Si ha configurado el servicio de detección de datos sensibles para enviar todos los perfiles de datos generados correctamente a BigQuery, puede consultar esos perfiles para obtener información valiosa sobre sus datos. También puede usar herramientas de visualización como Looker Studio para crear informes personalizados que se adapten a las necesidades de su empresa. También puede usar un informe prediseñado que proporcione Protección de Datos Sensibles, ajustarlo y compartirlo según sea necesario.
En esta página se proporcionan consultas de SQL de ejemplo que puedes usar para obtener más información sobre tus perfiles de datos. También se explica cómo visualizar perfiles de datos en Looker Studio.
Para obtener más información sobre los perfiles de datos, consulta Perfiles de datos.
Antes de empezar
En esta página se da por hecho que has configurado la creación de perfiles a nivel de organización, carpeta o proyecto. En la configuración del análisis de descubrimiento, asegúrate de que la acción Guardar copias de perfiles de datos en BigQuery esté habilitada. Para obtener más información sobre cómo crear una configuración de análisis de descubrimiento, consulta Crear una configuración de análisis.
En este documento, la tabla que contiene los perfiles de datos exportados se denomina tabla de salida.
Asegúrate de tener a mano el ID del proyecto, el ID del conjunto de datos y el ID de la tabla de salida. Los necesitarás para llevar a cabo los procedimientos que se describen en esta página.
Vista latest
Cuando Protección de Datos Sensibles exporta perfiles de datos a tu tabla de salida, también crea la latest vista. Esta vista es una tabla virtual prefiltrada que solo incluye las últimas instantáneas de tus perfiles de datos. La vista latest tiene el mismo esquema que la tabla de resultados, por lo que puedes usar ambas indistintamente en tus consultas de SQL e informes de Looker Studio. Los resultados pueden ser diferentes porque la tabla de salida contiene versiones anteriores de los perfiles de datos.
La vista latest se almacena en la misma ubicación que la tabla de salida. Su nombre tiene el siguiente formato:
OUTPUT_TABLE_latest_VERSION
Haz los cambios siguientes:
- OUTPUT_TABLE: ID de la tabla que contiene los datos exportados. profiles.
- VERSION: número de versión de la vista.
Por ejemplo, si la tabla de resultados se llama table-profile, la vista latest
tendrá un nombre como table-profile_latest_v1.

Cuando uses la vista latest en consultas SQL, usa el nombre completo de la vista, que incluye el ID del proyecto, el ID del conjunto de datos, el ID de la tabla y el sufijo. Por ejemplo, myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Elegir entre la tabla de resultados y la vista latest
La vista latest solo incluye las últimas capturas de perfil de datos, mientras que la tabla de resultados contiene todas las capturas de perfil de datos, incluidas las que están obsoletas. Por ejemplo, una consulta en la tabla de salida puede devolver varios perfiles de datos de columna de la misma columna, uno por cada vez que se haya creado un perfil de esa columna.
Cuando tengas que elegir entre usar la tabla de resultados y la latestvista en tus consultas de SQL o informes de Looker Studio, ten en cuenta lo siguiente:
La vista
latestes útil si tienes recursos de datos que se han vuelto a perfilar y solo quieres ver los perfiles más recientes, no sus versiones anteriores. Es decir, quieres ver el estado actual de los datos de tu perfil.La tabla de resultados es útil si quieres obtener un historial de los datos de tu perfil. Por ejemplo, quieres determinar si tu organización ha almacenado alguna vez un infoType concreto o quieres ver los cambios que ha experimentado un perfil de datos específico.
Consultas de SQL de ejemplo
En esta sección se proporcionan ejemplos de consultas que puede usar al analizar perfiles de datos. Para ejecutar estas consultas, consulta Ejecutar consultas interactivas.
En los siguientes ejemplos, sustituya TABLE_OR_VIEW por una de las siguientes opciones:
- Nombre de la tabla de salida, que es la tabla que contiene los perfiles de datos exportados (por ejemplo,
myproject.mydataset.table-profile). - El nombre de la
latestvista de la tabla de resultados. Por ejemplo,myproject.mydataset.table-profile_latest_v1.
En cualquier caso, debe incluir el ID del proyecto y el ID del conjunto de datos.
Para obtener más información, consulta la sección Elegir entre la tabla de resultados y la vista latest de esta página.
Para solucionar los errores que encuentres, consulta la sección Mensajes de error.
