생성 성공한 모든 데이터 프로필을 BigQuery로 전송하도록 민감한 데이터 검색 서비스를 구성한 경우 해당 데이터 프로필을 쿼리하여 데이터에 대한 통계를 얻을 수 있습니다. 또한 Looker Studio와 같은 시각화 도구를 사용하여 비즈니스 요구에 따라 맞춤화된 커스텀 보고서를 빌드할 수 있습니다. 또는 Sensitive Data Protection에서 제공하는 사전 제작된 보고서를 사용하고, 이를 미세 조정하고, 필요에 따라 공유할 수 있습니다.
이 페이지에서는 데이터 프로필에 대해 자세히 알아보기 위해 사용할 수 있는 SQL 쿼리 예시를 보여줍니다. 또한 Looker Studio에서 데이터 프로필을 시각화하는 방법을 보여줍니다.
데이터 프로필에 대한 자세한 내용은 데이터 프로필을 참고하세요.
시작하기 전에
이 페이지에서는 조직, 폴더 또는 프로젝트 수준에서 프로파일링을 구성했다고 가정합니다. 검색 스캔 구성에서 BigQuery에 데이터 프로필 사본 저장 작업이 사용 설정되어 있는지 확인합니다. 검색 스캔 구성을 만드는 방법에 관한 자세한 내용은 스캔 구성 만들기를 참고하세요.
이 문서에서는 내보낸 데이터 프로필이 포함된 테이블을 출력 테이블이라고 부릅니다.
출력 테이블의 프로젝트 ID, 데이터 세트 ID, 테이블 ID를 즉시 사용할 수 있는지 확인합니다. 이 페이지의 절차를 수행하려면 필요합니다.
latest 뷰
Sensitive Data Protection은 데이터 프로필을 출력 테이블에 내보낼 때 latest 뷰도 만듭니다. 이 뷰는 데이터 프로필 중 최신 스냅샷만 포함된 사전 필터링된 가상 테이블입니다. latest 뷰는 스키마가 출력 테이블과 동일하므로 SQL 쿼리 및 Looker Studio 보고서에서 이 둘을 상호 교환하여 사용할 수 있습니다. 출력 테이블에 데이터 프로필의 이전 스냅샷이 포함되기 때문에 결과가 다를 수 있습니다.
latest 뷰는 출력 테이블과 동일한 위치에 저장됩니다. 이름은 형식이 다음과 같습니다.
OUTPUT_TABLE_latest_VERSION
다음을 바꿉니다.
- OUTPUT_TABLE: 내보낸 데이터 프로필을 포함하는 테이블의 ID입니다.
- VERSION: 뷰의 버전 번호입니다.
예를 들어 출력 테이블 이름이 table-profile이면 latest 뷰 이름은 table-profile_latest_v1과 같습니다.

SQL 쿼리에서 latest 뷰를 사용할 때는 프로젝트 ID, 데이터 세트 ID, 테이블 ID, 서픽스가 포함된 뷰 전체 이름(예: myproject.mydataset.table-profile_latest_v1)을 사용합니다.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
출력 테이블과 latest 뷰 중에서 선택
latest 뷰에는 최신 데이터 프로필 스냅샷만 포함되는 반면 출력 테이블에는 오래된 스냅샷을 포함한 모든 데이터 프로필 스냅샷이 있습니다. 예를 들어 출력 테이블의 쿼리는 동일 열의 여러 열 데이터 프로필을 해당 열이 프로파일링될 때마다 하나씩 반환할 수 있습니다.
SQL 쿼리 또는 Looker Studio 보고서에서 출력 테이블과 latest 뷰 중 하나를 선택할 때 다음 사항을 고려하세요.
latest뷰는 다시 프로파일링된 데이터 애셋이 있고 이전 버전이 아닌 최신 프로필만 보려는 경우에 유용합니다. 즉, 프로필 데이터의 현재 상태를 확인해야 할 수 있습니다.출력 테이블은 프로필 데이터의 이전 뷰를 확인하려는 경우에 유용합니다. 예를 들어 조직에서 특정 infoType을 저장했는지 확인해야 하거나 특정 데이터 프로필에 적용된 변경사항을 확인해야 할 수 있습니다.
샘플 SQL 쿼리
이 섹션에서는 데이터 프로필을 분석할 때 사용할 수 있는 쿼리 예시를 제공합니다. 이러한 쿼리를 실행하려면 대화형 쿼리 실행을 참조하세요.
다음 예시에서 TABLE_OR_VIEW를 다음 중 하나로 바꿉니다.
