This page describes how you can use Oracle Autonomous Data Guard to set up cross-region disaster recovery for your Autonomous Databases in Google Cloud.
Overview
Cross-region Autonomous Data Guard on Oracle Database@Google Cloud offers a powerful and streamlined disaster recovery solution for Autonomous Database.
Protection is achieved by automatically replicating changes to a standby Autonomous Database in a separate Oracle Database@Google Cloud region. This feature enhances business continuity by protecting against regional outages and minimizing data loss. Deploying Autonomous Database Serverless with Autonomous Data Guard technology automates the complex processes involved in disaster recovery, including setup, management, and monitoring Oracle Data Guard. Autonomous Data Guard is managed by Oracle, providing the highest levels of data protection combined with decades of database management experience.
A core benefit of this solution is its ability to minimize Recovery Point Objective (RPO) and Recovery Time Objective (RTO). This is achieved through real-time redo log replication to the standby database, ensuring near-instantaneous data replication. In the event of a primary database failure, automated failover capabilities facilitate a rapid transition to the standby database, minimizing downtime. Furthermore, planned switchovers are supported for maintenance activities, allowing for seamless transitions between primary and standby roles. Data consistency is paramount, and this service ensures that the standby database remains a synchronized, up-to-date copy of the primary database through continuous redo application.
The architecture of cross-region Autonomous Data Guard is designed for simplicity and reliability. You can enable this feature and specify the chosen secondary region for the standby database after provisioning an Autonomous Database on Oracle Database@Google Cloud. Then, Google Cloud and Oracle automatically provision the standby database and configure the necessary data replication settings. Operational management is simplified through Google Cloud's monitoring tools, which let you track the health and status of the Autonomous Data Guard configuration, including peer lag.
Switchovers, which are planned transitions between primary and standby roles, can be initiated through the Google Cloud console or API. Failovers are performed when a disaster leaves the primary database unavailable. Following a failover, the failed primary database can be automatically reinstated as a standby database once it is brought back online.
When implementing cross-region Autonomous Data Guard, several considerations are important, such as the following:
- Selecting a geographically distant secondary region to minimize the risk of correlated failures.
- Network latency between regions can impact peer database lag, so careful planning is necessary.
- Regular testing of failover and switchover procedures of both the application and database tiers is crucial to ensure proper functionality.
Prerequisites
Typically known as standby databases in an on-premises deployment, Autonomous Data Guard peer databases are added after a primary database has been provisioned. Following are the prerequisites to create a peer databases with Autonomous Data Guard:
- A primary Autonomous Database instance.
- A Google Cloud VPC network with global routing configured.
- An active subscription to the region where the peer database is to be provisioned.
Primary and peer databases must use private endpoints for database connectivity. You can assign custom hostnames and IP addresses for the private endpoints during peer database creation. If you don't choose to assign a custom hostname or IP address, then these values are automatically generated.
