In diesem Artikel wird gezeigt, wie mithilfe von Sensitive Data Protection die k-Anonymität eines Datasets gemessen und in Looker Studio dargestellt werden kann. Auf diese Weise können Sie auch Risiken besser verstehen und die Kompromisse in Bezug auf den Nutzen abwägen, die Sie möglicherweise eingehen, wenn Sie Daten entfernen oder de-identifizieren.
Obwohl wir in diesem Thema hauptsächlich die Visualisierung des Messwerts der k-Anonymität-Re-Identifizierungs-Risikoanalyse behandeln, können Sie auch den l-Diversitäts-Messwert mit den selben Methoden visualisieren.
In diesem Thema wird davon ausgegangen, dass Sie mit dem Konzept der k-Anonymität und ihrem Nutzen zur Bewertung der Reidentifizierbarkeit von Einträgen in einem Dataset vertraut sind. Es ist auch hilfreich, sich zumindest ein wenig mit der Berechnung der k-Anonymität über Sensitive Data Protection und mit der Verwendung von Looker Studio vertraut zu machen.
Einführung
De-Identifikationstechniken können sehr hilfreich sein, um die Privatsphäre von Personen zu schützen, während Sie Daten verarbeiten oder verwenden. Aber woher wissen Sie, ob ein Dataset ausreichend de-identifiziert wurde? Wie stellen Sie außerdem fest, ob Ihre De-Identifikation zu viel Datenverlust für Ihren Anwendungsfall verursacht hat? Das heißt: Wie können Sie das Risiko der Re-Identifizierung mit dem Nutzen der Daten vergleichen, um datengestützte Entscheidungen zu treffen?
Die Berechnung des k-Anonymitätswerts eines Datensatzes hilft durch die Beurteilung der Re-Identifizierbarkeit von Datensatzeinträgen bei der Beantwortung dieser Fragen. Sensitive Data Protection enthält integrierte Funktionen zum Berechnen eines k-Anonymitätswerts für ein Dataset auf der Grundlage von Quasi-Identifikatoren, die Sie angeben. Auf diese Weise können Sie schnell beurteilen, ob die De-Identifizierung einer bestimmten Spalte oder Kombination von Spalten zu einem Datensatz führt, der mehr oder weniger wahrscheinlich reidentifiziert wird.
Beispieldatensatz
Im Folgenden sind die ersten Zeilen eines großen Beispiel-Datasets aufgeführt.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Für den Zweck dieses Tutorials wird nicht auf user_id eingegangen, da der Schwerpunkt auf Quasi-Identifikatoren liegt. In der Praxis sollten Sie dafür sorgen, dass die user_id entsprechend entfernt oder tokenisiert wird. Die Spalte score ist proprietär für dieses Dataset und es ist unwahrscheinlich, dass ein Angreifer sie auf andere Weise in Erfahrung bringen könnte. Deshalb beziehen Sie diese nicht in die Analyse ein. Ihr Schwerpunkt liegt auf den verbleibenden Spalten age und title, mit denen ein Angreifer potenziell über andere Datenquellen etwas über eine Person erfahren kann. Die Fragen, die Sie für das Dataset beantworten möchten, lauten:
- Welche Auswirkung haben die beiden Quasi-Identifikatoren
ageundtitleauf das Gesamtrisiko der Re-Identifizierung der de-identifizierten Daten? - Wie wirkt sich die Anwendung einer De-Identifikationstransformation auf dieses Risiko aus?
Wichtig ist, dass die Kombination aus age und title nicht auf eine kleine Gruppe von Nutzern zurückzuführen ist. Angenommen, es gibt nur einen Nutzer im Dataset, dessen Titel „Programmierer I“ ist und der „69“ Jahre alt ist. Ein Angreifer könnte in der Lage sein, diese Informationen mit demographischen Daten oder anderen verfügbaren Informationen abzugleichen, herauszufinden, wer die Person ist, und ihre Bewertung zu erfahren.
Weitere Informationen über dieses Phänomen finden Sie im Abschnitt Entitäten-IDs und Berechnen der k-Anonymität im Konzept-Thema Risikoanalyse.
Schritt 1: k-Anonymität für den Datensatz berechnen
Verwenden Sie zuerst Sensitive Data Protection, um die k-Anonymität des Datasets zu berechnen, indem Sie die folgende JSON an die Ressource DlpJob senden. In diesem JSON-Code legen Sie die Entitäts-ID auf die Spalte user_id fest und identifizieren die beiden Quasi-Identifikatoren als die Spalten age und title. Sie weisen Sensitive Data Protection außerdem an, die Ergebnisse in einer neuen BigQuery-Tabelle zu speichern.
