이 문서에서는 서드 파티 소스에서 Dataplex Universal Catalog로 메타데이터를 가져오는 데 사용할 수 있는 관리형 연결 파이프라인을 간략하게 설명합니다.
관리형 연결을 사용하면 대규모로 메타데이터를 Dataplex Universal Catalog로 가져올 수 있습니다. 관리형 연결 파이프라인은 데이터 소스에서 메타데이터를 추출한 후 Dataplex Universal Catalog로 가져옵니다. 필요한 경우 파이프라인은Google Cloud 프로젝트에 Dataplex Universal Catalog 항목 그룹도 만듭니다. 요구사항에 따라 워크플로를 조정하고 가져오기 작업을 예약할 수 있습니다.
자체 커스텀 커넥터를 빌드하여 서드 파티 소스에서 메타데이터를 추출합니다. 예를 들어 MySQL, SQL Server, Oracle, Snowflake, Databricks 등의 소스에서 메타데이터를 추출하는 커넥터를 빌드할 수 있습니다. 샘플 커스텀 커넥터를 빌드하는 단계는 메타데이터 가져오기를 위한 커스텀 커넥터 개발을 참조하세요. 다양한 서드 파티 소스에 사용할 수 있는 커뮤니티 제공 커스텀 커넥터를 사용할 수도 있습니다.
관리형 연결 파이프라인을 실행하는 단계는 워크플로를 사용하여 커스텀 소스에서 메타데이터 가져오기를 참조하세요.
관리형 연결 작동 방식
다음 다이어그램은 관리형 연결 파이프라인을 보여줍니다.
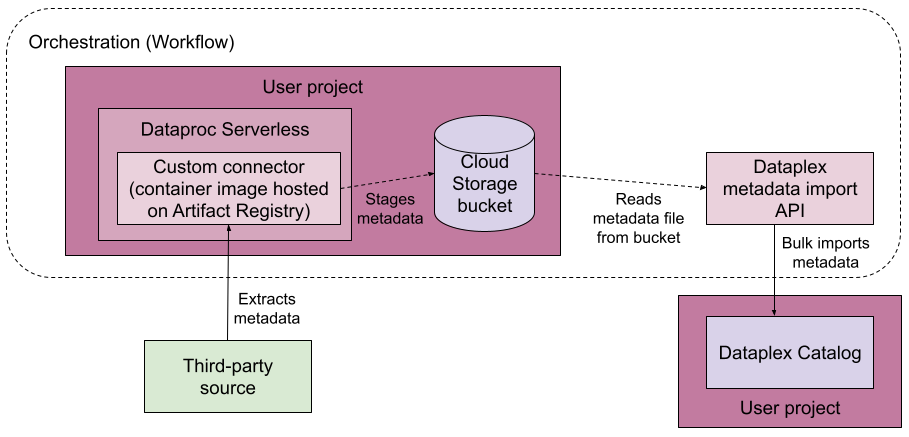
관리형 연결은 대략적으로 다음과 같이 작동합니다.
데이터 소스의 커넥터를 빌드합니다.
커넥터는 Apache Spark용 서버리스에서 실행할 수 있는 Artifact Registry 이미지여야 합니다.
조정 플랫폼인 Workflows에서 관리형 연결 파이프라인을 실행합니다.
관리형 연결 파이프라인은 다음 작업을 실행합니다.
- 항목 그룹이 아직 없는 경우 구성에 따라 대상 항목 그룹을 만듭니다.
- 커넥터를 실행합니다. 커넥터는 데이터 소스에서 메타데이터를 추출하고 Dataplex Universal Catalog로 가져올 수 있는 메타데이터 가져오기 파일을 생성합니다.
- 메타데이터 추출 진행 상황을 모니터링합니다.
- 메타데이터 가져오기 작업을 실행하여 메타데이터를 Dataplex Universal Catalog로 가져옵니다.
- 메타데이터 가져오기 작업의 진행률을 모니터링합니다.
관리형 연결 파이프라인은 Google Cloud Apache Spark용 서버리스를 사용하여 커넥터를 실행하고 Dataplex Universal Catalog 메타데이터 가져오기 API 메서드를 사용하여 메타데이터 가져오기 작업을 실행합니다.
가져오는 메타데이터는 Dataplex Universal Catalog 항목과 해당 관점으로 구성됩니다. Dataplex Universal Catalog 메타데이터에 대한 자세한 내용은 Dataplex Universal Catalog의 메타데이터 관리 정보를 참조하세요.
커뮤니티 제공 커스텀 커넥터
서드 파티 소스에서 메타데이터를 가져오려면 커뮤니티 제공 커스텀 커넥터를 사용하면 됩니다. 설정 안내와 커넥터에 관한 자세한 내용은 각 커넥터의 리드미 파일을 참조하세요.
| 데이터 소스 | 저장소 |
|---|---|
| MySQL | mysql-connector |
| Oracle | oracle-connector |
| PostgreSQL | postgresql-connector |
| Snowflake | snowflake-connector |
| SQL Server | sql-server-connector |