Mainframe Connector transcodifica archivos planos del método de acceso secuencial en cola (QSAM) a formatos compatibles con Google Cloud y viceversa con los comandos qsam. Los comandos qsam realizan las siguientes operaciones de transcodificación:
- El comando
qsam decodedecodifica los datos de la unidad central en Google Cloud - El comando
qsam encodecodifica los datos de Google Cloud en la unidad central.
Estas operaciones realizan transformaciones simétricas, es decir, mueven los mismos datos hacia y desde Google Cloud. Puedes definir la estructura de un archivo QSAM en un archivo de copybook con la definición de la estructura de datos de COBOL. También puedes definir transformaciones avanzadas con el archivo de configuración del transcodificador de Mainframe Connector. En los siguientes diagramas, se describen estas operaciones en detalle.
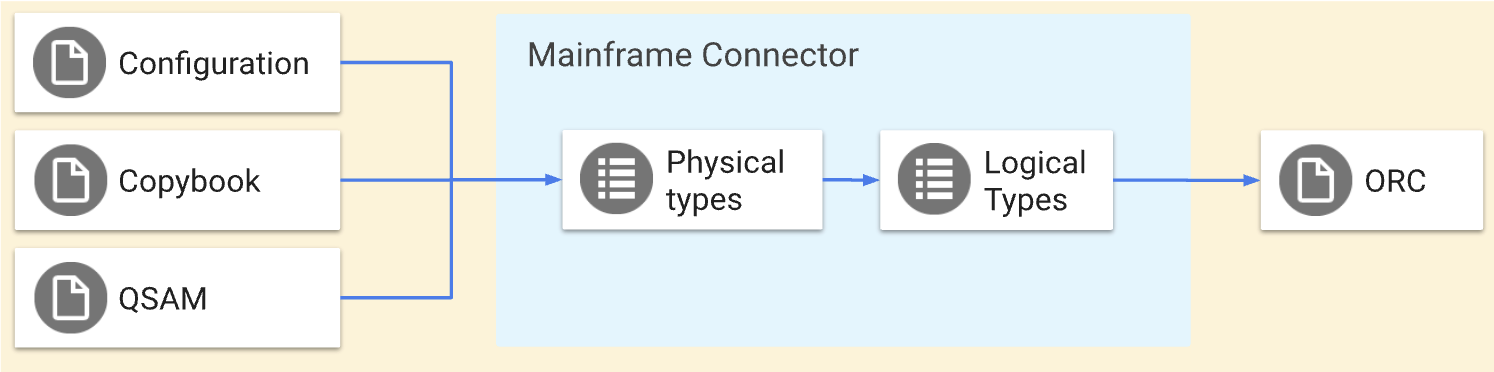
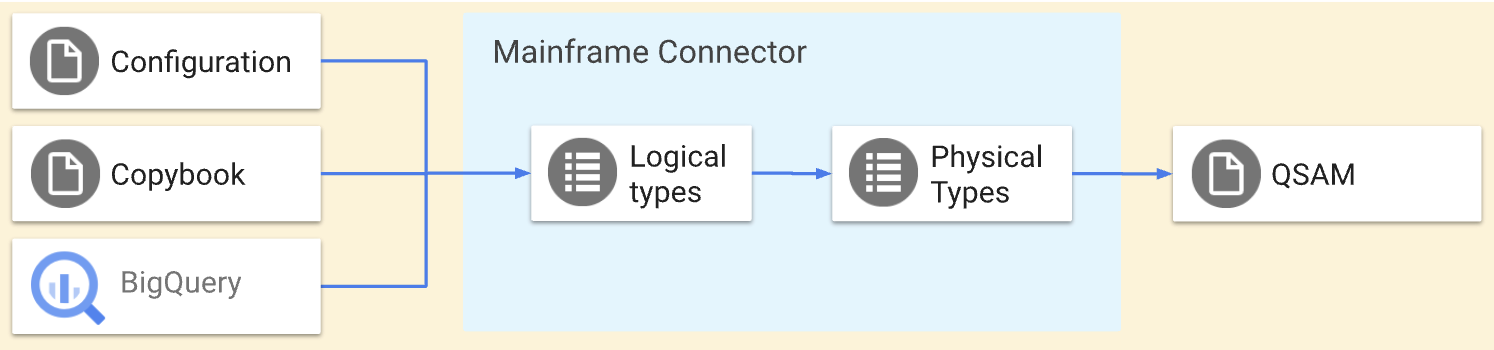
En esta página, se proporciona una descripción general del proceso de transcodificación con los comandos qsam decode y qsam encode, los tipos físicos y lógicos de los datos de la unidad central, y las asignaciones de tipos de Optimized Row Columnar (ORC) y BigQuery.
