K-anonymat est une propriété d'ensemble de données qui indique la possibilité de restaurer l'identification de ses enregistrements. Un ensemble de données est considéré comme k-anonyme si les quasi-identifiants de chaque individu dans l'ensemble de données sont identiques à au moins k - 1 autres individus figurant également dans l'ensemble de données.
Vous pouvez calculer la valeur de k-anonymat à partir d'un ou de plusieurs champs ou colonnes d'un ensemble de données. Cet article explique comment calculer des valeurs k-anonymat pour un ensemble de données à l'aide de Sensitive Data Protection. Pour en savoir plus sur la propriété k-anonymat ou l'analyse des risques en général, consultez la section sur les concepts d'analyse des risques avant de continuer.
Avant de commencer
Avant de continuer, assurez-vous d'avoir effectué les actions suivantes :
- Connectez-vous à votre compte Google.
- Dans la console Google Cloud , sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud . Accéder au sélecteur de projet
- Assurez-vous que la facturation est activée pour votre projet Google Cloud . Découvrez comment vérifier que la facturation est activée pour votre projet.
- Activez la protection des données sensibles. Activer la protection des données sensibles
- Sélectionnez un ensemble de données BigQuery à analyser. Sensitive Data Protection calcule la métrique k-anonymat en analysant une table BigQuery.
- Déterminez un identifiant (le cas échéant) et au moins un quasi-identifiant dans l'ensemble de données. Pour en savoir plus, consultez la section Termes et techniques d'analyse des risques.
Calculer k-anonymat
Sensitive Data Protection effectue une analyse des risques chaque fois qu'une tâche d'analyse des risques est exécutée. Vous devez d'abord créer le job à l'aide de la consoleGoogle Cloud , en envoyant une requête d'API DLP ou à l'aide d'une bibliothèque cliente Sensitive Data Protection.
Console
Dans la console Google Cloud , accédez à la page Créer une analyse des risques.
Dans la section Choisir les données d'entrée, spécifiez la table BigQuery à analyser en saisissant l'ID du projet contenant la table, l'ID de l'ensemble de données et le nom de la table.
Sous Métrique de confidentialité à calculer, sélectionnez k-anonymat.
Dans la section ID de tâche, vous pouvez éventuellement attribuer un identifiant personnalisé à la tâche et sélectionner un emplacement de ressource dans lequel la protection des données sensibles traitera vos données. Lorsque vous avez terminé, cliquez sur Continuer.
Dans la section Définir les champs, vous spécifiez les identifiants et les quasi-identifiants pour la tâche d'analyse des risques k-anonymat. La protection des données sensibles accède aux métadonnées de la table BigQuery que vous avez spécifiée à l'étape précédente et tente de remplir la liste des champs.
- Cochez la case appropriée pour spécifier un champ en tant qu'identifiant (ID) ou quasi-identifiant (QI). Vous devez sélectionner 0 ou 1 identifiant et au moins 1 quasi-identifiant.
- Si Sensitive Data Protection ne parvient pas à remplir les champs, cliquez sur Saisir le nom du champ pour saisir manuellement un ou plusieurs champs et définir chacun d'entre eux en tant qu'identifiant ou quasi-identifiant. Lorsque vous avez terminé, cliquez sur Continuer.
Dans la section Ajouter des actions, vous pouvez ajouter des actions facultatives à effectuer lorsque la tâche d'analyse des risques est terminée. Les options disponibles sont les suivantes :
- Enregistrer dans BigQuery : enregistre les résultats de l'analyse des risques dans une table BigQuery.
Publier dans Pub/Sub : publie une notification dans un sujet Pub/Sub.
Notifier par e-mail : vous envoie un e-mail contenant les résultats. Lorsque vous avez terminé, cliquez sur Créer.
La tâche d'analyse des risques de k-anonymat démarre immédiatement.