The display name of the peer database is automatically generated during creation. You can configure a custom database ID when using the Google Cloud CLI command to create a peer database.
Example deployment
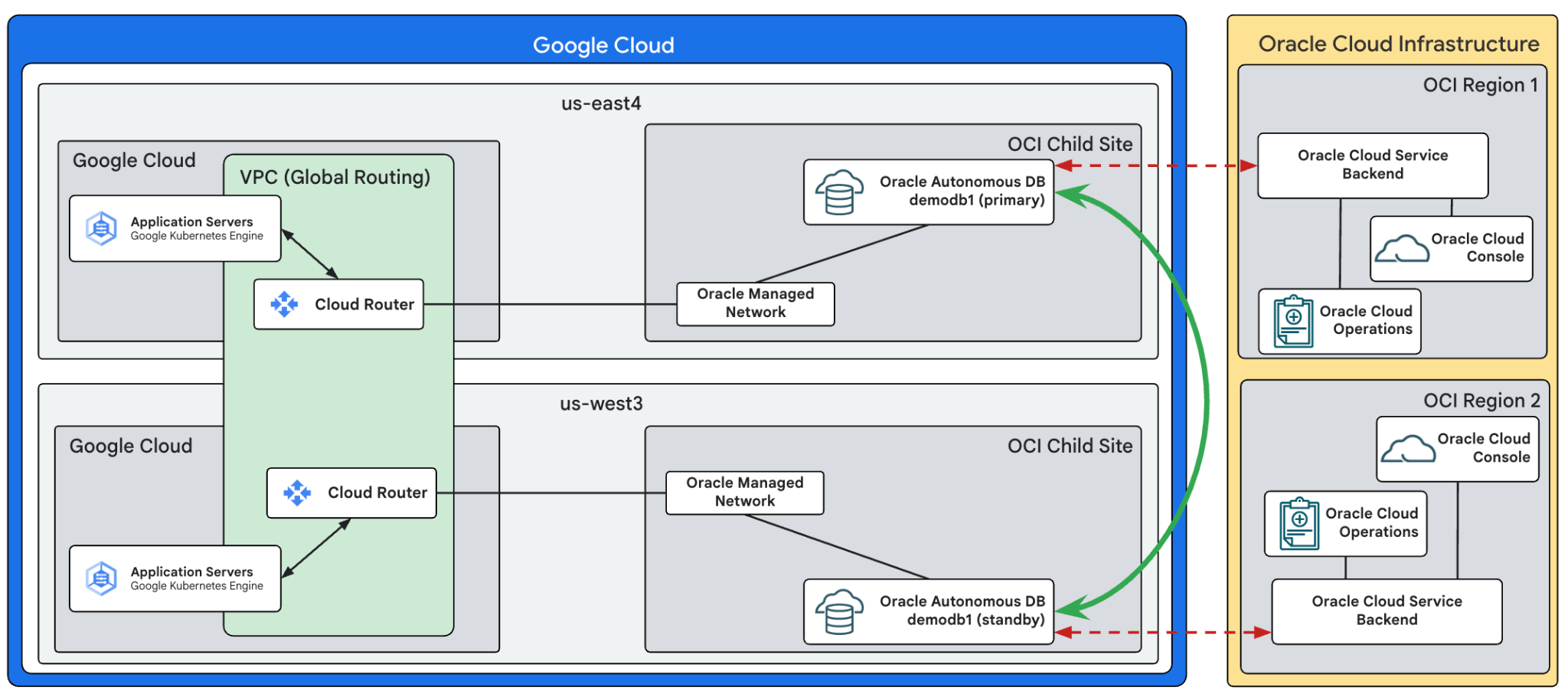
The following diagram shows an application running in Google Cloud's
us-east4 and us-west3 regions. The application servers run on Google Kubernetes Engine
and communicate with an Autonomous Database, named demodb1.
Autonomous Data Guard, depicted by the green line, has been configured with a
peer database running in the us-west3 region.
Considerations
Consider the following points while setting up peer databases with Autonomous Data Guard:
- Primary and peer databases must be accessible from the same VPC network.
- Peer databases in a separate region must use a CIDR range that doesn't overlap with the CIDR range of the subnets in the associated VPC network or the subnets used by the primary database.
- The standby database is created with the same resource configuration (workload type, ECPU count, and provisioned storage footprint) as the primary database.
- Cross-region failover requires manual intervention - this is due to the complex nature regional failover activities at the application layer.
- Oracle Active Data Guard is not supported - the peer database can't be accessed by database clients.
- Autonomous Data Guard is available with the Data Warehouse and Transaction Processing workload types. Autonomous Data Guard is not available with the JSON and APEX workload types.
Set up peer databases
To learn how to create and manage peer databases, and perform switchover in Google Cloud, refer the following:
Configuring database clients when Autonomous Data Guard is enabled
Single-region applications versus multi-region applications
Deciding when to run multi-region Oracle database applications hinges on a careful evaluation of your business requirements. Primarily, the need for robust disaster recovery and high availability often dictates a multi-region strategy. If your business can't tolerate significant downtime or data loss, especially in the face of a regional outage, a multi-region deployment becomes essential. This decision should be driven by clearly defined Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs).
From a technical perspective, the application's architecture must be designed to support multi-region deployments. This involves careful consideration of data partitioning, load balancing, and failover mechanisms. Network latency between regions is a critical factor, and optimizing network connectivity is crucial to minimize performance impacts. In many cases, the database shouldn't failover between regions without a corresponding application failover. Because of this, cross-region failover operations with Autonomous Data Guard must be performed manually. Thoroughly test failover and failback procedures to ensure the robustness and predictability of the system during failure scenarios.
Database and application administrators have the option to configure database clients to connect to an in-region copy of the database or for connectivity to span regions.
Configure single-region database connectivity
Single-region connectivity can be configured using the same methods as you would
use for a database not protected by Autonomous Data Guard. In the
Example deployment, applications in us-east4 connect to
the database in the corresponding region. When a failover occurs, the applications
failover to the secondary region us-west3.