Tipos físicos
Los tipos físicos definen cómo se disponen los datos de los campos en un disco. Los tipos físicos se convierten en tipos lógicos del conector de unidades centrales, que luego se pueden asignar a tipos de bases de datos (ORC o BigQuery).
Campos alfanuméricos
Los campos alfanuméricos se usan para procesar cadenas alfanuméricas. Los datos se tratan como una serie de caracteres y se almacenan como cadenas con una codificación específica, por ejemplo, el Código de Intercambio Decimal Codificado en Binario Extendido (EBCDIC).
El proceso de transcodificación no finaliza si se producen errores durante la codificación o decodificación de los campos alfanuméricos. En su lugar, se coloca un carácter SUB para la codificación en la ubicación donde se produjo el error, y el proceso de transcodificación continúa.
| Símbolos de imágenes | Atributos de la imagen | Tipo lógico |
|---|---|---|
| A, B, G, N, U, X y 9 | DISPLAY, DISPLAY-1, NATIONAL, UTF-8 | String |
Ejemplo
01 REC 02 STR PIC X(10) 02 NATIONAL PIC N(10) 02 UTF8 PIC U(1) USAGE UTF-8
Formato de codificación
Los campos alfanuméricos se codifican de la siguiente manera:
- Los campos X tienen la codificación EBCDIC de forma predeterminada
- Los campos nacionales (N) tienen como valor predeterminado la codificación Unicode Transformation Format de 16 bits (UTF-16 BE).
- Los campos UTF8 se establecen de forma predeterminada en la codificación Unicode Transformation Format-8 (UTF-8).
Mainframe Connector admite la mayoría de las codificaciones de grupo de caracteres de un byte (SBCS) y de grupo de caracteres de doble byte (DBCS). También puedes definir tu propia codificación de SBCS personalizada, si es necesario.
Campos binarios (COMPUTATIONAL)
Los campos binarios se almacenan como números enteros big-endian con o sin signo. Mainframe Connector siempre almacena los campos binarios de forma lógica como números enteros de 64 bits con signo. Por lo tanto, las entradas de tipo unsigned long solo deben usar los 63 bits inferiores. De lo contrario, el proceso de transcodificación fallará.
| Símbolos de imágenes | Atributos de la imagen | Tipo lógico |
|---|---|---|
| S, 9 | COMP, COMPUTATIONAL | Long (número entero de 64 bits con firma) |
Ejemplo
01 REC 02 INT PIC S9(8) COMP
Campos de punto flotante hexadecimal (COMP-1, COMP-2)
Los campos de punto flotante hexadecimal (HFP) son totalmente compatibles. Mainframe Connector usa formatos de precisión simple y doble para los campos de HFP.
| Símbolos de imágenes | Atributos de la imagen | Tipo lógico |
|---|---|---|
| COMP-1, COMP-2 | Doble (número de punto flotante con signo de 64 bits) |
Ejemplo
01 REC 03 HFP-SINGLE COMP-1. 03 HFP-DOUBLE COMP-2.
Campos decimales empaquetados (COMP-3)
Los campos decimales empaquetados son totalmente compatibles. Durante el proceso de transcodificación, Mainframe Connector selecciona el tipo lógico con mejor rendimiento según la precisión y la escala especificadas.
| Símbolos de imágenes | Atributos de la imagen | Tipo lógico |
|---|---|---|
| S, 9, V | COMP-3 | Long (número entero de 64 bits con firma), BigInteger, Decimal64, BigDecimal |
Ejemplo
01 REC 02 DEC PIC S9(2)V9(8) COMP-3
Campo decimal zonificado (DISPLAY)
Los campos decimales zonificados son totalmente compatibles. Durante el proceso de transcodificación, Mainframe Connector selecciona el tipo lógico con mejor rendimiento según la precisión y la escala especificadas.
