このページでは、Memorystore for Valkey のアーキテクチャで高可用性(HA)がサポートされ、提供される仕組みについて説明します。このページでは、インスタンスのパフォーマンスと安定性の向上に役立つ推奨構成についても説明します。
高可用性
Memorystore for Valkey は、クライアントがマネージド Memorystore for Valkey ノードに直接アクセスする高可用性アーキテクチャ上に構築されています。クライアントは、Memorystore for Valkey インスタンスに接続するで説明されているように、個々のエンドポイントに接続することでこれを行います。
シャードに直接接続すると、次のメリットがあります。
直接接続では中間ホップが回避されるため、クライアントと Valkey ノード間のラウンドトリップ時間(クライアント レイテンシ)が最小限に抑えられます。
クラスタモードが有効になっている場合、各シャードは独立して障害が発生するように設計されているため、直接接続により単一障害点が回避されます。たとえば、複数のクライアントからのトラフィックによってスロット(キースペース チャンク)が過負荷状態になった場合、シャード障害によって、スロットの処理を担当するシャードへの影響が制限されます。
推奨構成
信頼性が高いため、単一ゾーン インスタンスではなく、高可用性のマルチゾーン インスタンスを作成することをおすすめします。ただし、レプリカなしでインスタンスをプロビジョニングする場合は、単一ゾーン インスタンスを選択することをおすすめします。詳細については、インスタンスでレプリカを使用しない場合はシングルゾーン インスタンスを選択するをご覧ください。
