Questo tutorial spiega il metodo consigliato per creare una configurazione di Looker in cluster per le istanze ospitate dal cliente.
Panoramica
I deployment di Looker ospitati dal cliente possono essere eseguiti su un singolo nodo o in cluster:
- Un'applicazione Looker a un singolo nodo, la configurazione predefinita, ha tutti i servizi che compongono l'applicazione Looker in esecuzione su un singolo server.
- Una configurazione in cluster di Looker è una configurazione più complessa, che in genere coinvolge server di database, bilanciatori del carico e più server che eseguono l'applicazione Looker. Ogni nodo in un'applicazione Looker in cluster è un server che esegue una singola istanza di Looker.
Esistono due motivi principali per cui un'organizzazione potrebbe voler eseguire Looker come cluster:
- Bilanciamento del carico
- Disponibilità e failover migliorati
A seconda dei problemi di scalabilità, un cluster Looker potrebbe non fornire la soluzione. Ad esempio, se un numero ridotto di query di grandi dimensioni sta esaurendo la memoria di sistema, l'unica soluzione è aumentare la memoria disponibile per il processo Looker.
Alternative al bilanciamento del carico
Prima di bilanciare il carico di Looker, valuta la possibilità di aumentare la memoria e, se necessario, il numero di CPU di un singolo server che esegue Looker. Looker consiglia di configurare il monitoraggio dettagliato delle prestazioni per l'utilizzo della memoria e della CPU per assicurarsi che il server Looker sia dimensionato correttamente per il suo workload.
Le query di grandi dimensioni richiedono più memoria per prestazioni migliori. Il clustering può migliorare le prestazioni quando molti utenti eseguono query di piccole dimensioni.
Per le configurazioni con un massimo di 50 utenti che utilizzano Looker in modo leggero, Looker consiglia di eseguire un singolo server equivalente a un'istanza AWS EC2 di grandi dimensioni (M4.large: 8 GB di RAM, 2 core CPU). Per le configurazioni con più utenti o molti utenti esperti attivi, controlla se la CPU raggiunge picchi o se gli utenti notano lentezza nell'applicazione. In questo caso, sposta Looker su un server più grande o esegui una configurazione di Looker in cluster.
Disponibilità/failover migliorati
L'esecuzione di Looker in un ambiente in cluster può ridurre i tempi di inattività in caso di interruzione. L'alta disponibilità è particolarmente importante se l'API Looker viene utilizzata nei sistemi aziendali principali o se Looker è incorporato in prodotti rivolti ai clienti.
In una configurazione di Looker in cluster, un server proxy o un bilanciatore del carico reindirizza il traffico quando determina che un nodo non è attivo. Looker gestisce automaticamente i nodi che escono dal cluster e quelli che vi entrano.
Componenti obbligatori
Per una configurazione di Looker in cluster sono necessari i seguenti componenti:
- Database dell'applicazione MySQL
- Nodi Looker (server che eseguono il processo Java di Looker)
- Bilanciatore del carico
- File system condiviso
- Versione corretta dei file JAR dell'applicazione Looker
Il seguente diagramma illustra l'interazione tra i componenti. A livello generale, un bilanciatore del carico distribuisce il traffico di rete tra i nodi Looker in cluster. I nodi comunicano ciascuno con un database delle applicazioni MySQL condiviso, una directory di archiviazione condivisa e i server Git per ogni progetto LookML.