| Símbolos de imágenes | Atributos de la imagen | Tipo lógico |
|---|---|---|
| S, 9, V | DISPLAY | Long (número entero de 64 bits con firma), BigInteger, Decimal64, BigDecimal |
Ejemplo
01 REC 02 DEC PIC S9(2)V9(8) DISPLAY
Listas (OCCURS)
Las listas son colecciones ordenadas de elementos del mismo tipo. El conector de Mainframe admite los siguientes tipos de listas:
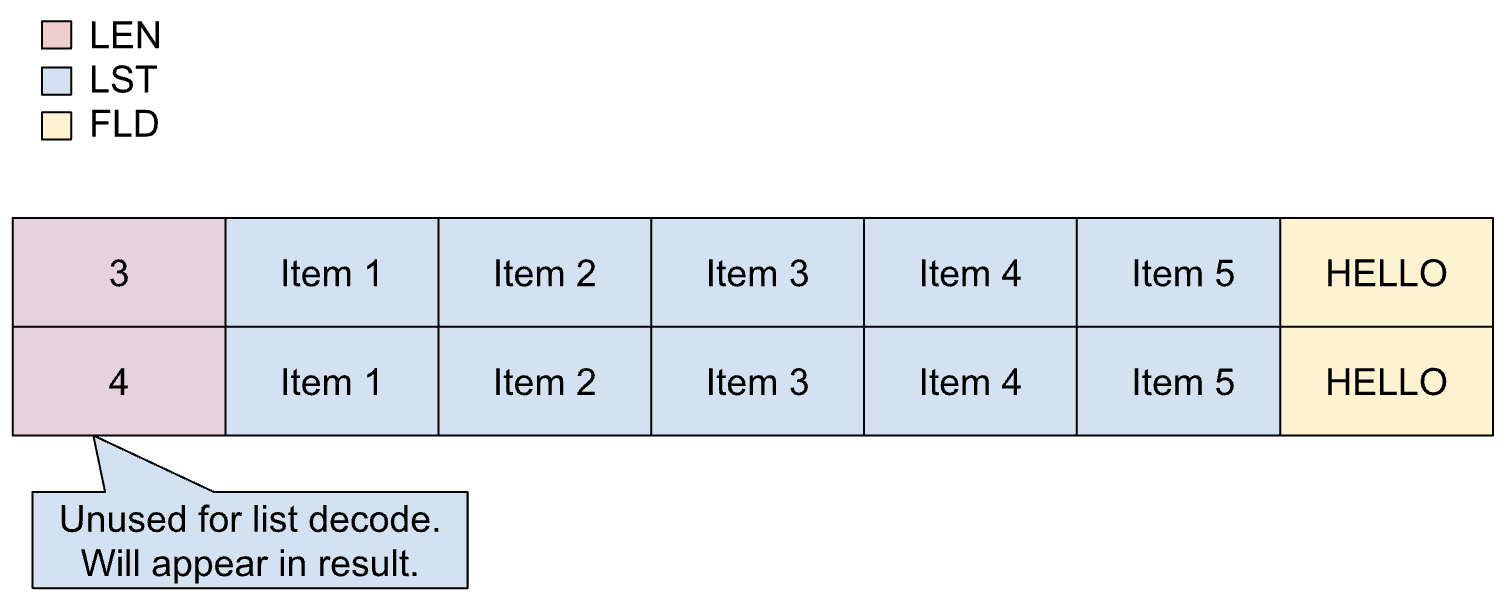
Listas fijas
Las listas fijas se usan cuando se conoce de antemano la cantidad exacta de elementos (recuento de elementos) que formarán parte de la lista, y esta cantidad siempre sigue siendo la misma. Los elementos de una lista fija pueden tener un tamaño variable.
Las listas fijas se definen de la siguiente manera en un copybook:
01 REC.
02 LIST OCCURS 5 TIMES PIC X(1).
02 FLD PIC X(5).
En la siguiente imagen, se muestra el diseño de una lista fija con un recuento de elementos de 5.