- 내보낸 데이터 프로필이 포함된 테이블인 출력 테이블의 이름(예:
myproject.mydataset.table-profile) - 출력 테이블의
latest뷰 이름(예:myproject.mydataset.table-profile_latest_v1)
두 이름 모두 프로젝트 ID와 데이터 세트 ID를 포함해야 합니다.
자세한 내용은 이 페이지의 출력 테이블과 latest 뷰 중에서 선택을 참조하세요.
발생한 오류를 해결하려면 오류 메시지를 참조하세요.
자유 텍스트 점수가 높고 다른 infoType 일치에 대한 증거가 있는 모든 열 나열
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
이러한 발견 항목을 해결하는 방법에 대한 자세한 내용은 데이터 위험 완화를 위한 권장 전략을 참고하세요.
자유 텍스트 점수 및 기타 infoType 측정항목에 대한 자세한 내용은 열 데이터 프로필을 참조하세요.
신용카드 번호 열이 포함된 모든 테이블 나열
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER는 신용카드 번호를 나타내는 기본 제공 infoType입니다.
이러한 발견 항목을 해결하는 방법에 대한 자세한 내용은 데이터 위험 완화를 위한 권장 전략을 참고하세요.
신용카드 번호, 미국 사회보장번호, 사람 이름 열이 포함된 테이블 프로필 나열
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
이 쿼리는 다음과 같은 기본 제공 infoType을 사용합니다.
CREDIT_CARD_NUMBER: 신용카드 번호를 나타냅니다.PERSON_NAME: 개인의 전체 이름을 나타냅니다.US_SOCIAL_SECURITY_NUMBER는 미국 사회보장번호를 나타냅니다.
이러한 발견 항목을 해결하는 방법에 대한 자세한 내용은 데이터 위험 완화를 위한 권장 전략을 참고하세요.
민감도 점수가 SENSITIVITY_HIGH인 버킷을 나열합니다.
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
자세한 내용은 파일 스토어 데이터 프로필을 참고하세요.
민감도 점수가 SENSITIVITY_HIGH인 스캔된 모든 버킷 경로, 클러스터, 파일 확장자 목록을 표시합니다.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
자세한 내용은 파일 스토어 데이터 프로필을 참고하세요.
신용카드 번호가 감지된 스캔된 모든 버킷 경로, 클러스터, 파일 확장자 나열
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER는 신용카드 번호를 나타내는 기본 제공 infoType입니다.
자세한 내용은 파일 스토어 데이터 프로필을 참고하세요.
신용카드 번호, 사람 이름 또는 미국 사회보장번호가 감지된 버킷 경로, 클러스터, 파일 확장자를 모두 나열합니다.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
이 쿼리는 다음과 같은 기본 제공 infoType을 사용합니다.
CREDIT_CARD_NUMBER: 신용카드 번호를 나타냅니다.PERSON_NAME: 개인의 전체 이름을 나타냅니다.US_SOCIAL_SECURITY_NUMBER는 미국 사회보장번호를 나타냅니다.
자세한 내용은 파일 스토어 데이터 프로필을 참고하세요.
Looker Studio에서 데이터 프로필 작업
Looker Studio에서 데이터 프로필을 시각화하려면 사전 제작된 보고서를 사용하거나 보고서를 직접 만들 수 있습니다.
사전 제작된 보고서 사용
Sensitive Data Protection은 데이터 프로필의 다양한 정보를 강조표시하는 사전 제작된 Looker Studio 보고서를 제공합니다. Sensitive Data Protection 대시보드는 여러 페이지로 된 보고서로서 위험별, infoType별, 위치별 분석을 포함한 데이터 프로필에 관한 간단하고도 대략적인 뷰를 제공합니다. 다른 탭을 탐색하여 지리적 리전 및 상태 위험별 보기를 확인하거나 특정 측정항목을 상세히 살펴봅니다. 사전 제작된 보고서를 있는 그대로 사용하거나 필요에 따라 맞춤설정할 수 있습니다. 이 버전의 사전 제작 보고서가 권장됩니다.
데이터가 포함된 사전 제작된 보고서를 보려면 다음 URL에 필요한 값을 입력합니다. 그런 다음 결과 URL을 브라우저에 복사합니다.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
다음을 바꿉니다.
- PROJECT_ID: 출력 테이블이 포함된 프로젝트입니다.
- DATASET_ID: 출력 테이블이 포함된 데이터 세트입니다.
TABLE_OR_VIEW: 다음 중 하나입니다.