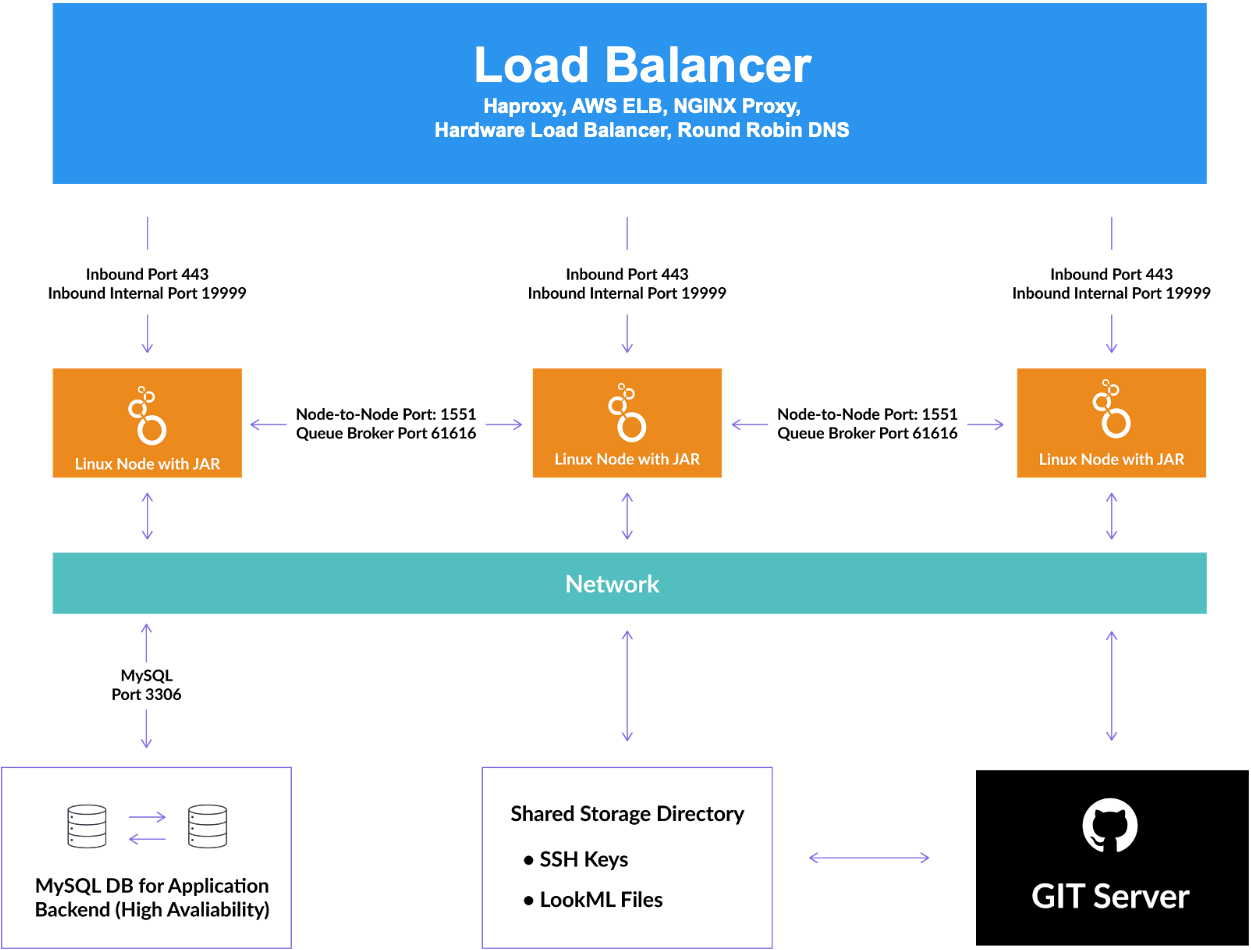
Database dell'applicazione MySQL
Looker utilizza un database delle applicazioni (spesso chiamato database interno) per contenere i dati delle applicazioni. Quando Looker viene eseguito come applicazione a un solo nodo, in genere utilizza un database HyperSQL in memoria.
In una configurazione di Looker in cluster, l'istanza di Looker di ogni nodo deve puntare a un database transazionale condiviso (il database interno o dell'applicazione condivisa). Il supporto per il database dell'applicazione per Looker in cluster è il seguente:
- Solo MySQL è supportato per il database delle applicazioni per le istanze Looker in cluster. Amazon Aurora e MariaDB non sono supportati.
- Sono supportate le versioni MySQL 5.7+ e 8.0+.
- I database in cluster come Galera non sono supportati.
Looker non gestisce la manutenzione e i backup di questo database. Tuttavia, poiché il database ospita quasi tutti i dati di configurazione dell'applicazione Looker, deve essere sottoposto a provisioning come database ad alta disponibilità ed eseguirne il backup almeno una volta al giorno.
Nodi Looker
Ogni nodo è un server su cui è in esecuzione il processo Java di Looker. I server nel cluster Looker devono essere in grado di comunicare tra loro e con il database dell'applicazione Looker. Le porte predefinite sono elencate nella sezione Apri le porte per la comunicazione dei nodi di questa pagina.
Bilanciatore del carico
Per bilanciare il carico o reindirizzare le richieste ai nodi disponibili, è necessario un bilanciatore del carico o un server proxy (ad esempio NGINX o AWS ELB) per indirizzare il traffico a ogni nodo Looker. Il bilanciatore del carico gestisce i controlli di integrità. In caso di errore del nodo, il bilanciatore del carico deve essere configurato per reindirizzare il traffico ai nodi integri rimanenti.