Listas dinámicas
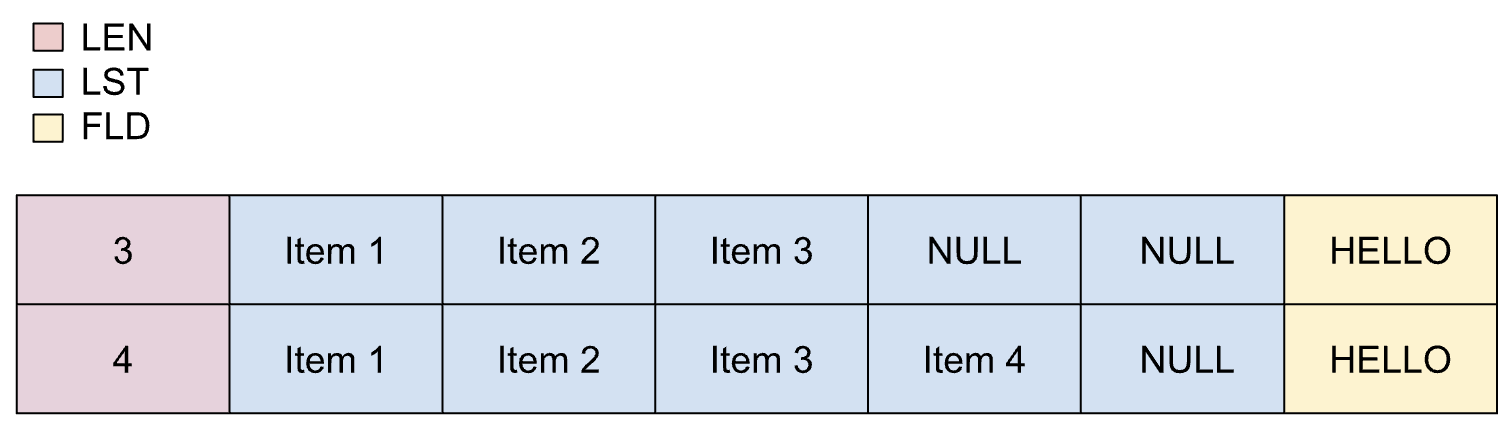
Las listas dinámicas se usan cuando se conoce de antemano la cantidad máxima de elementos que formarán parte de la lista. Sin embargo, la cantidad real de elementos es desconocida y depende de otro campo. Los elementos de una lista dinámica pueden tener un tamaño variable.
Las propiedades de las listas dinámicas son las siguientes:
- El campo de longitud se puede convertir en un número entero sin pérdida de precisión.
- El campo de longitud debe estar en el alcance.
- No se aplica el recuento mínimo de elementos durante el proceso de transcodificación.
Las listas dinámicas se definen de la siguiente manera en un copybook:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS 1 TO 5 TIMES
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
En la siguiente imagen, se muestra el diseño de una lista dinámica con una cantidad máxima de cinco elementos.
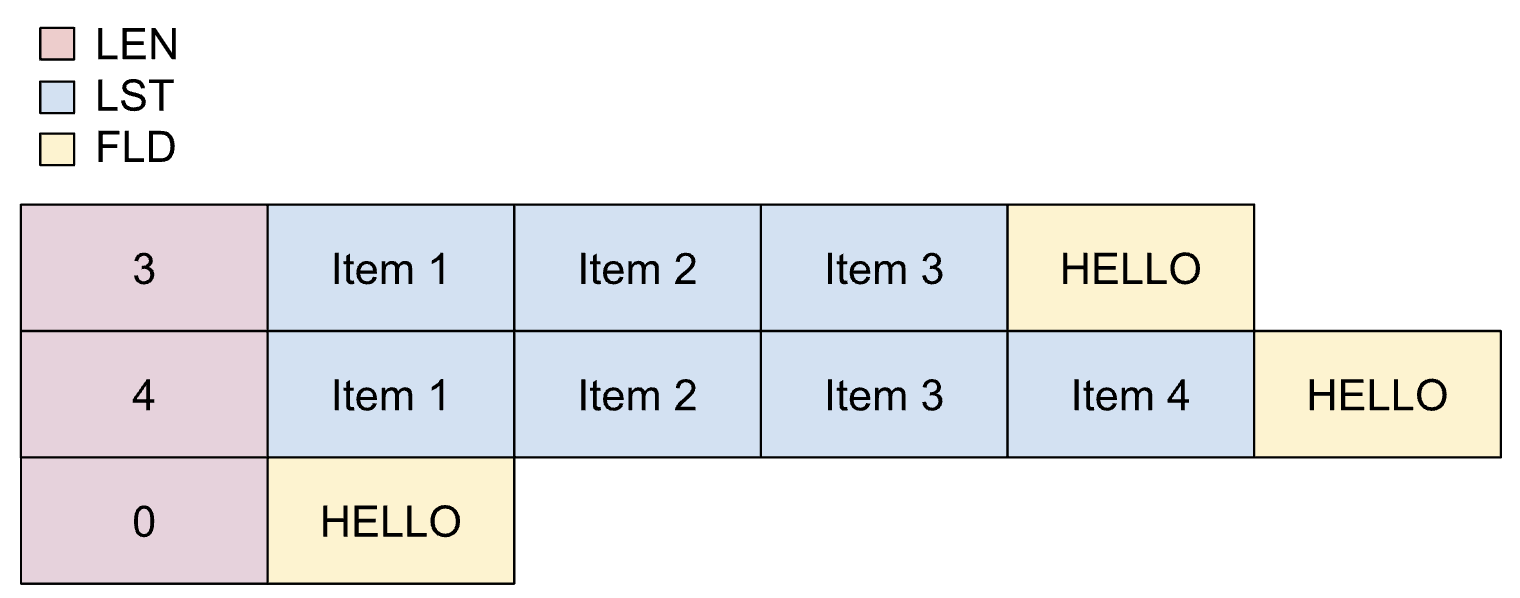
Listas dinámicas empaquetadas
Las listas dinámicas empaquetadas se usan cuando la cantidad máxima de elementos que formarán parte de la lista depende de otro campo y los elementos están empaquetados.
Las propiedades de las listas dinámicas empaquetadas son las siguientes:
- El campo de longitud se puede convertir en un número entero sin pérdida de precisión.