JSON-Eingabe:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}Sobald der k-Anonymitätsjob abgeschlossen ist, sendet Sensitive Data Protection die Jobergebnisse an eine BigQuery-Tabelle mit dem Namen dlp-demo-2.dlp_testing.test_results.
Schritt 2: Ergebnisse mit Looker Studio verbinden
Als Nächstes verbinden Sie die BigQuery-Tabelle, die Sie in Schritt 1 erstellt haben, mit einem neuen Bericht in Looker Studio.
Öffnen Sie Looker Studio.
Klicken Sie auf Erstellen > Bericht.
Klicken Sie im Bereich Daten hinzufügen unter Mit Daten verbinden auf BigQuery. Möglicherweise müssen Sie Looker Studio für den Zugriff auf Ihre BigQuery-Tabellen autorisieren.
Wählen Sie in der Spaltenauswahl Meine Projekte aus. Wählen Sie dann das Projekt, das Dataset und die Tabelle aus. Wenn Sie fertig sind, klicken Sie auf Hinzufügen. Wenn Sie darauf hingewiesen werden, dass Sie diesem Bericht gerade Daten hinzufügen, klicken Sie auf Zum Bericht hinzufügen.
Die Ergebnisse der k-Anonymitätsprüfung wurden jetzt dem neuen Looker Studio-Bericht hinzugefügt. Im nächsten Schritt erstellen Sie das Diagramm.
Schritt 3: Diagramm erstellen
So fügen Sie das Diagramm ein und konfigurieren es:
- Wenn in Looker Studio eine Tabelle mit Werten angezeigt wird, wählen Sie sie aus und drücken Sie die Entf-Taste, um sie zu löschen.
- Klicken Sie im Menü Einfügen auf Kombinationsdiagramm.
- Klicken und zeichnen Sie im Canvas ein Rechteck, wo das Diagramm angezeigt werden soll.
Konfigurieren Sie als nächstes die Diagrammdaten unter dem Tab Daten, sodass das Diagramm die Auswirkung der Variation der Größe und der Wertebereiche der Buckets zeigt:
- Löschen Sie die Felder unter den folgenden Überschriften, indem Sie die Maus auf die einzelnen Felder bewegen und auf das X klicken, wie hier gezeigt:
- Zeitraumdimension
- Dimension
- Messwert
- Sort
- Wenn alle Felder gelöscht wurden, ziehen Sie das Feld upper_endpoint aus der Spalte Verfügbare Felder in die Überschrift Dimension.
- Ziehen Sie das Feld upper_endpoint in die Überschrift Sortieren und wählen Sie dann Aufsteigend aus.
- Ziehen Sie die Felder bucket_size und bucket_value_count in die Überschrift Messwert.
- Zeigen Sie auf das Symbol links neben dem Messwert bucket_size und ein Bearbeitungssymbol (Stift) wird angezeigt.
Klicken Sie auf das Symbol Bearbeiten
und gehen Sie dann so vor:
- Geben Sie im Feld Name den Wert
Unique row lossein. - Wählen Sie unter Typ die Option Prozent aus.
- Wählen Sie unter Vergleichsberechnung die Option Prozent des Gesamtwerts aus.
- Wählen Sie unter Laufende Berechnung die Option Laufende Summe aus.
- Geben Sie im Feld Name den Wert
- Wiederholen Sie den vorherigen Schritt für den Messwert bucket_value_count, aber geben Sie im Feld Name den Wert
Unique quasi-identifier combination lossein.
Wenn Sie fertig sind, sollte die Spalte so aussehen:
Konfigurieren Sie das Diagramm nun so, dass für beide Messwerte ein Liniendiagramm angezeigt wird:
- Klicken Sie auf den Tab Stil im Bereich auf der rechten Seite des Fensters.
- Wählen Sie für die Serien Nr. 1 und Nr. 2 Linie aus.
- Wenn Sie das endgültige Diagramm separat ansehen möchten, klicken Sie auf die Schaltfläche Ansicht in der oberen rechten Ecke des Fensters.
Im Folgenden finden Sie ein Beispieldiagramm nach Abschluss der vorherigen Schritte.