インスタンスの高可用性を有効にするには、シャードごとに 1 つ以上のレプリカノードをプロビジョニングする必要があります。これは、インスタンスの作成時に行うか、シャードあたり少なくとも 1 つのレプリカになるようにレプリカ数をスケーリングすることで行うことができます。レプリカは、計画的なメンテナンスや予期しないシャード障害が発生した場合に、自動フェイルオーバーを提供します。
クライアントのベスト プラクティスのガイダンスに従って、クライアントを構成する必要があります。推奨されるベスト プラクティスを使用することで、クライアントはダウンタイムなしでインスタンスの次の項目を自動的に処理できます。
ロール(自動フェイルオーバー)
エンドポイント(ノードの置換)
クラスタモード有効化に関連するスロット割り当ての変更(コンシューマーのスケールアウトとスケールイン)
レプリカ
高可用性の Memorystore for Valkey インスタンスはリージョン リソースです。つまり、Memorystore for Valkey は、シャードのプライマリ ノードとレプリカノードを複数のゾーンに分散して、ゾーンの停止から保護します。Memorystore for Valkey では、ノードあたり 0、1、または 2 個のレプリカを持つインスタンスがサポートされています。
レプリカを使用すると、データが古くなる可能性はありますが、読み取りスループットを向上させることができます。
- クラスタモードが有効:
READONLYコマンドを使用して、クライアントがレプリカから読み取ることができる接続を確立します。 - クラスタモードが無効: リーダー エンドポイントに接続して、使用可能なレプリカのいずれかに接続します。
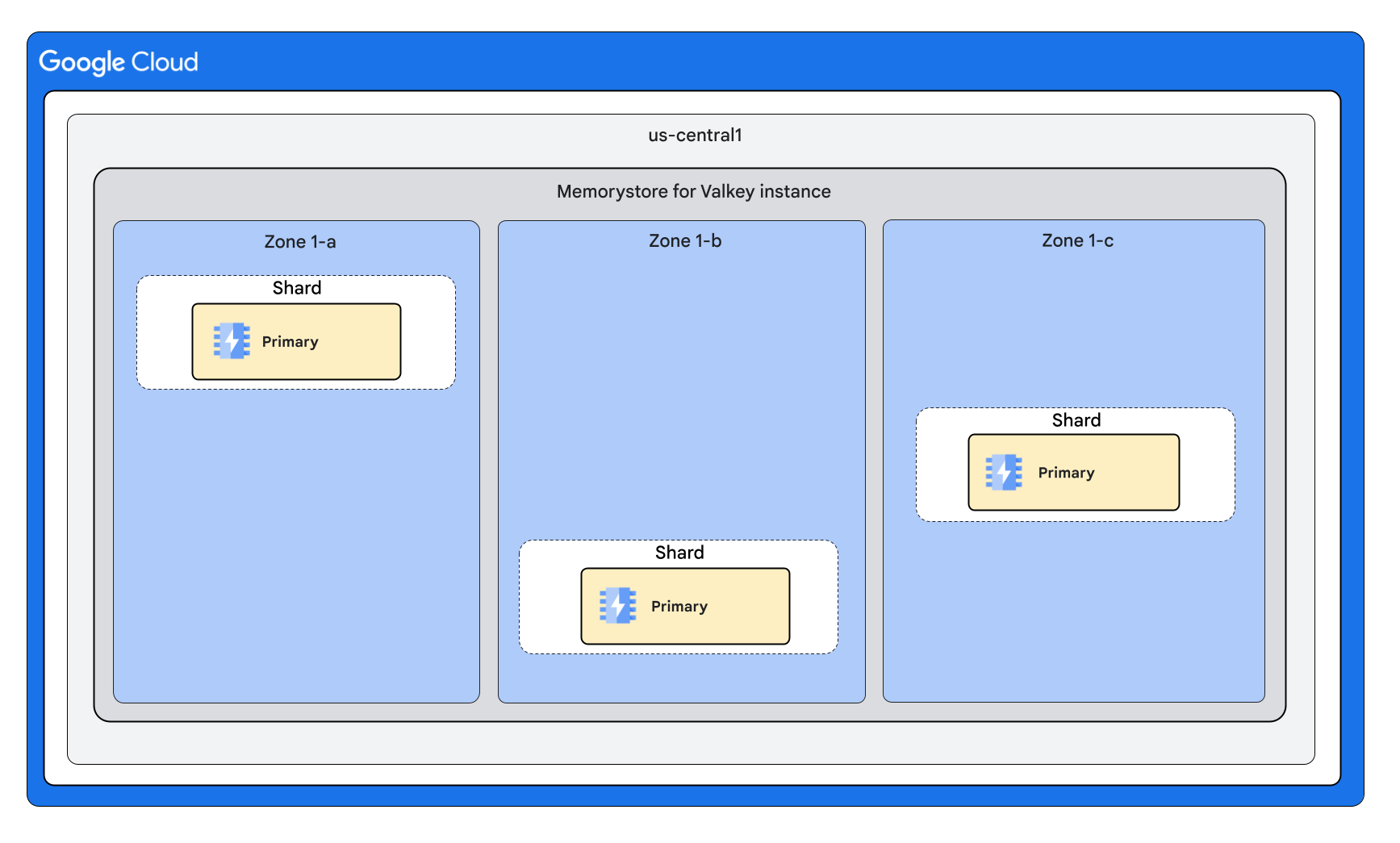
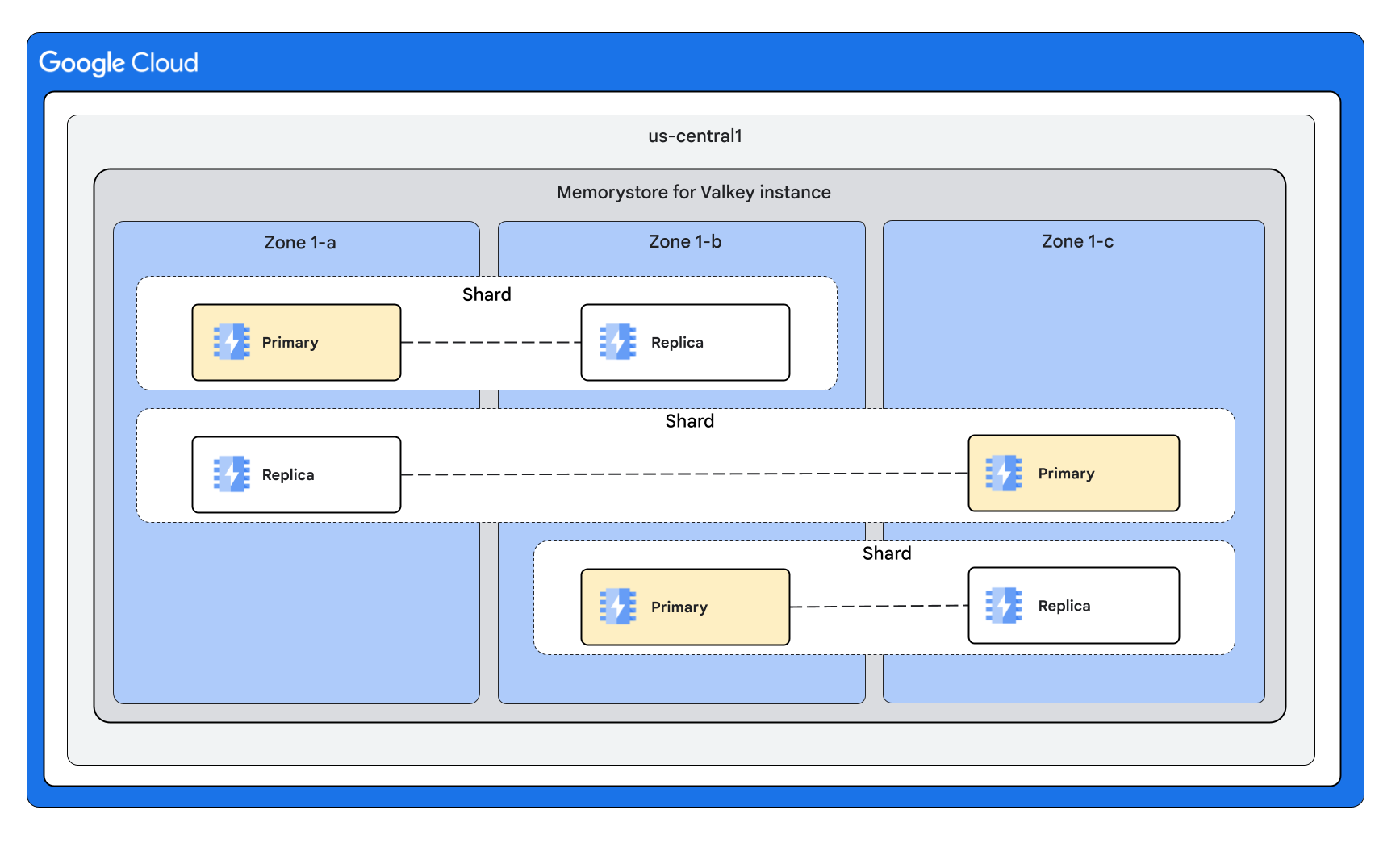