- 내보낸 데이터 프로필이 포함된 테이블인 출력 테이블의 이름(예:
myproject.mydataset.table-profile) - 출력 테이블의
latest뷰 이름(예:myproject.mydataset.table-profile_latest_v1)
자세한 내용은 이 페이지의 출력 테이블과
latest뷰 중에서 선택을 참조하세요.- 내보낸 데이터 프로필이 포함된 테이블인 출력 테이블의 이름(예:
Looker Studio가 데이터가 포함된 보고서를 로드하는 데 몇 분 정도 걸릴 수 있습니다. 오류가 발생하거나 보고서가 로드되지 않으면 이 페이지의 사전 제작된 보고서의 오류 문제 해결하기를 참고하세요.
다음 예에서 대시보드는 민감도가 낮은 데이터와 민감도가 높은 데이터가 전 세계 여러 국가에 있음을 보여줍니다.
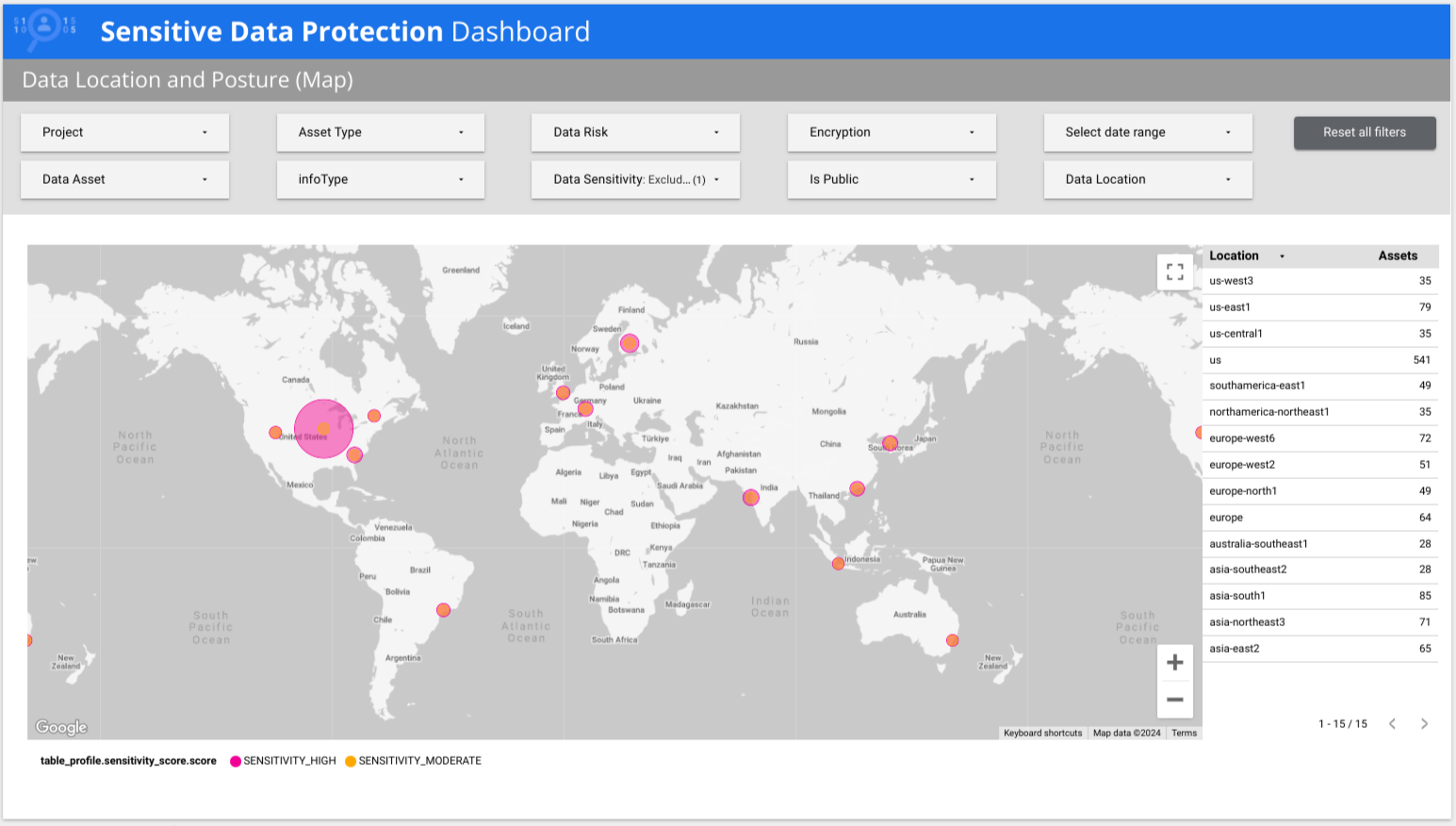
사전 제작된 보고서의 이전 버전
사전 제작된 보고서의 첫 번째 버전은 다음 주소에서 계속 사용할 수 있습니다.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
보고서 생성
Looker Studio를 사용하면 대화형 보고서를 만들 수 있습니다. 이 섹션에서는 Looker Studio에서 BigQuery의 출력 테이블로 내보낸 데이터 프로필을 기반으로 하는 간단한 테이블 보고서를 만듭니다.
