Cette page explique comment utiliser le connecteur Spark Spanner pour lire des données à partir de Spanner à l'aide d'Apache Spark.
Calculer les coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Dataproc
- Spanner
- Cloud Storage
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Avant d'exécuter le tutoriel, assurez-vous de connaître la version du connecteur et d'obtenir un URI de connecteur.
Spécifier l'URI du fichier JAR du connecteur
Les versions du connecteur Spark Spanner sont répertoriées dans le dépôt GoogleCloudDataproc/spark-spanner-connector GitHub.
Spécifiez le fichier JAR du connecteur en remplaçant les informations de version du connecteur dans la chaîne d'URI suivante:
gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Le connecteur est disponible pour les versions Spark 3.1+.
Exemple de gcloud CLI:
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-1.0.0.jar \ -- job-args
Préparer la base de données Spanner
Si vous ne disposez pas d'une table Spanner, vous pouvez suivre le tutoriel pour en créer une. Vous disposerez ensuite d'un ID d'instance, d'un ID de base de données et d'une table Singers.
Créer un cluster Dataproc
Tout cluster Dataproc qui utilise le connecteur a besoin des champs d'application spanner ou cloud-platform. Les clusters Dataproc ont une portée par défaut cloud-platform pour l'image 2.1 ou ultérieure. Si vous utilisez une version antérieure, vous pouvez créer un cluster Dataproc à l'aide de la console Google Cloud, de la Google Cloud CLI et de l'API Dataproc.
Console
- Dans la console Google Cloud, ouvrez la page Dataproc Créer un cluster.
- Dans l'onglet "Gérer la sécurité", cliquez sur "Active le champ d'application Cloud Platform pour ce cluster" dans la section "Accès au projet".
- Renseignez ou confirmez les autres champs de création de cluster, puis cliquez sur "Créer".
Google Cloud CLI
gcloud dataproc clusters create CLUSTER_NAME --scopes https://www.googleapis.com/auth/cloud-platform
API
Vous pouvez spécifier GceClusterConfig.serviceAccountScopes dans le cadre d'une requête clusters.create. Exemple :
"serviceAccountScopes": ["https://www.googleapis.com/auth/cloud-platform"],
Vous devez vous assurer que l'autorisation Spanner correspondante est attribuée au compte de service de VM Dataproc. Si vous utilisez Data Boost dans l'atelier, consultez l'autorisation IAM Data Boost.
Lire des données depuis Spanner
Vous pouvez utiliser Scala et Python pour lire les données de Spanner dans un DataFrame Spark à l'aide de l'API de source de données Spark.
Scala
- Examinez le code et remplacez les espaces réservés [projectId], [instanceId], [databaseId] et [table] par l'ID du projet, l'ID de l'instance, l'ID de la base de données et la table que vous avez créés précédemment. L'option enableDataBoost active la fonctionnalité Data Boost de Spanner, qui a un impact quasi nul sur l'instance Spanner principale.
object singers { def main(): Unit = { /* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "[projectId]") .option("instanceId", "[instanceId]") .option("databaseId", "[databaseId]") .option("enableDataBoost", true) .option("table", "[table]") .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
- Exécuter le code sur votre cluster
- Se connecter au nœud maître du cluster Dataproc via SSH
- Accédez à la page Clusters Dataproc dans la console Google Cloud, puis cliquez sur le nom de votre cluster.