Enumera todas las columnas que tengan una puntuación de texto libre alta y pruebas de otras coincidencias de infoType
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Para obtener información sobre cómo solucionar estos problemas, consulta Estrategias recomendadas para mitigar los riesgos de los datos.
Para obtener más información sobre las métricas Puntuación de texto libre y Otros infoTypes, consulta Perfiles de datos de columnas.
Lista de todas las tablas que contienen una columna de números de tarjetas de crédito
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER es un infoType integrado
que representa un número de tarjeta de crédito.
Para obtener información sobre cómo solucionar estos problemas, consulta Estrategias recomendadas para mitigar los riesgos de los datos.
Lista de perfiles de tabla que contienen columnas de números de tarjetas de crédito, números de la seguridad social de EE. UU. y nombres de personas
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
Esta consulta usa los siguientes infoTypes integrados:
CREDIT_CARD_NUMBER: representa un número de tarjeta de crédito.PERSON_NAME: representa el nombre completo de una persona.US_SOCIAL_SECURITY_NUMBERrepresenta un número de la seguridad social de EE. UU.
Para obtener información sobre cómo solucionar estos problemas, consulta Estrategias recomendadas para mitigar los riesgos de los datos.
Lista los contenedores en los que la puntuación de sensibilidad es SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Para obtener más información, consulta Perfiles de datos de almacén de archivos.
Lista todas las rutas de los contenedores, los clústeres y las extensiones de archivo analizados en los que la puntuación de sensibilidad es SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Para obtener más información, consulta Perfiles de datos de almacén de archivos.
Lista de todas las rutas de los segmentos, los clústeres y las extensiones de archivo analizados en los que se han detectado números de tarjetas de crédito
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER es un infoType integrado
que representa un número de tarjeta de crédito.
Para obtener más información, consulta Perfiles de datos de almacén de archivos.
Lista todas las rutas de los contenedores, los clústeres y las extensiones de archivo analizados en los que se ha detectado un número de tarjeta de crédito, un nombre de persona o un número de la seguridad social de EE. UU.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
Esta consulta usa los siguientes infoTypes integrados:
CREDIT_CARD_NUMBER: representa un número de tarjeta de crédito.PERSON_NAME: representa el nombre completo de una persona.US_SOCIAL_SECURITY_NUMBERrepresenta un número de la seguridad social de EE. UU.
Para obtener más información, consulta Perfiles de datos de almacén de archivos.
Trabajar con perfiles de datos en Looker Studio
Para visualizar sus perfiles de datos en Looker Studio, puede usar un informe prediseñado o crear uno propio.
Usar un informe prediseñado
Protección de Datos Sensibles ofrece un informe de Looker Studio predefinido que destaca las valiosas estadísticas de los perfiles de datos. El panel de control Protección de Datos Sensibles es un informe de varias páginas que ofrece una vista general rápida de sus perfiles de datos, incluidos los desgloses por riesgo, por infoType y por ubicación. Explora las otras pestañas para ver las vistas por región geográfica y riesgo de postura, o desglosa métricas específicas. Puedes usar este informe prediseñado tal cual o personalizarlo según tus necesidades. Esta es la versión recomendada del informe predefinido.
Para ver el informe prediseñado con sus datos, introduzca los valores necesarios en la siguiente URL. A continuación, copia la URL resultante en tu navegador.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Haz los cambios siguientes:
- PROJECT_ID: el proyecto que contiene la tabla de salida.
- DATASET_ID: el conjunto de datos que contiene la tabla de salida.
TABLE_OR_VIEW: una de las siguientes opciones:
- Nombre de la tabla de salida, que es la tabla que contiene los perfiles de datos exportados (por ejemplo,
myproject.mydataset.table-profile). - El nombre de la
latestvista de la tabla de resultados. Por ejemplo,myproject.mydataset.table-profile_latest_v1.
Para obtener más información, consulta la sección Elegir entre la tabla de resultados y la vista
latestde esta página.- Nombre de la tabla de salida, que es la tabla que contiene los perfiles de datos exportados (por ejemplo,
Looker Studio puede tardar unos minutos en cargar el informe con tus datos. Si se producen errores o el informe no se carga, consulta la sección Solucionar errores con el informe prediseñado de esta página.
En el siguiente ejemplo, el panel de control muestra que hay datos de baja y alta sensibilidad en varios países de todo el mundo.