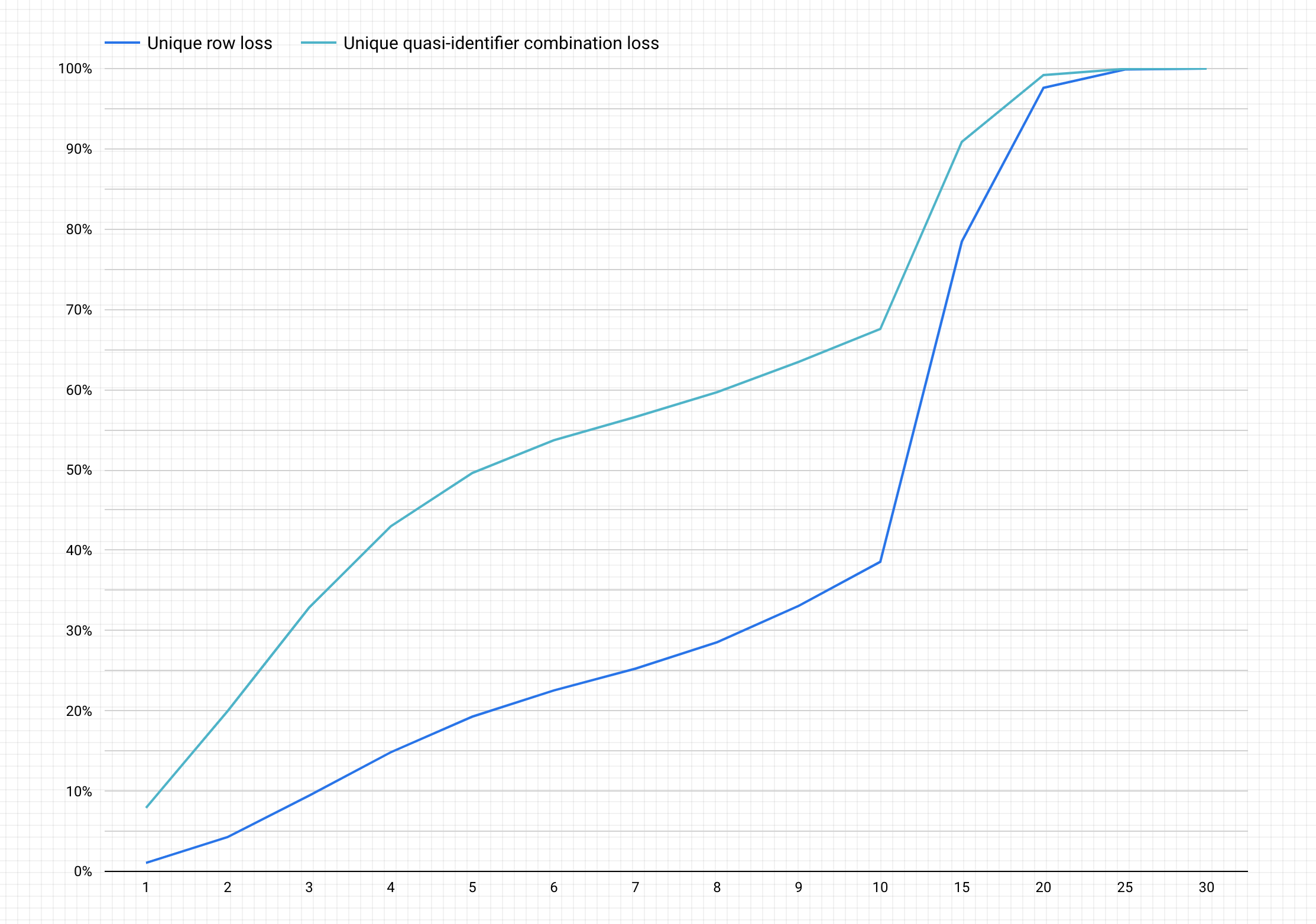
Diagramm interpretieren
Das generierte Diagramm stellt auf der y-Achse den potenziellen Prozentsatz des Datenverlusts sowohl für eindeutige Zeilen als auch für eindeutige Quasi-Identifier-Kombinationen dar, um auf der x-Achse einen k-Anonymitätswert zu erreichen.
Höhere k-Anonymitätswerte weisen auf ein geringeres Risiko einer Re-Identifikation hin. Um höhere k-Anonymitätswerte zu erreichen, müssten Sie jedoch höhere Prozentsätze der gesamten Zeilen und höhere eindeutige Quasi-Identifier-Kombinationen entfernen, was den Nutzen der Daten verringern könnte.
Glücklicherweise ist das Löschen von Daten nicht die einzige Möglichkeit, das Risiko der Re-Identifikation zu verringern. Andere De-Identifikationstechniken können ein besseres Gleichgewicht zwischen Verlust und Nutzen erzielen. Als Abhilfe für den Datenverlust im Zusammenhang mit höheren k-Anonymitätswerten und diesem speziellen Datensatz könnten Sie beispielsweise das Alter oder die Berufsbezeichnung in Buckets fassen, um die Eindeutigkeit der Alter/Berufsbezeichnungs-Kombinationen zu reduzieren. Beispielsweise könnten Sie Alterswerte in Bereiche von 20 bis 25, 25 bis 30, 30 bis 35 und so weiter gruppieren. Weitere Informationen dazu finden Sie unter Generalisierung und Bucketing sowie unter Sensible Daten in Textinhalten de-identifizieren.