- Sur la page >Détails du cluster, sélectionnez l'onglet "Instances de VM". Cliquez ensuite sur
SSHà droite du nom du nœud maître du cluster.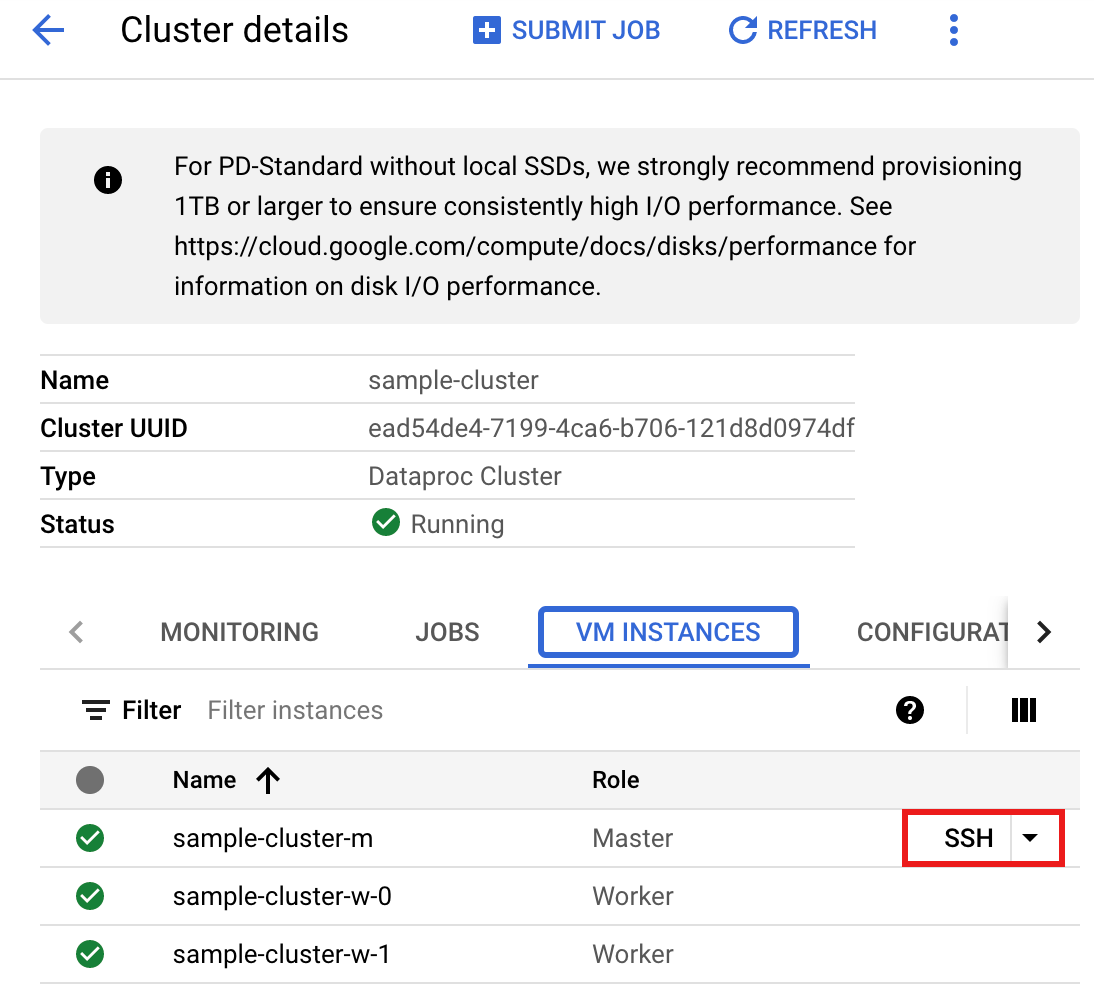
Une fenêtre de navigateur s'ouvre dans votre répertoire d'accueil sur le nœud maître.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Accédez à la page Clusters Dataproc dans la console Google Cloud, puis cliquez sur le nom de votre cluster.
- Créez le fichier
singers.scalaavec l'éditeur de textevi,vimounanopréinstallé, puis collez le code Scala à partir de la liste de codes Scala.nano singers.scala
- Lancez le REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
- Exécutez "singers.scala" avec la commande
:load singers.scalapour créer la table SpannerSingers. La liste de sortie affiche des exemples du résultat de la commande "Singers".> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
PySpark
- Examinez le code et remplacez les espaces réservés [projectId], [instanceId], [databaseId] et [table] par l'ID du projet, l'ID de l'instance, l'ID de la base de données et la table que vous avez créés précédemment. L'option enableDataBoost active la fonctionnalité Data Boost de Spanner, qui a un impact quasi nul sur l'instance Spanner principale.
#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "[projectId]") \ .option("instanceId", "[instanceId]") \ .option("databaseId", "[databaseId]") \ .option("enableDataBoost", "true") \ .option("table", "[table]") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
- Exécutez le code sur votre cluster
- Se connecter au nœud maître du cluster Dataproc via SSH
- Accédez à la page Clusters Dataproc dans la console Google Cloud, puis cliquez sur le nom de votre cluster.
- Sur la page Détails du cluster, sélectionnez l'onglet "Instances de VM". Cliquez ensuite sur
SSHà droite du nom du nœud maître du cluster.
Une fenêtre de navigateur s'ouvre dans votre répertoire d'accueil sur le nœud principal.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Accédez à la page Clusters Dataproc dans la console Google Cloud, puis cliquez sur le nom de votre cluster.
- Créez le fichier
singers.pyavec l'éditeur de textevi,vimounanopréinstallé, puis collez le code PySpark à partir de la liste de code PySpark.nano singers.py
- Exécutez singers.py avec
spark-submitpour créer la table SpannerSingers.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- Se connecter au nœud maître du cluster Dataproc via SSH
Nettoyage
Pour nettoyer et éviter que les ressources créées dans ce tutoriel soient facturées en permanence sur votre compte Google Cloud, procédez comme suit :
gcloud dataproc clusters stop CLUSTER_NAME gcloud dataproc clusters delete CLUSTER_NAME