- El campo de longitud debe estar en el alcance.
- No se aplica el recuento mínimo de elementos durante el proceso de transcodificación.
Las listas dinámicas empaquetadas se definen de la siguiente manera en un copybook:
01 REC.
02 LEN PIC S9(2) BINARY.
02 LIST OCCURS UNBOUNDED
DEPENDING ON LEN PIC X(1).
02 FLD PIC X(5).
En la siguiente imagen, se muestra el diseño de una lista dinámica empaquetada.
Redefiniciones (REDEFINES)
Las redefiniciones son una función de COBOL que permite que los mismos datos tengan varias posibilidades de decodificación. Durante el proceso de decodificación, las redefiniciones aparecen como columnas adicionales en la tabla resultante, y los datos se decodifican varias veces.
Las propiedades de las redefiniciones son las siguientes:
- Las redefiniciones de los mismos datos subyacentes no son campos hermanos y, por lo tanto, no están dentro del alcance de cada uno.
- Los campos redefinidos se decodifican cuando se decodifica el campo subyacente, no cuando se declaran. El campo subyacente también determina el alcance de los campos redefinidos.
- Todos los campos redefinidos deben tener el mismo tamaño y un tamaño fijo. Esto significa que no puedes usar campos de texto de longitud variable ni listas dinámicas empaquetadas en campos redefinidos.