C#
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
PHP
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
REST
Pour exécuter une nouvelle tâche d'analyse des risques afin de calculer la propriété k-anonymat, envoyez une requête à la ressource projects.dlpJobs, où PROJECT_ID indique votre identifiant de projet :
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
La requête contient un objet RiskAnalysisJobConfig composé des éléments suivants :
Un objet
PrivacyMetric. C'est ici que vous spécifiez que vous calculez la propriété k-anonymat, en incluant un objetKAnonymityConfig.Un objet
BigQueryTable. Spécifiez la table BigQuery à analyser en incluant tous les éléments suivants :projectId: ID du projet contenant la table.datasetId: ID de l'ensemble de données de la table.tableId: nom de la table.
Un ensemble d'un ou de plusieurs objets
Actionreprésentant les actions à exécuter, dans l'ordre indiqué, à la fin de la tâche. Chaque objetActionpeut contenir l'une des actions suivantes :- Objet
SaveFindings: enregistre les résultats de l'analyse des risques dans une table BigQuery. Objet
PublishToPubSub: publie une notification dans un sujet Pub/Sub.Objet
JobNotificationEmails: vous envoie un e-mail contenant les résultats.
Renseignez les éléments suivants dans l'objet
KAnonymityConfig:quasiIds[]: un ou plusieurs quasi-identifiants (objetsFieldId) à analyser et à utiliser pour calculer k-anonymat. Si vous spécifiez plusieurs quasi-identifiants, ceux-ci sont considérés comme une seule clé composite. Les structures et types de données répétés ne sont pas acceptés, mais vous pouvez utiliser des champs imbriqués tant qu'ils ne constituent pas eux-mêmes des structures et qu'ils ne sont pas imbriqués dans un champ répété.entityId: valeur d'identifiant facultative qui, lorsqu'elle est définie, indique que toutes les lignes correspondant à chaque objetentityIddistinct doivent être regroupées pour le calcul de k-anonymat. En général,entityIdcorrespond à une colonne qui représente un utilisateur unique, tel qu'un ID client ou un ID utilisateur. Lorsqu'un objetentityIdapparaît sur plusieurs lignes avec différentes valeurs de quasi-identifiant, ces lignes sont jointes pour former un multiensemble qui sera utilisé comme quasi-identifiant pour cette entité. Pour plus d'informations sur les ID d'entité, consultez la section ID d'entité et calcul de k-anonymat de la page présentant les concepts de l'analyse des risques.
- Objet
Dès que vous envoyez une requête à l'API DLP, la tâche d'analyse des risques démarre.
Répertorier les tâches d'analyse des risques terminées
Vous pouvez afficher une liste des tâches d'analyse des risques qui ont été exécutées dans le projet en cours.
Console
Pour répertorier les tâches d'analyse des risques en cours d'exécution et précédemment exécutées dans la consoleGoogle Cloud , procédez comme suit :
Dans la console Google Cloud , ouvrez la protection des données sensibles.
Cliquez sur l'onglet Tâches et déclencheurs de tâche en haut de la page.
Cliquez sur l'onglet Tâches d'analyse des risques.
La liste des risques s'affiche.
Protocole
Pour répertorier les tâches en cours d'exécution et exécutées précédemment, envoyez une requête GET à la ressource projects.dlpJobs. L'ajout d'un filtre par type de tâche (?type=RISK_ANALYSIS_JOB) permet de limiter la réponse uniquement aux tâches d'analyse des risques.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
La réponse que vous recevez contient une représentation JSON de toutes les tâches d'analyse des risques actuelles et précédentes.
