 執行個體設定中,每個節點的儲存空間容量增加至 10 TiB。詳情請參閱「效能和儲存空間改善」。 如果您使用分層儲存空間,每個節點最多可使用 10 TiB 的組合儲存空間 (SSD 和 HDD)。 備份會分開儲存,不會計入這項限制配額。詳情請參閱「儲存空間使用率指標」。 請注意,Spanner 會針對執行個體內實際使用的儲存空間計費,而非總可用儲存空間。 |
備份與還原限制
| 值 | 限制 |
|---|---|
| 每個資料庫正在執行的備份建立作業數量 | 1 |
| 每個執行個體正在執行的資料庫還原作業數量 (此處所指執行個體為位於還原資料庫者,並非位於備份中) | 10 |
| 備份保留時間上限 | 1 年 (包含閏年中的額外天數) |
結構定義限制
結構定義物件
| 值 | 限制 |
|---|---|
| 同一執行個體中所有資料庫的架構物件總數 | 預設限制會因執行個體設定而異2 |
DDL 陳述式
| 值 | 限制 |
|---|---|
| 單一結構定義變更的 DDL 陳述式大小 | 10 MiB |
由 GetDatabaseDdl 傳回,資料庫整個結構定義的 DDL 陳述式大小 |
10 MiB |
圖表
| 值 | 限制 |
|---|---|
| 每個資料庫的屬性圖 | 16 |
| 屬性圖名稱長度 | 1 至 128 個字元 |
資料表
| 值 | 限制 |
|---|---|
| 每個資料庫的資料表數 | 5,000 |
| 資料表名稱長度 | 1 至 128 個字元 |
| 每個資料表的欄數 | 1,024 |
| 欄名稱長度 | 1 至 128 個字元 |
| 每個儲存格的資料大小上限 | 10 MiB |
STRING 儲存格的大小 |
2,621,440 個 Unicode 字元 |
| 資料表索引鍵中的欄數 | 16 包含與任何上層資料表共用的索引鍵欄 |
| 資料表交錯深度 | 7 如果頂層資料表含有子資料表,則深度為 1。 如果頂層資料表的子資料表下還有一層子資料表,則深度為 2,以此類推。 |
| 每列的主鍵或索引鍵大小上限 | 8 KiB 組成索引鍵之所有資料欄的加總大小。 |
| 每列非鍵資料欄的總大小 | 1600 MiB 資料表中每列所有非索引鍵資料欄的加總大小。 |
索引
| 值 | 限制 |
|---|---|
| 每個資料庫的索引數 | 10,000 |
| 每個資料表的索引數 | 128 |
| 索引名稱長度 | 1 至 128 個字元 |
| 索引鍵中的欄數 | 16 已建立索引的欄數 (STORING 欄除外) 加上主資料表中的主鍵欄數 |
瀏覽次數
| 值 | 限制 |
|---|---|
| 每個資料庫的檢視畫面 | 5,000 |
| 檢視名稱長度 | 1 至 128 個字元 |
| 巢狀結構深度 | 10 參照另一個檢視畫面的檢視畫面巢狀深度為 1。如果某個檢視畫面參照另一個檢視畫面,而該檢視畫面又參照其他檢視畫面,則巢狀結構深度為 2,以此類推。 |
位置群組
| 值 | 限制 |
|---|---|
| 每個資料庫的區域群組數量上限 | 16 個 (1 個預設區域群組和 15 個選用的額外區域群組) |
ssd_to_hdd_spill_timespan 選項的最低時間量 |
1 小時 |
「ssd_to_hdd_spill_timespan」選項允許的最長時間 |
365 天 |
查詢限制
| 值 | 限制 |
|---|---|
GROUP BY 子句中的欄數 |
1,000 |
IN 運算子中的值 |
10,000 |
| 函式呼叫數 | 1,000 |
| 彙整 | 20 |
| 巢狀函式呼叫數 | 75 |
巢狀 GROUP BY 子句數 |
35 |
| 巢狀子查詢運算式數 | 25 |
| 巢狀 Subselect 陳述式數 | 60 |
| 圖表查詢產生的聯結 | 100 |
| 參數 | 950 |
| 查詢陳述式長度 | 100 萬個字元 |
STRUCT 個欄位 |
1,000 |
| 子查詢運算式子項數 | 50 |
| 查詢中的聯集數 | 200 |
| 圖形深度 量化路徑遍歷 | 100 |
建立、讀取、更新和刪除資料的限制
| 值 | 限制 |
|---|---|
| 修訂版本大小 (含索引和變更串流) | 100 MiB |
| 每個工作階段的並行讀取數 | 100 |
| 每個修訂版本 (含索引) 的異動數3 | 80,000 |
| 批次寫入要求中每個變異群組的變異數 | 80,000 |
| 每個資料庫的並行分區 DML 陳述式數 | 20,000 |
管理作業限制
| 值 | 限制 |
|---|---|
| 管理動作要求大小4 | 1 MiB |
| 管理動作頻率限制5 | 每位使用者每個專案每秒 5 次 (100 秒期間的平均次數) |
要求限制
| 值 | 限制 |
|---|---|
| 修訂版本以外的要求大小6 | 10 MiB |
