Cloud Profiler 總覽
想要瞭解實際運作系統的效能極為困難,就算嘗試評估測試環境中的效能,通常也無法如法炮製系統實際運作時所面臨的壓力。將應用程式各部分微基準化雖然有時是可行的做法,但通常同樣也無法複製整個實際運作系統的工作負載和行為。
持續剖析實際運作系統,確實能有效掌握服務在工作環境中運作時,相關資源 (如 CPU 週期和記憶體) 是由服務的哪些部分使用。只不過剖析會對實際運作系統帶來額外負載,因此想要以合理方式來找出資源使用模式,額外的剖析負載必須很小。
Cloud Profiler 是具有統計功能的低負擔分析器,可持續從實際工作環境中的應用程式收集 CPU 使用狀況和記憶體分配資訊;且可將這些資訊按產生該資訊的原始碼歸類,協助您識別使用最多資源的應用程式部分,並進一步掌握應用程式的效能特性。
可用的剖析類型
Cloud Profiler 支援的剖析類型因程式的撰寫語言而異。下表按語言列出支援的剖析類型:
| 剖析類型 | Go | Java | Node.js | Python |
|---|---|---|---|---|
| CPU 作業時間 | 有 | Y | 有 | |
| 堆積 | 有 | Y | 有 | |
| 分配的堆積 | 有 | |||
| [Contention] (爭用情況) | 有 | |||
| [Threads] (執行緒) | 有 | |||
| 實際時間 | 有 | Y | 是 |
如需語言要求和任何限制的完整資訊,請參閱該語言的使用指南頁面。如要進一步瞭解這些剖析類型,請參閱剖析概念。
支援的設定
當您設定應用程式以擷取剖析資料時,您必須加入特定語言的剖析代理程式。下表大致列出支援的環境:
| 環境 | Go | Java | Node.js | Python |
|---|---|---|---|---|
| Compute Engine | 有 | Y | Y | 有 |
| Google Kubernetes Engine | 有 | Y | Y | 有 |
| App Engine 彈性環境 | 有 | Y | Y | 有 |
| App Engine 標準環境 | 有 | Y | Y | 是 |
| Dataproc | 是 | |||
| Dataflow | 是 | 是 | ||