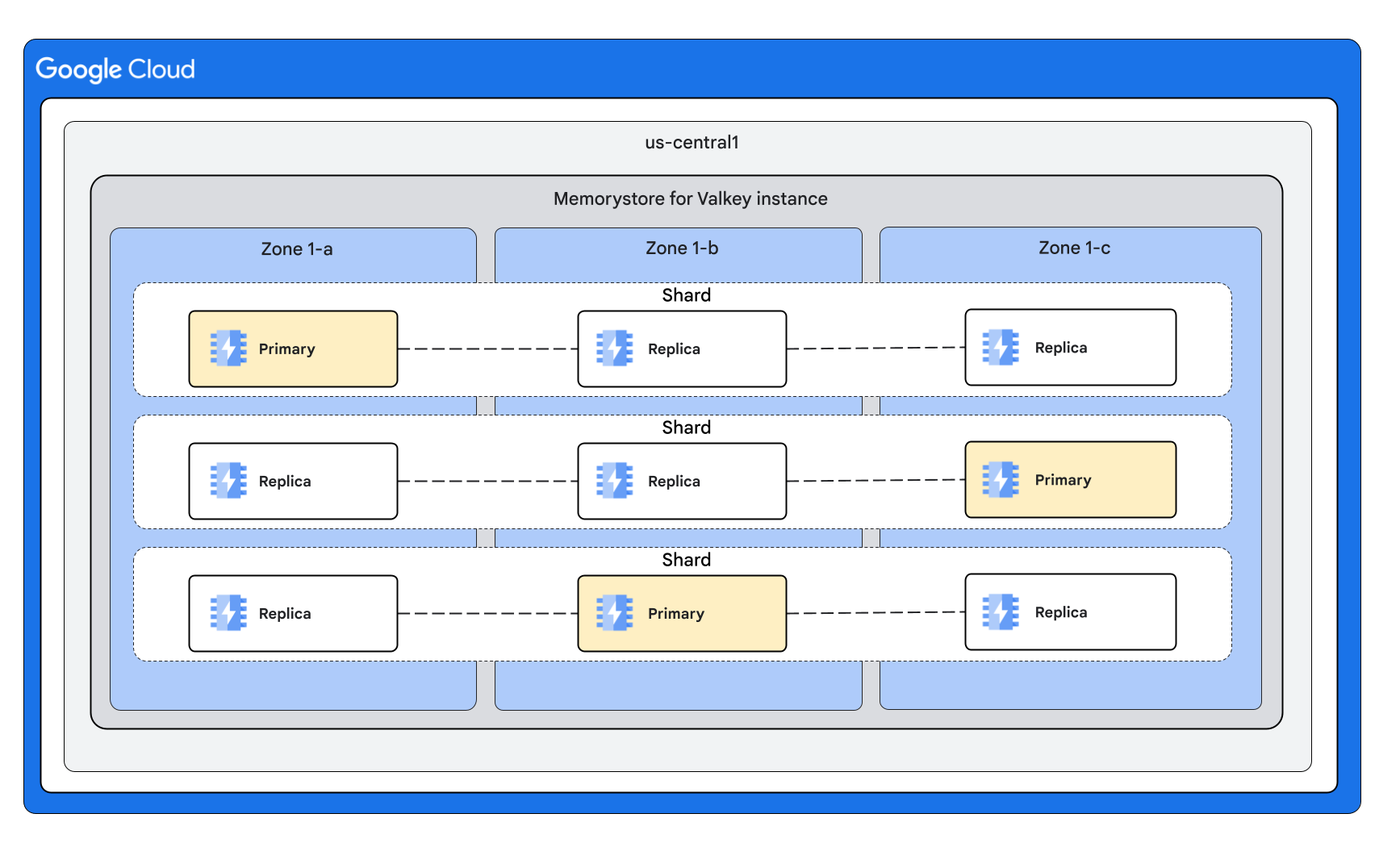
クラスタモードが有効なインスタンス シェイプ
次の図は、クラスタモードが有効になっているインスタンスのシェイプを示しています。
3 つのシャードとノードあたり 0 個のレプリカ
3 つのシャードとノードごとに 1 つのレプリカ
3 つのシャードとノードごとに 2 つのレプリカを使用
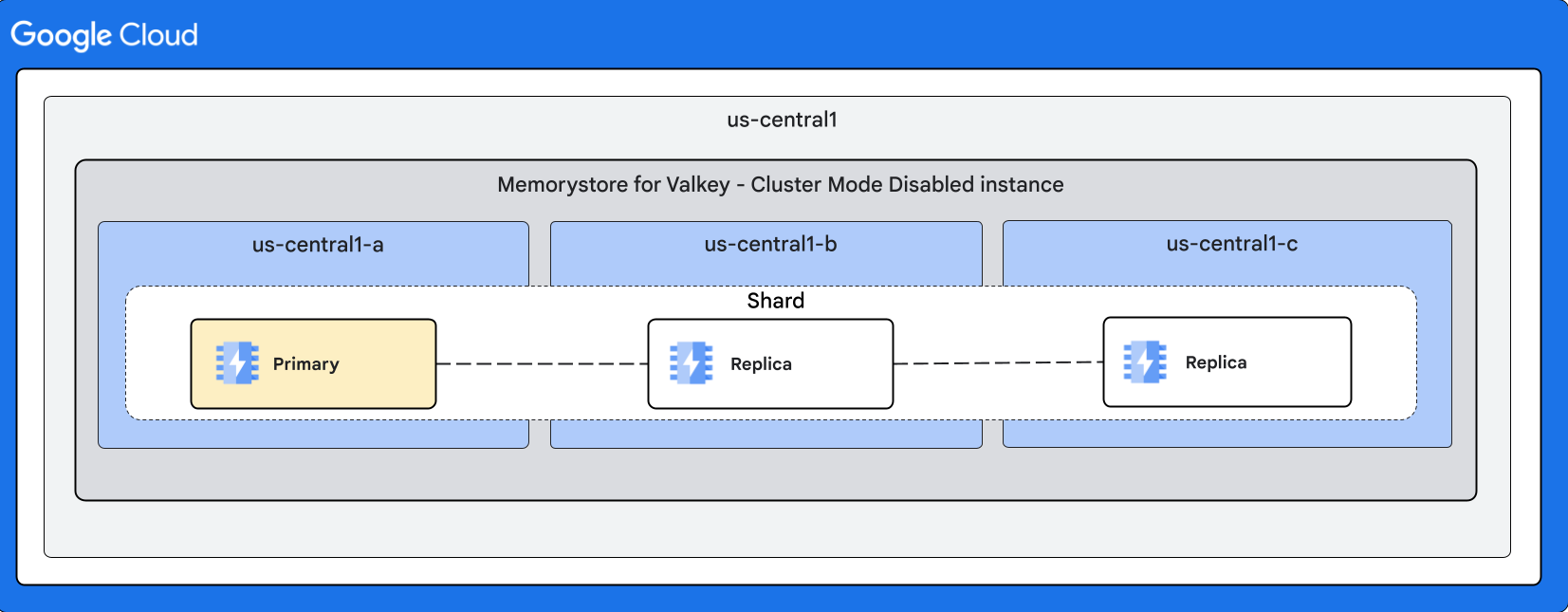
クラスタモードが無効になっているインスタンスのシェイプ
次の図は、クラスタモードが無効なインスタンスのシェイプを示しています。
2 つのレプリカを使用
自動フェイルオーバー
シャード内の自動フェイルオーバーは、メンテナンスまたはプライマリ ノードの予期しない障害が原因で発生する可能性があります。フェイルオーバー中に、レプリカがプライマリに昇格します。レプリカは明示的に構成できます。また、サービスは内部メンテナンス中に一時的に追加のレプリカをプロビジョニングして、ダウンタイムを回避することもできます。
自動フェイルオーバーにより、メンテナンス アップデート中のデータ損失を防ぐことができます。メンテナンス中の自動フェイルオーバーの動作の詳細については、メンテナンス中の自動フェイルオーバーの動作をご覧ください。
フェイルオーバーとノード修復の期間
自動フェイルオーバーには、プライマリ ノード プロセスのクラッシュやハードウェア障害などの計画外のイベントの場合、数十秒程度の時間がかかることがあります。この間、システムは障害を検出し、新しいプライマリとしてレプリカを選択します。
ノードの修復には、サービスが障害が発生したノードを置き換えるまでに数分程度の時間がかかることがあります。これは、すべてのプライマリ ノードとレプリカ ノードに当てはまります。高可用性インスタンス(レプリカがプロビジョニングされていない)の場合、障害が発生したプライマリ ノードの修復にも数分程度の時間がかかります。