Afficher les résultats d'une tâche k-anonymat
Dans la console Google Cloud , Sensitive Data Protection propose des visualisations intégrées pour les tâches k-anonymat terminées. Après avoir suivi les instructions de la section précédente, dans la liste de tâches d'analyse des risques, sélectionnez la tâche pour laquelle vous souhaitez afficher les résultats. En supposant que la tâche a bien été exécutée, la partie supérieure de la page Détails de l'analyse des risques se présente comme suit :
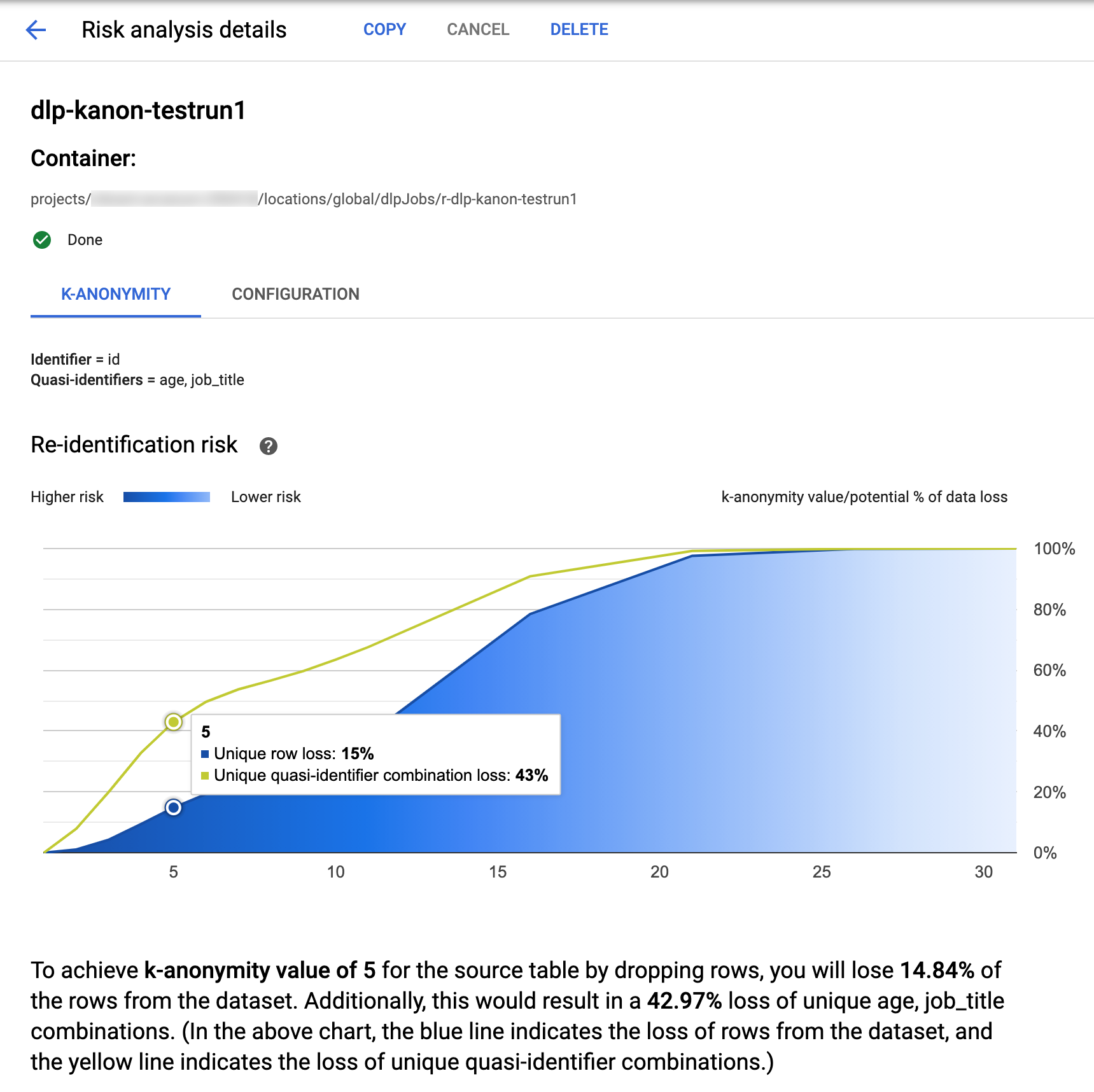
En haut de la page, vous trouverez des informations sur la tâche k-anonymat, y compris son ID de tâche et, sous Conteneur, son emplacement de ressource.