Quando scegli e configuri il bilanciatore del carico, assicurati che possa essere configurato per funzionare solo come livello 4. Il bilanciatore del carico Amazon Classic ELB è un esempio. Inoltre, il bilanciatore del carico deve avere un timeout lungo (3600 secondi) per evitare l'interruzione delle query.
File system condiviso
Devi utilizzare un file system condiviso conforme a POSIX (come NFS, AWS EFS, Gluster, BeeGFS, Lustre o molti altri). Looker utilizza il file system condiviso come repository per varie informazioni utilizzate da tutti i nodi del cluster.
Applicazione Looker (eseguibile JAR)
Devi utilizzare un file JAR dell'applicazione Looker di Looker 3.56 o versioni successive.
Looker consiglia vivamente di eseguire la stessa versione di rilascio e patch di Looker su ogni nodo di un cluster, come descritto in Avviare Looker sui nodi in questa pagina.
Configurazione del cluster
Sono richieste le seguenti attività:
- Installare Looker
- Configurare un database dell'applicazione MySQL
- Configurare il file system condiviso
- Condividi il repository delle chiavi SSH (a seconda della situazione)
- Apri le porte per la comunicazione tra i nodi
- Avvia Looker sui nodi
Installazione di Looker
Assicurati di aver installato Looker su ogni nodo utilizzando i file JAR dell'applicazione Looker e le istruzioni riportate nella pagina della documentazione Passaggi di installazione con hosting del cliente.
Configurazione di un database dell'applicazione MySQL
Per una configurazione di Looker in cluster, il database dell'applicazione deve essere un database MySQL. Se hai un'istanza Looker non in cluster esistente che utilizza HyperSQL per il database dell'applicazione, devi eseguire la migrazione dei dati dell'applicazione dai dati HyperSQL al nuovo database dell'applicazione MySQL condiviso.
Consulta la pagina di documentazione Migrazione a MySQL per informazioni sul backup di Looker e sulla migrazione del database dell'applicazione da HyperSQL a MySQL.
Configurazione del file system condiviso
Solo tipi di file specifici, ovvero file di modelli, chiavi di deployment, plug-in e potenzialmente file manifest dell'applicazione, appartengono al file system condiviso. Per configurare il file system condiviso:
- Sul server che memorizzerà il file system condiviso, verifica di avere accesso a un altro account che possa
suall'account utente Looker. - Sul server per il file system condiviso, accedi all'account utente Looker.
- Se Looker è in esecuzione, arresta la configurazione di Looker.
- Se in precedenza utilizzavi il clustering con script Linux inotify, interrompili, rimuovili da cron ed eliminali.
- Crea una condivisione di rete e montala su ogni nodo del cluster. Assicurati che sia configurato per il montaggio automatico su ogni nodo e che l'utente Looker possa leggerlo e scriverci. Nel seguente esempio, la condivisione di rete è denominata
/mnt/looker-share. Su un nodo, copia le chiavi di deployment e sposta i plug-in e le directory
looker/modelselooker/models-user-*, che archiviano i file del modello, nella condivisione di rete. Ad esempio:mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/Per ogni nodo, aggiungi l'impostazione
--shared-storage-diraLOOKERARGS. Specifica la condivisione di rete, come mostrato in questo esempio:--shared-storage-dir /mnt/looker-shareLOOKERARGSdeve essere aggiunto a$HOME/looker/lookerstart.cfgin modo che le impostazioni non siano interessate dagli aggiornamenti. Se i tuoiLOOKERARGSnon sono elencati in questo file, è possibile che qualcuno li abbia aggiunti direttamente allo script shell$HOME/looker/looker.Ogni nodo del cluster deve scrivere in una directory
/logunivoca o almeno in un file di log univoco.
Condivisione del repository delle chiavi SSH
- Stai creando un cluster di file system condiviso da una configurazione Looker esistente e
- Hai progetti creati in Looker 4.6 o versioni precedenti.
Configura il repository delle chiavi SSH da condividere:
Sul file server condiviso, crea una directory denominata
ssh-share. Ad esempio:/mnt/looker-share/ssh-share.Assicurati che la directory
ssh-sharesia di proprietà dell'utente Looker e che le autorizzazioni siano 700. Inoltre, assicurati che le directory sopra la directoryssh-share(come/mnte/mnt/looker-share) non siano scrivibili da tutti o dal gruppo.Su un nodo, copia i contenuti di
$HOME/.sshnella nuova directoryssh-share. Ad esempio:cp $HOME/.ssh/* /mnt/looker-share/ssh-sharePer ogni nodo, crea un backup del file SSH esistente e crea un collegamento simbolico alla directory
ssh-share. Ad esempio:cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshAssicurati di eseguire questo passaggio per ogni nodo.
