本页介绍并比较了两种 Sensitive Data Protection 服务,它们可帮助您了解数据并启用数据治理工作流:发现服务和检查服务。
敏感数据发现
发现服务会监控组织中的数据。此服务会持续运行,并自动发现、分类和分析数据。探索功能可帮助您了解所存储数据的位置和性质,包括您可能不知道的数据资源。未知数据(有时称为影子数据)通常不会像已知数据那样接受相同级别的数据治理和风险管理。
您可以在各种范围内配置发现。您可以为不同的数据子集设置不同的分析时间表。您还可以排除不需要分析的数据子集。
探索性扫描输出:数据剖析文件
探索扫描的输出结果是一组数据分析,其中包含范围内每个数据资源的分析结果。例如,对 BigQuery 或 Cloud SQL 数据进行发现扫描会在项目、表和列级别生成数据剖析文件。
数据剖析包含有关所剖析资源的指标和分析洞见。它包括数据分类(或 infoType)、敏感度级别、数据风险级别、数据大小、数据形状,以及描述数据性质及其数据安全态势(数据安全程度)的其他元素。您可以利用数据分析结果,就如何保护数据做出明智的决策,例如,通过在表上设置访问权限政策。
假设有一个名为 ccn 的 BigQuery 列,其中每行都包含一个唯一的信用卡号,并且没有 null 值。生成的列级数据剖析文件将包含以下详细信息:
| 显示名称 | 值 |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
此外,此列级剖析文件是表级剖析文件的一部分,可提供数据位置、加密状态以及表是否公开共享等数据洞见。在 Google Cloud 控制台中,您还可以查看表的 Cloud Logging 条目,以及具有表角色的 IAM 主账号。
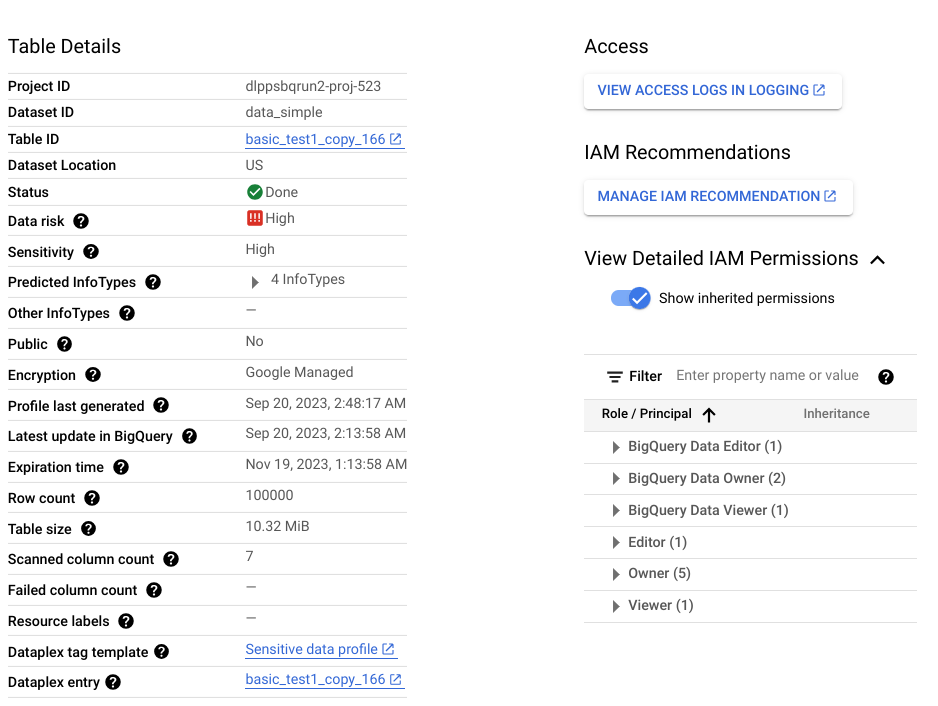
如需查看数据剖析文件中包含的指标和数据洞见的完整列表,请参阅指标参考文档。
何时使用发现功能
在规划数据风险管理方法时,我们建议您先进行发现。发现服务可帮助您全面了解数据,并实现问题提醒、报告和补救。
此外,发现服务还可以帮助您确定非结构化数据可能所在的资源。此类资源可能需要进行详尽的检查。非结构化数据由 0 到 1 之间的高自由文本得分指定。
敏感数据检查
检查服务会对单个资源执行详尽的扫描,以找到每个敏感数据实例。每次检查都会为检测到的每个实例生成一个发现结果。
检查作业提供了一组丰富的配置选项,可帮助您精确定位要检查的数据。例如,您可以启用抽样,将要检查的数据限制为特定行数(对于 BigQuery 数据)或特定文件类型(对于 Cloud Storage 数据)。您还可以指定数据创建或修改的具体时间范围。
与持续监控数据的发现不同,检查是一项按需操作。不过,您可以安排周期性检查作业,即作业触发器。
检查扫描输出:发现结果
每个发现结果都包含详细信息,例如检测到的实例的位置、其潜在的 infoType,以及发现结果与 infoType 匹配的确定性(也称为可能性)。根据您的设置,您还可以获取与发现结果相关的实际字符串;在 Sensitive Data Protection 中,此字符串称为“引用”。
如需查看检查结果中包含的详细信息的完整列表,请参阅 Finding。
何时使用检查