計画外フェイルオーバー中のクライアントの動作
障害の性質によっては、クライアント接続がリセットされる可能性があります。自動復旧後、プライマリ ノードとレプリカ ノードの過負荷を避けるため、指数バックオフを使用して接続を再試行する必要があります。
読み取りスループットにレプリカを使用しているクライアントは、障害が発生したノードが自動的に置き換えられるまで、容量が一時的に低下することに備える必要があります。
書き込みの損失
予期しない障害によるフェイルオーバー中に、Valkey のレプリケーション プロトコルの非同期性により、確認済みの書き込みが失われることがあります。
クライアント アプリケーションは、Valkey WAIT コマンドを活用して、実際のデータの安全性を向上させることができます。
単一ゾーンの停止によるキースペースへの影響
このセクションでは、単一ゾーンの停止が Memorystore for Valkey インスタンスに与える影響について説明します。
マルチゾーン インスタンス
HA インスタンス: ゾーンで停止が発生した場合、キースペース全体で読み取りと書き込みが可能ですが、一部のリードレプリカが使用できないため、読み取り容量が減少します。1 つのゾーンで障害が発生した場合に、インスタンスに十分な読み取り容量を確保できるように、クラスタ容量をオーバー プロビジョニングすることを強くおすすめします。停止が終了すると、影響を受けたゾーンのレプリカが復元され、クラスタの読み取り容量が構成された値に戻ります。詳細については、スケーラブルで信頼性の高いアプリのパターンをご覧ください。