| Google Cloud外部 | 是 | Y | Y | 有 |
下表大致列出支援的作業系統:
| 作業系統 | Go | Java | Node.js | Python |
|---|---|---|---|---|
Linux glibc 標準 C 程式庫的實作 |
是 | Y | Y | 是 |
Linuxmusl 標準 C 程式庫的實作 |
是 | Y (Alpha) | 是 | Y (Alpha) |
效能影響
Cloud Profiler 通常會以 10 秒期間內收集的資料來建立一組剖析資料;收集頻率為在單一 Compute Engine 區域中,針對已設定服務的單一執行個體每分鐘一次。舉例來說,如果您的 GKE 服務正在執行一個 Pod 的 10 組備用資源,則在 10 分鐘期間內系統會建立大概 10 組剖析資料,且每個 Pod 大約都會剖析一次。剖析期間為隨機進行,因此會有變異。詳情請參閱「剖析資料收集」。
在資料收集期間,CPU 和堆積分配剖析負擔只佔不到 5%。如果再於執行時間內平均分攤到服務的多個備用資源,則負擔通常就可以減少到低於 0.5%,因此就算在實際運作系統中持續剖析,也不會耗費太多成本。
元件
Cloud Profiler 由剖析代理程式和 Google Cloud上的主控台介面構成,前者會收集資料,而後者則可讓您查看和分析代理程式收集的資料。
剖析代理程式
您要將代理程式安裝在執行應用程式的虛擬機器上。代理程式通常會是程式庫的形式,讓您在執行應用程式時附加到應用程式中。代理程式會在應用程式執行時收集剖析資料。
如要瞭解如何執行 Cloud Profiler 代理程式,請參閱:Profiler 介面
代理程式收集到一些剖析資料後,您可以使用 Profiler 介面來查看 CPU 和記憶體使用量統計資料與應用程式區域的關聯性。
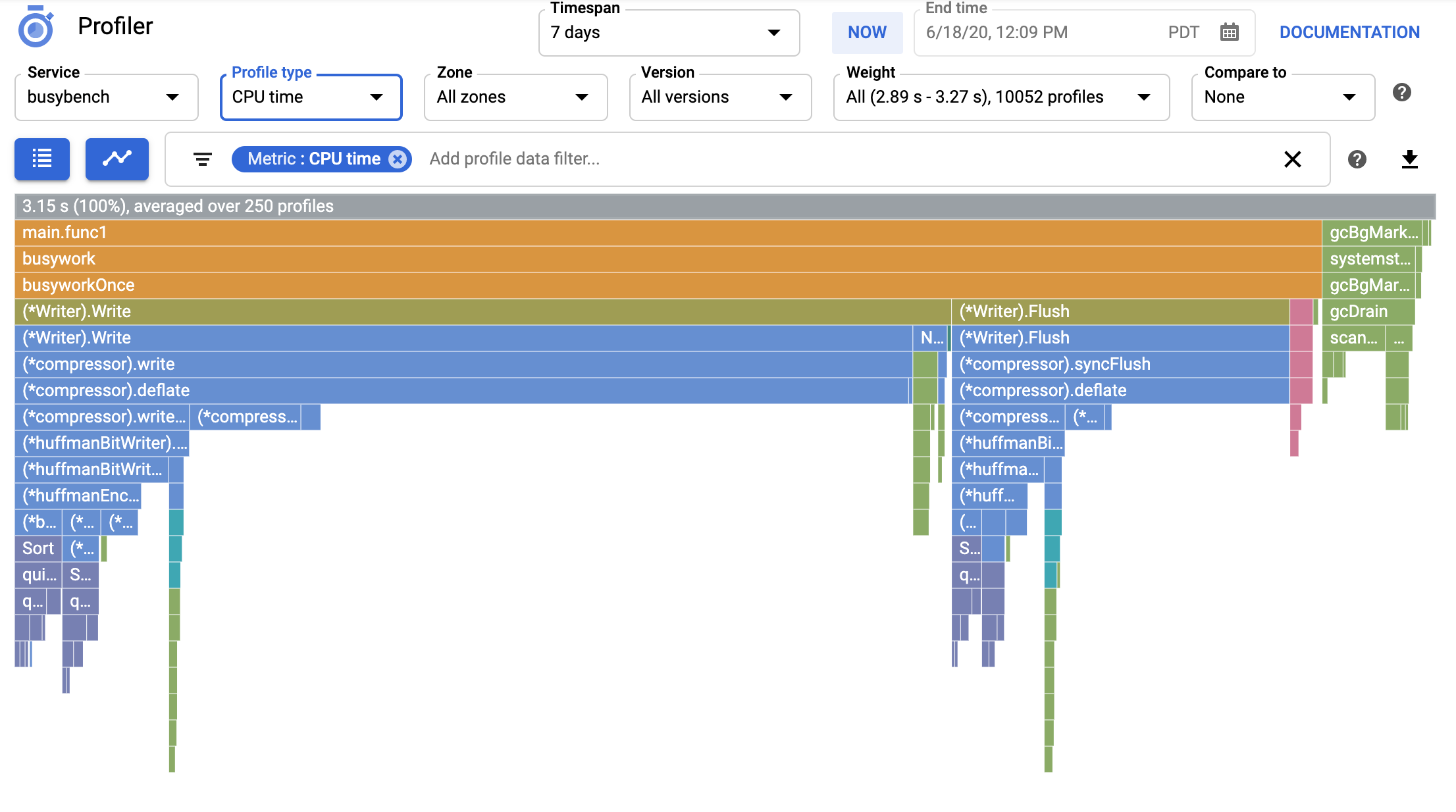
剖析資料會保留 30 天,因此您最多可分析最近 30 天內的效能資料。或者,您也可視需要下載保存這些剖析資料。
配額與限制
如要瞭解如何查看和管理 Profiler 配額,請參閱「配額與限制」一文。
資料安全性
Cloud Profiler 是 VPC Service Controls 支援的服務。詳情請參閱 VPC Service Controls 說明文件。