Apertura delle porte per la comunicazione dei nodi
I nodi Looker in cluster comunicano tra loro tramite HTTPS con certificati autofirmati e un ulteriore schema di autenticazione basato sulla rotazione dei secret nel database dell'applicazione.
Le porte predefinite che devono essere aperte tra i nodi del cluster sono 1551 e 61616. Queste porte sono configurabili utilizzando i flag di avvio elencati qui. Ti consigliamo vivamente di limitare l'accesso alla rete a queste porte per consentire il traffico solo tra gli host del cluster.
Avvio di Looker sui nodi
Riavvia il server su ogni nodo con i flag di avvio richiesti.
Flag di avvio disponibili
La tabella seguente mostra i flag di avvio disponibili, inclusi quelli necessari per avviare o partecipare a un cluster:
| Flag | Obbligatorio? | Valori | Finalità |
|---|---|---|---|
--clustered |
Sì | Aggiungi il flag per specificare che questo nodo è in esecuzione in modalità cluster. | |
-H o --hostname |
Sì | 10.10.10.10 |
Il nome host che gli altri nodi utilizzano per contattare questo nodo, ad esempio l'indirizzo IP del nodo o il nome host del sistema. Deve essere diverso dai nomi host di tutti gli altri nodi del cluster. |
-n |
No | 1551 |
La porta per la comunicazione tra nodi. Il valore predefinito è 1551. Tutti i nodi devono utilizzare lo stesso numero di porta per la comunicazione tra nodi. |
-q |
No | 61616 |
La porta per la messa in coda degli eventi a livello di cluster. Il valore predefinito è 61616. |
-d |
Sì | /path/to/looker-db.yml |
Il percorso del file contenente le credenziali per il database dell'applicazione Looker. |
--shared-storage-dir |
Sì | /path/to/mounted/shared/storage |
L'opzione deve puntare alla configurazione della directory condivisa precedente in questa pagina che contiene le directory looker/model e looker/models-user-*. |
Esempio di LOOKERARGS e specifica delle credenziali del database
Inserisci i flag di avvio di Looker in un file lookerstart.cfg, che si trova nella stessa directory dei file JAR di Looker.
Ad esempio, potresti voler dire a Looker:
- Per utilizzare il file denominato
looker-db.ymlper le credenziali del database, - che si tratta di un nodo in cluster e
- che gli altri nodi del cluster devono contattare questo host all'indirizzo IP 10.10.10.10.
Specificheresti:
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
Il file looker-db.yml conterrebbe le credenziali del database, ad esempio:
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
Inoltre, se il tuo database MySQL richiede una connessione SSL, il file looker-db.yml richiede anche quanto segue:
ssl: true
Se non vuoi memorizzare la configurazione nel file looker-db.yml sul disco, puoi configurare la variabile di ambiente LOOKER_DB in modo che contenga un elenco di chiavi e valori per ogni riga del file looker-db.yml. Ad esempio:
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Trovare le chiavi di deployment SSH di Git
La posizione in cui Looker archivia le chiavi di deployment SSH di Git dipende dalla release in cui è stato creato il progetto:
- Per i progetti creati prima di Looker 4.8, le chiavi di deployment vengono archiviate nella directory SSH integrata del server,
~/.ssh. - Per i progetti creati in Looker 4.8 o versioni successive, le chiavi di deployment vengono archiviate in una directory controllata da Looker,
~/looker/deploy_keys/PROJECT_NAME.
Modifica di un cluster Looker
Dopo aver creato un cluster Looker, puoi aggiungere o rimuovere nodi senza apportare modifiche agli altri nodi del cluster.
Aggiornamento di un cluster a una nuova release di Looker
Gli aggiornamenti potrebbero comportare modifiche allo schema del database interno di Looker che non sarebbero compatibili con le versioni precedenti di Looker. Per aggiornare Looker, esistono due metodi.
Metodo più sicuro
- Crea un backup del database dell'applicazione.
- Arresta tutti i nodi del cluster.
- Sostituisci i file JAR su ogni server.
- Avvia ogni nodo uno alla volta.
Metodo più veloce
Per eseguire l'aggiornamento utilizzando questo metodo più rapido ma meno completo:
- Crea una replica del database delle applicazioni di Looker.
- Avvia un nuovo cluster che punta alla replica.
- Punta il server proxy o il bilanciamento del carico ai nuovi nodi, dopodiché puoi arrestare i vecchi nodi.