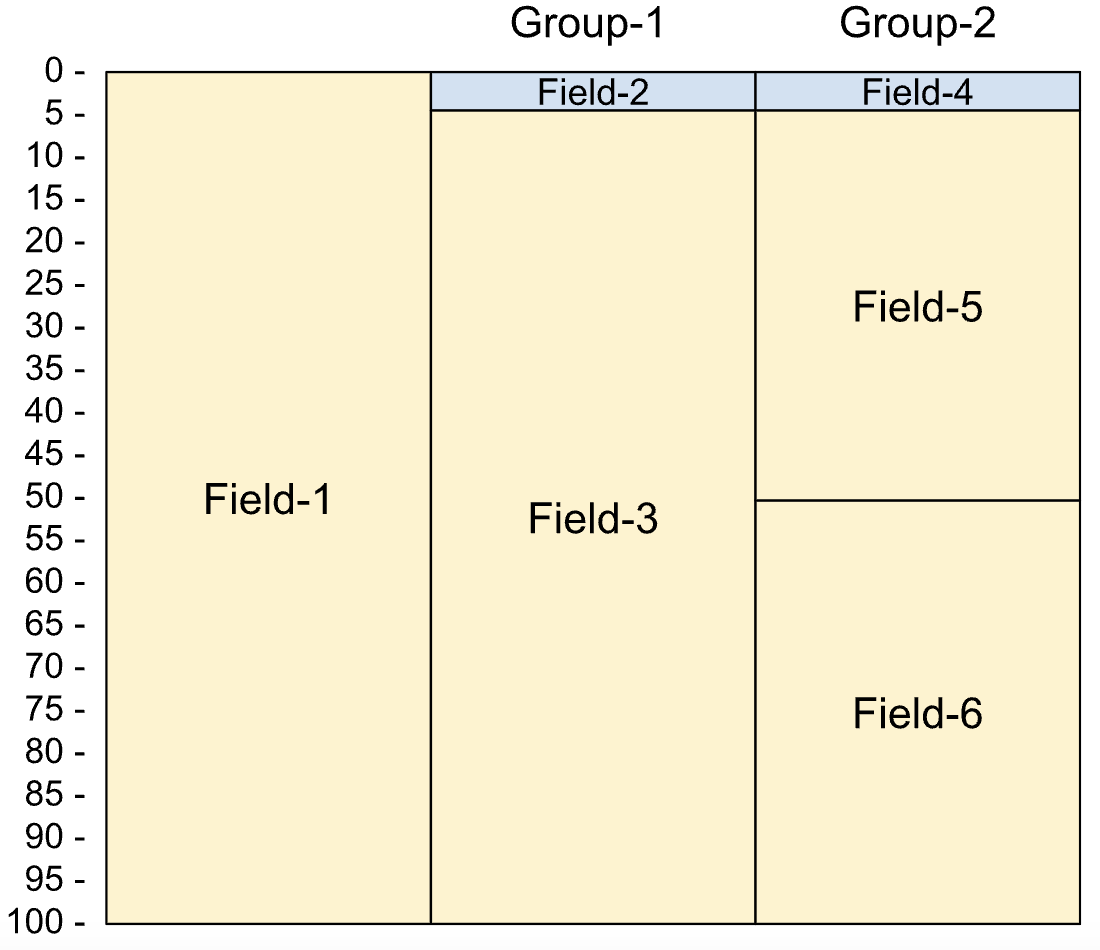
Las redefiniciones se definen de la siguiente manera en un copybook:
01 Rec.
05 Field-1 PIC X(100).
05 Group-1 REDEFINES Field-1.
10 Field-2 PIC 9(5) comp-3.
10 Field-3 PIC X(96).
05 Group-2 REDEFINES Field-1.
10 Field-4 PIC 9(4) comp-4.
10 Field-5 PIC X(50).
10 Field-6 PIC X(46).
En la siguiente imagen, se muestra el diseño de un campo redefinido.
Puedes usar las redefiniciones de muchas maneras, incluidas las siguientes más comunes:
Ver los mismos datos de dos maneras diferentes: Esta es la forma más común en que se usan las redefiniciones. Durante el proceso de codificación, el orden en el que se completan los datos no está definido, por lo que debes asegurarte de que los datos en BigQuery conserven su integridad cuando se exporten.
Ejemplo
01 REC. 02 FULL-NAME PIC X(12). 02 NAME REDEFINES FULL-NAME. 05 FIRST-NAME PIC X(6). 05 LAST-NAME PIC X(6).Usa uniones etiquetadas: Las uniones etiquetadas son una forma común de usar redefines cuando solo necesitas una de las interpretaciones de los datos de cualquier registro, según un campo. Puedes usar indicadores nulos para marcar las interpretaciones innecesarias como nulas. Esto también evitará que se analicen debido a que los indicadores nulos tienen evaluaciones diferidas. Las propiedades de las uniones etiquetadas son las siguientes:
- El proceso de codificación falla si se define más de una redefinición.
- Solo se implementan las verificaciones de igualdad y no igualdad.