프로젝트 ID, 데이터 세트 ID, 출력 테이블의 테이블 ID, latest 뷰를 즉시 사용할 수 있는지 확인합니다. 이 절차를 수행하려면 필요합니다.
이 예시에서는 데이터 프로필에 보고된 각 infoType과 해당 빈도를 보여주는 테이블을 포함하는 보고서를 만드는 방법을 보여줍니다.
일반적으로 Looker Studio를 통해 BigQuery에 액세스하면 BigQuery 사용 비용이 발생합니다. 자세한 내용은 Looker Studio를 사용하여 BigQuery 데이터 시각화를 참조하세요.
보고서를 작성하려면 다음을 수행합니다.
- Looker Studio를 열고 로그인합니다.
- 빈 보고서를 클릭합니다.
- 데이터에 연결 탭에서 BigQuery 카드를 클릭합니다.
- 메시지가 표시되면 Looker Studio가 BigQuery 프로젝트에 액세스할 수 있도록 승인합니다.
BigQuery 데이터에 연결합니다.
- 프로젝트에서 출력 테이블이 포함된 프로젝트를 선택합니다. 최근 프로젝트, 내 프로젝트, 공유 프로젝트 탭에서 프로젝트를 검색할 수 있습니다.
- 데이터 세트에서 출력 테이블이 포함된 데이터 세트를 선택합니다.
테이블에서 출력 테이블 또는 출력 테이블의
latest뷰를 선택합니다.자세한 내용은 이 페이지의 출력 테이블과
latest뷰 중에서 선택을 참조하세요.Add(추가)를 클릭합니다.
표시되는 대화상자에서 보고서에 추가를 클릭합니다.
보고된 각 infoType과 해당 빈도(레코드 수)를 보여주는 테이블을 추가하려면 다음 단계를 따르세요.
- 차트 추가를 클릭합니다.
- 테이블 스타일을 선택합니다.
차트를 배치할 영역을 클릭합니다.
차트가 테이블 형식으로 표시됩니다.
필요에 따라 테이블의 크기를 조정합니다.
표가 선택되어 있으면 차트 창에 속성이 표시됩니다.
차트 창의 설정 탭에서 사전 선택된 측정기준 및 측정항목을 삭제합니다.
측정기준에
column_profile.column_info_type.info_type.name또는file_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name를 추가합니다.이 예에서는 열 및 파일 클러스터 수준에서 데이터를 제공합니다. 다른 측정기준을 사용해 볼 수도 있습니다. 예를 들어 테이블 수준 및 버킷 수준 측정기준을 사용할 수 있습니다.
측정항목에 레코드 수를 추가합니다.
결과 테이블이 다음과 비슷하게 표시됩니다.

Looker Studio의 테이블에 대해 자세히 알아보세요.
사전 제작된 보고서의 오류 문제 해결하기
사전 제작된 보고서를 로드할 때 오류, 누락된 컨트롤 또는 누락된 차트가 표시되면 사전 제작된 보고서에서 최신 필드를 사용하고 있는지 확인하세요.
사전 제작된 보고서가 출력 테이블에 연결되어 있는 경우 이 테이블이 활성 검색 스캔 구성에 연결되어 있는지 확인합니다. 스캔 구성의 설정을 보려면 스캔 구성 보기를 참고하세요.
사전 제작된 보고서가
latest뷰에 연결되어 있는 경우 이 뷰가 BigQuery에 아직 있는지 확인합니다. 있는 경우 뷰를 변경해 보세요. 또는 뷰를 복사하고 사전 제작된 보고서를 해당 사본에 연결합니다.latest뷰에 대한 자세한 내용은 이 페이지의latest뷰를 참고하세요.
이 단계를 시도한 후에도 오류가 계속 발생하면 Cloud 고객 지원팀에 문의하세요.
다음 단계
데이터 프로필 발견 항목을 해결하기 위해 취할 수 있는 조치 알아보기