You can retrieve your connection strings through the Google Cloud console or through the gcloud CLI command:
gcloud oracle-database autonomous-databases describe demodb1 \
--location=us-east4 \
--format="json(properties.connectionStrings.profiles)" | \
jq -r '.properties.connectionStrings.profiles[] | select(.tlsAuthentication=="SERVER")'
{
"consumerGroup": "HIGH",
"displayName": "demodb1_high",
"hostFormat": "FQDN",
"protocol": "TCPS",
"sessionMode": "DIRECT",
"syntaxFormat": "LONG",
"tlsAuthentication": "SERVER",
"value": "(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1521)(host=demodb1.adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=g24da7e94756f60_demodb1_high.adb.oraclecloud.com))(security=(ssl_server_dn_match=no)))"
}
{
"consumerGroup": "LOW",
"displayName": "demodb1_low",
"hostFormat": "FQDN",
"protocol": "TCPS",
"sessionMode": "DIRECT",
"syntaxFormat": "LONG",
"tlsAuthentication": "SERVER",
"value": "(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1521)(host=demodb1.adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=g24da7e94756f60_demodb1_low.adb.oraclecloud.com))(security=(ssl_server_dn_match=no)))"
}
{
"consumerGroup": "MEDIUM",
"displayName": "demodb1_medium",
"hostFormat": "FQDN",
"protocol": "TCPS",
"sessionMode": "DIRECT",
"syntaxFormat": "LONG",
"tlsAuthentication": "SERVER",
"value": "(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1521)(host=demodb1.adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=g24da7e94756f60_demodb1_medium.adb.oraclecloud.com))(security=(ssl_server_dn_match=no)))"
}
Configuring multi-region database connectivity
Different database hostnames and connection strings are used for each database in a cross-region configuration. When using mTLS for connectivity, you must combine the database wallets into a single zip file.
You must manually configure the wallet file if you want to allow applications to connect across regions through a single connection string.
To manually construct a wallet that contains both the primary and the remote database connections strings, do the following:
- Download the wallets for both the primary and standby databases from the Google Cloud console.
- Extract both wallet files and open the two
tnsnames.orafiles. - Copy the remote database's connect descriptor into the primary database's
connection string in the primary's
tnsnames.orafile using your preferred retry delays. - Zip the updated primary database wallet folder.
With this updated tnsnames.ora file, your primary database connection strings
in the updated wallet.zip contain both the primary and the standby hostnames,
to support failover.
An application using the updated wallet attempts to connect and retries connecting to the first listed database hostname, and if that connection fails due to the database being unavailable, the application then automatically attempts to connect to the second database hostname.
For example, if your Autonomous Data Guard is setup with the primary in Ashburn and a cross-region standby in Salt Lake City, Oracle recommends that your mid-tier applications running in Ashburn use the connection string or wallet from that of the primary database in Ashburn, and your corresponding applications running in Phoenix use the connection string or wallet from that of the standby database in Phoenix. For a regional failover or switchover, Oracle recommends failing over both your database and your application or mid-tier, for optimum performance and to minimize any cross-regional latency.
For example, combining the connection details for the demodb1 primary and standby
databases would result in the following connection string for the high
predefined service:
demodb1_high_adg =
(description_list=
(failover=on)
(load_balance=off)
(description=
(retry_count=15)
(retry_delay=3)
(address=
(protocol=tcps)
(port=1521)
(host=demodb1.adb.us-saltlake-2.oraclecloud.com)
)
(connect_data=
(service_name=g24da7e94756f60_demodb1_high.adb.oraclecloud.com)
)
(security=
(ssl_server_dn_match=no)
)
)
(description=
(retry_count=15)
(retry_delay=3)
(address=
(protocol=tcps)
(port=1521)
(host=demodb1.adb.us-ashburn-1.oraclecloud.com)
)
(connect_data=
(service_name=g24da7e94756f60_demodb1_high.adb.oraclecloud.com)
)
(security=
(ssl_server_dn_match=no)
)
)
)
Initiation of applications connections with a multi-region connection string may take slightly longer to complete. Applications select private endpoint hostnames serially from the entries in the connection string in the order they are listed. This does not affect session performance once the connection has been established.
What's next
- Create a peer database.
- View peer database details.
- Perform a switchover to a a peer database.