非 HA インスタンス(レプリカなし): ゾーンで停止が発生すると、影響を受けるゾーンでプロビジョニングされたキースペースの部分でデータ フラッシュが発生し、停止中は書き込みまたは読み取りに使用できなくなります。停止が終了すると、影響を受けたゾーンのプライマリが復元され、クラスタの容量が構成された値に戻ります。
シングルゾーン インスタンス
- HA インスタンスと非 HA インスタンスの両方: インスタンスがプロビジョニングされているゾーンで停止が発生した場合、クラスタは使用できなくなり、データはフラッシュされます。別のゾーンで停止が発生した場合、クラスタは読み取りリクエストと書き込みリクエストの処理を継続します。
ベスト プラクティス
このセクションでは、高可用性とレプリカに関するベスト プラクティスについて説明します。
レプリカを追加する
レプリカを追加するには、RDB スナップショットが必要です。RDB スナップショットは、プロセス フォークと「コピーオンライト」メカニズムを使用して、ノードデータのスナップショットを作成します。ノードへの書き込みパターンに応じて、書き込みによってアクセスされたページがコピーされると、ノードの使用済みメモリが増加します。メモリ フットプリントは、ノード内のデータの最大 2 倍になることがあります。
ノードにスナップショットを完了するのに十分なメモリがあることを確認するには、maxmemory をノード容量の 80% に維持または設定して、20% をオーバーヘッド用に予約します。スナップショットのモニタリングに加え、このメモリ オーバーヘッドにより、ワークロードのスナップショットを正常に処理できます。また、レプリカを追加するときは、書き込みトラフィックをできるだけ減らしてください。詳細については、インスタンスのメモリ使用量をモニタリングするをご覧ください。