變更串流限制
| 值 | 限制 |
|---|---|
| 每個資料庫的變更串流 | 10 |
| 變更觀看任何指定非鍵資料欄的串流7 | 3 |
| 每個變更串流資料分割區的並行讀取器8 | 20 |
Data Boost 限制
| 值 | 限制 |
|---|---|
| 每個專案在 us-central1 中的並行 Data Boost 要求數 | 1000 9 |
| 其他區域中每個專案每個區域的並行 Data Boost 要求 | 400 9 |
預先分割 API 限制
| 值 | 限制 |
|---|---|
| 每個 API 要求新增的分割點 | 100 |
| 分割點 API 請求大小 | 1 MiB |
| 執行個體中所有資料庫的每個節點新增分割點 | 50 |
| 每個節點每分鐘新增或更新的分割點 | 10 |
| 每天每個節點新增或更新的分割點 | 200 |
附註
1. 為確保資料庫存取作業的高可用性及低延遲時間,Spanner 會根據執行個體的運算能力定義儲存空間限制:
- 如果執行個體的處理單元少於 1 個節點 (1,000 個處理單元),Spanner 會為資料庫中每 100 個處理單元分配 1024.0 GiB 的資料。
- 如果執行個體有 1 個以上的節點,Spanner 會為每個節點分配 10 TiB 的資料。
舉例來說,如要為 1500 GiB 的資料庫建立執行個體,您需要將運算資源設為 200 個處理單元。在資料庫成長到超過 2048.0 GiB 之前,這個運算容量可確保執行個體不超過限制。當資料庫達到這個大小時,您就必須再新增 100 個處理單元,好讓資料庫能繼續成長。否則,資料庫的寫入作業可能會遭到拒絕。詳情請參閱「資料庫儲存空間用量建議」。
為確保資料庫能順利成長,請在資料庫達到上限前新增運算容量。
2. 計入的結構定義物件包括 DDL 中描述的所有物件類型,例如資料表、資料欄、索引、序列等。結構定義物件限制是在執行個體層級強制執行,且取決於執行個體可用的處理單元。
- 對於一個節點以上的執行個體,預設限制為一百萬個物件。
- 如果執行個體小於一個節點 (1,000 個處理單元),上限會與執行個體大小成比例減少。舉例來說,如果執行個體有 100 個處理單元,則架構物件的上限為 100,000 個。
如要查看資料庫的架構物件計數和執行個體的物件限制,請在 Metrics Explorer 中尋找 spanner.googleapis.com/instance/schema_objects 和 spanner.googleapis.com/instance/schema_object_count 指標。如要進一步瞭解如何監控執行個體,請參閱「使用 Cloud Monitoring 監控執行個體」。
如果達到上限,Spanner 會禁止您執行超出上限的操作,例如:
- 修改資料庫的結構定義 (例如新增索引)。
- 在執行個體中建立新的資料庫。
- 從備份還原資料庫至相同執行個體。在這種情況下,您可以在設定相同的其他執行個體中還原備份,或是建立設定相同的新執行個體,然後在新執行個體中還原備份。
3. 計算異動數時,應將插入和更新作業數乘以受到這兩項作業影響的欄數,且主鍵欄一律會受到影響。舉例來說,在您插入一筆新記錄時,如果資料值是插入至五個資料欄,系統可能會計為五次異動。如果記錄有兩個主鍵欄,更新記錄中的三個資料欄也可能會計為五次異動。不過,以刪除作業和刪除範圍作業來說,無論受影響的資料欄數量為何,系統只會計為一次異動。從含有 ON DELETE
CASCADE 註解的上層資料表中刪除資料列時,無論交錯的子資料列數量為何,系統同樣只會計為一次異動。例外狀況如下:如果您要刪除的資料列已定義次要索引,則對次要索引所做的變更會單獨計算。舉例來說,如果資料表有 2 個次要索引,刪除資料表中的資料列範圍會計為 1 個資料表突變,加上每個刪除資料列的 2 個突變,因為次要索引中的資料列可能會分散在鍵空間中,導致 Spanner 無法對次要索引呼叫單一刪除範圍作業。次要索引包含外部索引鍵支援索引。
如要找出交易的突變次數,請參閱「 擷取交易的修訂統計資料」。
變更串流不會新增任何計入這項限制的突變。
4. 管理動作要求限制不適用於修訂版本、第 9 點附註中所列的要求及結構定義變更。
5. 此頻率限制適用所有對 Admin API 的呼叫,包括對執行個體、資料庫或備份的長時間執行作業輪詢呼叫。
6. 此限制適用的要求包括建立資料庫、更新資料庫、讀取、串流讀取、執行 SQL 查詢,以及執行串流 SQL 查詢。
7. 如果變更串流監控整個資料表或資料庫,系統會隱含監控該資料表或資料庫中的每個資料欄,因此會計入這項限制。
8. 無論讀取器是 Dataflow 管道或直接 API 查詢,這個限制都適用於相同變更串流分割區的並行讀取器。
9. 預設限制會因專案和區域而異。詳情請參閱「監控及管理 Data Boost 配額用量」。