Pour afficher les résultats du calcul de k-anonymat, cliquez sur l'onglet K-anonymat. Pour afficher la configuration de la tâche d'analyse des risques, cliquez sur l'onglet Configuration.
L'onglet K-anonymat répertorie d'abord l'ID d'entité (le cas échéant) et les quasi-identifiants utilisés pour calculer k-anonymat.
Graphique des risques
Le graphique de Risque de restauration de l'identification présente, sur l'axe y, le pourcentage potentiel de perte de données pour les lignes uniques et les combinaisons de quasi-identifiants uniques afin d'obtenir, sur l'axe x, une valeur k-anonymat. La couleur du graphique indique également le risque potentiel. Des nuances de bleu plus sombres indiquent un risque plus élevé, tandis que des nuances plus claires indiquent un risque moins élevé.
Plus la valeur k-anonymat est élevée, plus le risque de restauration de l'identification est faible. Toutefois, pour obtenir des valeurs k-anonymat plus élevées, vous devez supprimer les pourcentages les plus élevés du nombre total de lignes et les combinaisons de quasi-identifiants uniques les plus élevées, ce qui peut réduire l'utilité des données. Pour afficher une valeur spécifique de perte potentielle en pourcentage pour une certaine valeur k-anonymat, passez votre curseur sur le graphique. Comme le montre la capture d'écran, une info-bulle apparaît sur le graphique.
Pour afficher plus de détails sur une valeur k-anonymat spécifique, cliquez sur le point de données correspondant. Une explication détaillée s'affiche sous le graphique, et un exemple de table de données apparaît plus bas sur la page.
Table d'exemples de données sur les risques
Le deuxième composant de la page des résultats de tâche d'analyse des risques est l'exemple de table de données. Il affiche les combinaisons de quasi-identifiants pour une valeur k-anonymat cible donnée.
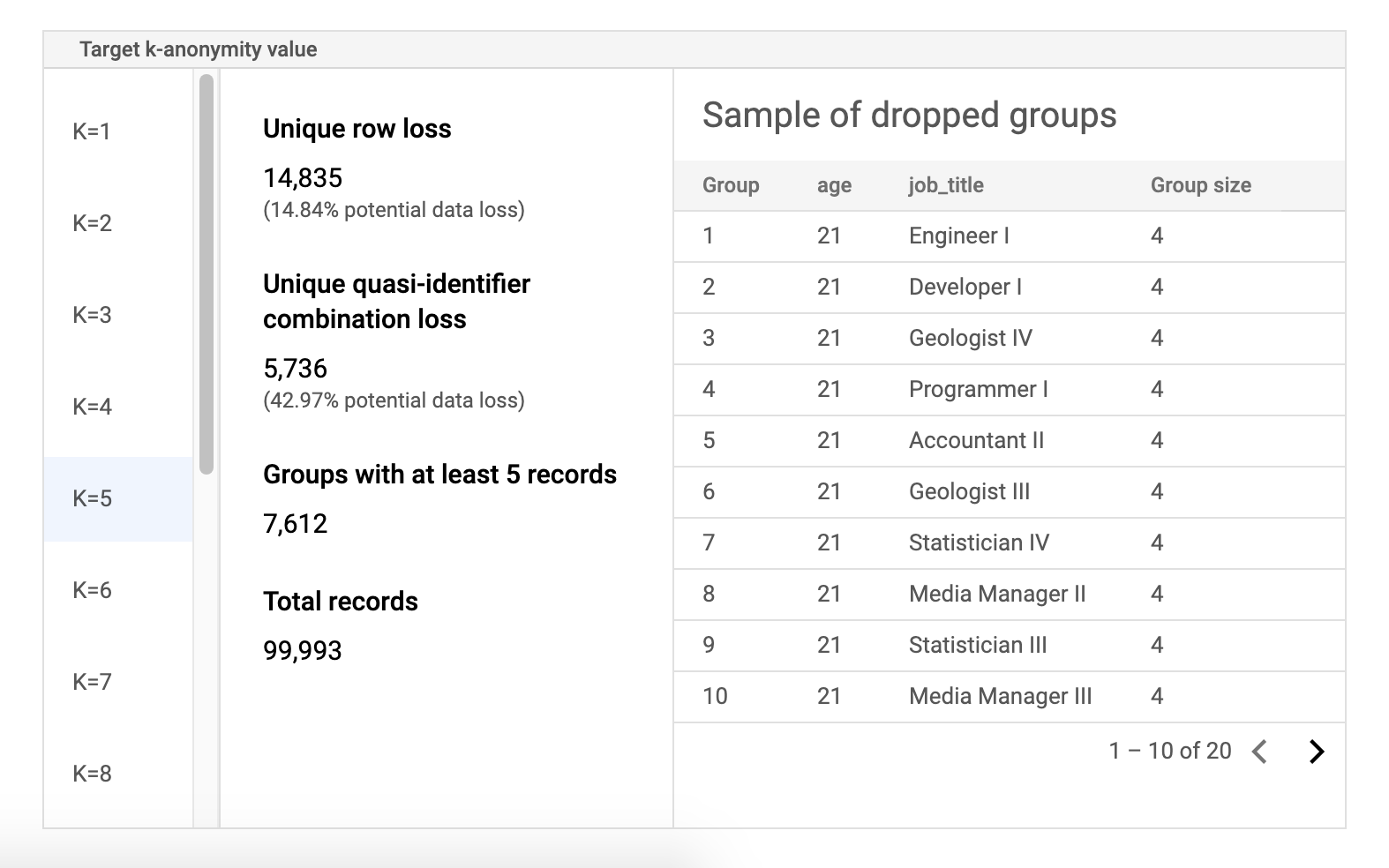
La première colonne du tableau répertorie les valeurs k-anonymat. Cliquez sur une valeur k-anonymat pour afficher les exemples de données correspondants à supprimer pour atteindre cette valeur.