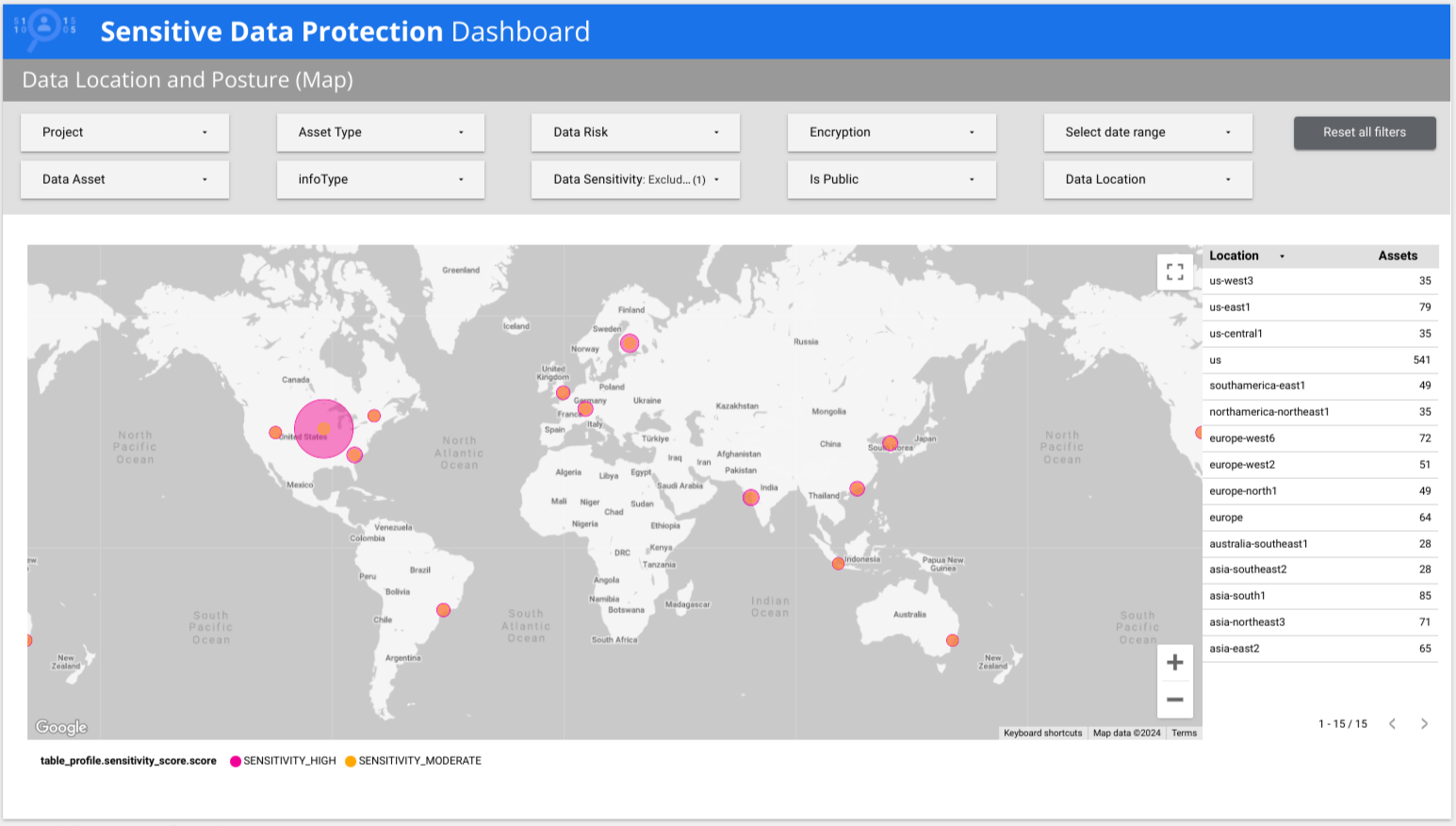
Versión anterior del informe predefinido
La primera versión del informe predefinido sigue disponible en la siguiente dirección:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Crear un informe
Looker Studio te permite crear informes interactivos. En esta sección, creará un informe de tabla sencillo en Looker Studio basado en los perfiles de datos exportados a su tabla de salida en BigQuery.
Asegúrate de tener a mano el ID del proyecto, el ID del conjunto de datos y el ID de la tabla de salida o de la latestvista. Los necesitas para llevar a cabo este procedimiento.