Ejemplo
01 REC. 05 TYPE PIC X(5). 05 DATA PIC X(100). 05 VARIANT-1 REDEFINES DATA. 10 Field-2 PIC 9(4) comp-3. 10 Field-3 PIC X(96). 05 VARIANT-2 REDEFINES DATA. 10 Field-4 PIC 9(4) comp-5. 10 Field-5 PIC X(50). 10 Field-6 PIC X(46).Puedes usar el siguiente ejemplo para implementar una unión etiquetada:
{ "field_override": [ { "field": "VARIANT-1", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR1" } } }, { "field": "VARIANT-2", "modifier": { "null_if": { "target_field": "TYPE", "non_null_value": "VAR2" } } } ], "transformations": [ { "field": "DATA", "transformation": { "exclude": {}} } ] }
Tipos lógicos
Para transcodificar datos a varios formatos y desde ellos, Mainframe Connector convierte todos los datos a una representación intermedia (IR) basada en tipos lógicos. Los formatos de entrada y salida definen cómo se convierten los datos a cualquier tipo lógico y desde él. En la siguiente tabla, se enumeran todos los tipos lógicos que admite Mainframe Connector.
| Tipo lógico | Descripción |
|---|---|
| BigDecimal | Representa números decimales de cualquier escala y precisión. |
| BigInteger | Representa números enteros de cualquier tamaño. |
| Bytes | Representa un array de bytes de tamaños variables. |
| Fecha | Representa una fecha independiente de una zona horaria específica. |
| Decimal64 | Representa un decimal con un rango que puede ajustarse a un número entero de 64 bits con firma de cualquier escala. |
| Doble | Representa un número de punto flotante de doble precisión como se describe en el estándar IEEE para aritmética de punto flotante (IEEE 754). |
| Lista | Representa una lista de elementos de un tipo específico. La lista puede contener una cantidad arbitraria de elementos. |
| Largo | Representa un número de 64 bits con signo. |
| Registro | Representa una serie fija de campos de diferentes tipos. |
| String | Representa una cadena de caracteres Unicode no relacionada con ninguna codificación específica. Se puede representar cualquier punto de código Unicode válido. Sin embargo, es posible que algunos caracteres no se puedan codificar en todos los procesos de codificación. Las cadenas lógicas tienen una longitud variable. |
| Marca de tiempo | Representa una marca de tiempo independiente de una zona horaria específica. |
Asignación de tipos de ORC
En la siguiente tabla, se proporciona la asignación entre los tipos lógicos de Mainframe Connector y los tipos de ORC.
| Tipo lógico | Tipo de ORC |
|---|---|
| BigDecimal | decimal |
| BigInteger | decimal |
| Bytes | BLOB binario |
| Fecha | fecha |
| Decimal64 | decimal64 |
| Doble | float64 |
| Lista | list |
| Largo | Número entero de 64 bits (bigint) |
| Registro | struct |
| String | Cadena codificada en UTF-8 |
| Marca de tiempo | Marca de tiempo (sin zona horaria local) |
Asignación de tipos de BigQuery
En la siguiente tabla, se proporciona la asignación entre los tipos lógicos de Mainframe Connector y los tipos de datos de BigQuery.
| Tipo lógico | Tipo de datos de BigQuery | Comentarios |
|---|---|---|
| BigDecimal | NUMERIC | |
| BigInteger | NUMERIC | |
| Bytes | BYTES | |
| Fecha | DATE | |
| Decimal64 | NUMERIC | |
| Doble | FLOAT64 | |
| Lista | ARRAY | Las listas anidadas y de mapas no son compatibles. |
| Largo | INT64 | |
| Registro | STRUCT | Cuando una unión solo tiene una variante, se convierte en un campo NULLABLE.
De lo contrario, un union se convierte en un RECORD con una lista de campos NULLABLE.
Los campos NULLABLE tienen sufijos como field_0 y field_1. Solo se asigna un valor a uno de estos campos cuando se leen los datos. |
| String | STRING | |
| Marca de tiempo | TIMESTAMP |
Alcance del campo
Se considera que un campo está dentro del alcance de otro campo si cumple con una de las siguientes condiciones:
- Es un campo hermano que se define antes del campo que lo requiere.
- Es un campo de un registro principal que se define antes del campo que lo requiere.