当您需要检查非结构化数据(例如用户创建的评论或评价)并识别个人身份信息 (PII) 的每个实例时,检查功能非常有用。如果发现扫描识别出任何包含非结构化数据的资源,我们建议您对这些资源运行检查扫描,以详细了解每项发现。
何时不应使用检查
如果同时满足以下两个条件,检查资源就没什么用处了。 通过发现扫描,您可以确定是否需要进行检查扫描。
- 资源中只有结构化数据。也就是说,没有自由格式的数据列,例如用户评论或评价。
- 您已经知道该资源中存储的 infoType。
例如,假设发现扫描的数据剖析结果表明,某个 BigQuery 表没有包含非结构化数据的列,但有一个包含唯一信用卡号的列。在这种情况下,检查表格中是否存在信用卡号就没什么用处了。检查将为列中的每个项目生成一个发现。如果您有 100 万行数据,并且每行都包含 1 个信用卡号,则检查作业将针对 CREDIT_CARD_NUMBER infoType 生成 100 万个发现结果。在此示例中,由于发现扫描已表明该列包含唯一的信用卡号,因此无需进行检查。
数据驻留、处理和存储
发现和检查功能均支持数据驻留要求:
- 发现服务会在数据所在的位置处理数据,并将生成的数据分析文件存储在与分析数据相同的区域或多区域中。如需了解详情,请参阅数据驻留注意事项。
- 在检查 Google Cloud 存储系统中的数据时,检查服务会在数据所在的同一区域中处理数据,并将检查作业存储在该区域中。通过混合作业或
content方法检查数据时,检查服务可让您指定应在何处处理数据。如需了解详情,请参阅数据存储方式。
比较摘要:发现和检查服务
| 发现 | 检查 | |
|---|---|---|
| 优势 |
|
|
| 费用 |
在用量模式下,10 TB 的费用约为每月 300 美元。 |
如果是 10 TB,费用大约为每次扫描 10,000 美元。 |
| 支持的数据源 | BigLake BigQuery Cloud Run 函数环境变量 Cloud Run 服务修订版本环境变量 Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore 混合(任意来源)1 |
| 支持的作用域 |
|
单个 BigQuery 表、Cloud Storage 存储桶或 Datastore 种类。 |
| 内置检查模板 | 是 | 是 |
| 内置和自定义 infoType | 是 | 是 |
| 扫描输出 | 所有受支持数据的简要概览(数据分析文件)。 | 被检查资源中敏感数据的具体发现结果。 |
| 将结果保存到 BigQuery | 是 | 是 |
| 以标记形式发送到 Dataplex Universal Catalog(已弃用) | 是 | 是 |
| 以切面形式发送到 Dataplex Universal Catalog | 是 | 否 |
| 将结果发布到 Security Command Center | 是 | 是 |
| 将发现结果发布到 Google Security Operations | 是(对于组织级和文件夹级发现) | 否 |
| 发布到 Pub/Sub | 是 | 是 |
| 数据驻留支持 | 是 | 是 |
1 混合检查采用不同的定价模式。如需了解详情,请参阅检查来自任意来源的数据 。
后续步骤
- 了解用于降低数据风险的推荐策略(本系列的下一个文档)