En este ejemplo se muestra cómo crear un informe que contenga una tabla en la que se muestre cada infoType registrado en sus perfiles de datos y su frecuencia correspondiente.
Por lo general, se aplican costes por el uso de BigQuery si accedes a BigQuery a través de Looker Studio. Para obtener más información, consulta el artículo sobre cómo visualizar datos de BigQuery con Looker Studio.
Para crear un informe, siga estos pasos:
- Abre Looker Studio e inicia sesión.
- Haz clic en Informe en blanco.
- En la pestaña Conectarse a datos, haga clic en la tarjeta BigQuery.
- Si se te solicita, autoriza a Looker Studio a acceder a tus proyectos de BigQuery.
Conéctate a tus datos de BigQuery:
- En Proyecto, selecciona el proyecto que contiene la tabla de salida. Puedes buscar el proyecto en las pestañas Proyectos recientes, Mis proyectos y Proyectos compartidos.
- En Conjunto de datos, selecciona el conjunto de datos que contiene la tabla de salida.
En Tabla, selecciona la tabla de salida o la vista
latestde la tabla de salida.Para obtener más información, consulta la sección Elegir entre la tabla de resultados y la vista
latestde esta página.Haz clic en Añadir.
En el cuadro de diálogo que aparece, haz clic en Añadir al informe.
Para añadir una tabla que muestre cada infoType registrado y su frecuencia correspondiente (número de registros), sigue estos pasos:
- Haz clic en Añadir un gráfico.
- Selecciona un estilo de tabla.
Haz clic en el área donde quieras colocar el gráfico.
El gráfico se muestra en formato de tabla.
Cambia el tamaño de la tabla según sea necesario.
Mientras la tabla esté seleccionada, sus propiedades aparecerán en el panel Gráfico.
En el panel Gráfico, en la pestaña Configuración, quite las dimensiones y métricas preseleccionadas.
En Dimensión, añade
column_profile.column_info_type.info_type.nameofile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name.Estos ejemplos proporcionan datos a nivel de columna y de clúster de archivos. También puedes probar con otras dimensiones. Por ejemplo, puede usar dimensiones a nivel de tabla y a nivel de contenedor.
En Métrica, añada Recuento de registros.
La tabla resultante tendrá un aspecto similar al siguiente:
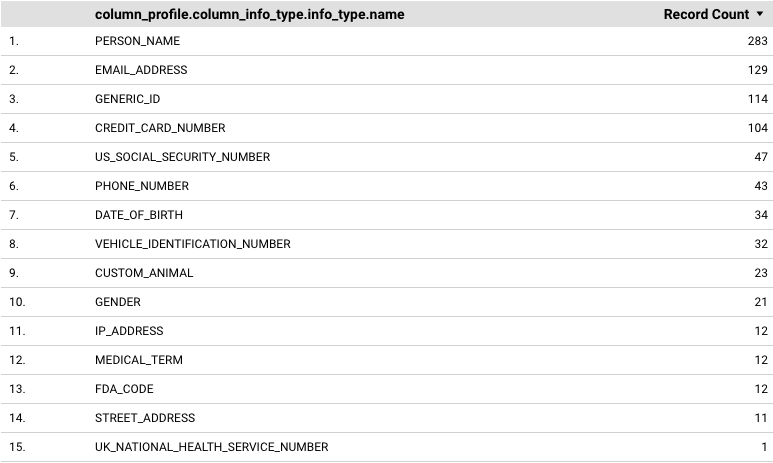
Más información sobre las tablas en Looker Studio
Solucionar errores en el informe prediseñado
Si ve algún error, faltan controles o faltan gráficos al cargar el informe prediseñado, asegúrese de que este utiliza los campos más recientes:
Si tu informe predefinido está conectado a la tabla de resultados, confirma que esta tabla está adjunta a una configuración de análisis de descubrimiento activa. Para ver los ajustes de tus configuraciones de análisis, consulta Ver una configuración de análisis.
Si el informe prediseñado está conectado a la vista
latest, compruebe que esta vista sigue presente en BigQuery. Si está presente, prueba a hacer un cambio en la vista. También puedes hacer una copia de la vista y conectar el informe prediseñado a esa copia. Para obtener más información sobre la vistalatest, consulta la sección Vistalatestde esta página.
Si sigues viendo errores después de probar estos pasos, ponte en contacto con el equipo de Asistencia de Google Cloud.
Siguientes pasos
Consulta las acciones que puedes llevar a cabo para corregir los resultados del perfil de datos.