La deuxième colonne indique la perte potentielle de données correspondante des lignes uniques et des combinaisons de quasi-identifiants, ainsi que le nombre de groupes avec au moins k enregistrements et le nombre total d'enregistrements.
La dernière colonne affiche un échantillon de groupes partageant une combinaison de quasi-identifiants, ainsi que le nombre d'enregistrements qui existent pour cette combinaison.
Récupérer les détails de la tâche à l'aide de REST
Pour récupérer les résultats de la tâche d'analyse des risques k-anonymat à l'aide de l'API REST, envoyez la requête GET suivante à la ressource projects.dlpJobs. Remplacez PROJECT_ID par votre ID de projet et JOB_ID par l'identifiant de la tâche pour laquelle vous souhaitez obtenir des résultats.
L'ID de tâche a été renvoyé au démarrage de la tâche et peut être récupéré en répertoriant toutes les tâches.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
La requête renvoie un objet JSON contenant une instance de la tâche. Les résultats de l'analyse se trouvent dans la clé "riskDetails", dans un objet AnalyzeDataSourceRiskDetails. Pour en savoir plus, consultez la documentation de référence de l'API pour la ressource DlpJob.
Exemple de code : calculer le k-anonymat avec un ID d'entité
Cet exemple crée un job d'analyse des risques qui calcule le k-anonymat avec un ID d'entité.
Pour en savoir plus sur les ID d'entité, consultez ID d'entité et calcul de k-anonymat.
C#
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
PHP
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour la protection des données sensibles, consultez la page Bibliothèques clientes de la protection des données sensibles.
Pour vous authentifier auprès de la protection des données sensibles, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Étapes suivantes
- Découvrez comment calculer la valeur l-diversité pour un ensemble de données.
- Découvrez comment calculer la valeur k-table pour un ensemble de données.
- Découvrez comment calculer la valeur δ-présence pour un ensemble de données.