You can search for the following data assets:
- BigQuery sharing (formerly Analytics Hub) linked datasets
- BigQuery datasets, tables, views, and models
- Bigtable instances, clusters, and tables (including column family details)
- Data Catalog tag templates, entry groups, and custom entries
- Dataplex Universal Catalog lakes, zones, tables, and filesets
- Dataproc Metastore services, databases, and tables
- Pub/Sub data streams
- Spanner instances, databases, tables, and views
- Vertex AI Models, Datasets, and Vertex AI Feature Store resources
- Assets in enterprise data silos connected to Data Catalog
Search scope
You might have different search results based on your permissions. Data Catalog search results are scoped according to your role.
The search results include those resources that belong to all organizations that you have access to.
You can review the different types of IAM role and permissions available for Data Catalog. For example, if you have BigQuery metadata read access to an object, that object appears in your Data Catalog search results.
The following list describes the minimum permissions required to perform search:
To search for a table, you need
bigquery.tables.getpermission for that table.To search for a dataset, you need
bigquery.datasets.getpermission for that dataset.To search for metadata for a dataset or a table, you need the
roles/bigquery.metadataViewerIAM role.To search for all resources within a project or organization, you need
datacatalog.catalogs.searchAllpermission. It works for all resources independent of the source system.
If you have access to a BigQuery table but not to the dataset containing that table, the table still shows up as expected in the Data Catalog search. The same access logic applies to all supported systems, such as Pub/Sub and Data Catalog itself.
Recall issues in search
Data Catalog search queries don't guarantee full recall. Results that match your query might not be returned, even in subsequent result pages. Additionally, if you repeat search queries, returned (and not returned) results can vary.
If you are experiencing recall issues and you don't have to fetch the
results in any specific order, consider setting the orderBy parameter to
default when calling the
catalog.search method.
Use the admin_search flag
Using the admin_search flag on the search request ensures full recall.
Administrator search requires datacatalog.catalogs.searchAll permission to be
set on all projects and organizations in the search scope. When using
admin_search, only default orderBy is allowed.
Date-sharded tables
Data Catalog aggregates date-sharded tables into a single logical entry. This entry has the same schema as the table shard with the most recent date, and contains aggregate information about the total number of shards. The entry derives its access level from the dataset it belongs to. Data Catalog search only shows these logical entries if the user has the access to the dataset that contains them. Individual date-sharded tables aren't visible in Data Catalog search, even if they are present in Data Catalog and can be tagged.
Filters
Filters let you narrow down search results. All filters are grouped in sections:
- Scope to limit search to starred items only.
- Systems such as BigQuery, Pub/Sub, Dataplex Universal Catalog, Dataproc Metastore, custom systems, Vertex AI, and Data Catalog itself. Data Catalog system contains filesets and custom entries.
- Lakes and zones come from Dataplex Universal Catalog.
- Data types such as data streams, datasets, lakes, zones, filesets, models, tables, views, services, databases, and custom types.
- Projects lists all projects available to you.
- Tags lists all tag templates (and their individual fields) available to you.
- Datasets come from BigQuery and Vertex AI.
- Public datasets are publicly available data from BigQuery.
You can combine filters from multiple sections to find assets that match at least
one condition from every selected section. Multiple filters selected within
a single section are evaluated using the OR logical operator. For example,
consider the following filter combination:
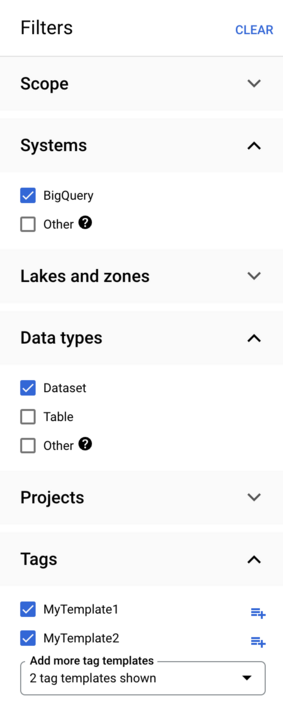
Data Catalog looks for the following:
BigQuery datasets tagged with
MyTemplate1template.BigQuery datasets tagged with
MyTemplate2template.BigQuery tables tagged with
MyTemplate1template.BigQuery tables tagged with
MyTemplate2template.
Filter by tag value
The Tags filters let you query for assets tagged using a specific template. You can use the Customize menu to further refine results and filter by specific tag values. The tag value filter conditions depend on that tag field's data type. For example, for datetime and number fields, you can specify a specific date or a range.
Filters visibility
The filters displayed in every section depend on the current query in the Search box. The whole set of search results might include entries that match the current query, but the filters that correspond to those entries might not be shown on the Filters pane.
Search for data assets
Console
In the Google Cloud console, go to the Dataplex Universal Catalog Search page. For Choose search platform, select Data Catalog as the search mode. In the search field, enter your query or use the Filters pane to refine
the search parameters. You can manually add the following filters: To search for data assets publicly available in Google Cloud in addition to
the assets available to you, select Include public datasets Additionally, you can do the following: Filter your search by adding a keyword:value
to your search terms in the search field:
Console
Keyword Description
name:Match data asset name
column:Match column name or nested column name
description:Match table description
Perform a tag search by adding one of the following tag keyword prefixes to your search terms in the search field:
| Tag | Description |
|---|---|
tag:project-name.tag_template_name |
Match tag name |
tag:project-name.tag_template_name.key |
Match a tag key |
tag:project-name.tag_template_name.key:value |
Match tag key:string value pair |
Search expression tips
Enclose your search expression in quotes ("
search terms") if it contains spaces.You can precede a keyword with "NOT" (all CAPS required) to match the logical negation of the
keyword:termfilter. You can also use "AND" and "OR" (all-CAPS required) boolean operators to combine search expressions.For example:
NOT column:termlists all columns except those that match the specified term. For a list of keywords and other terms you can use in a Data Catalog search expression, see Data Catalog search syntax.
Search example
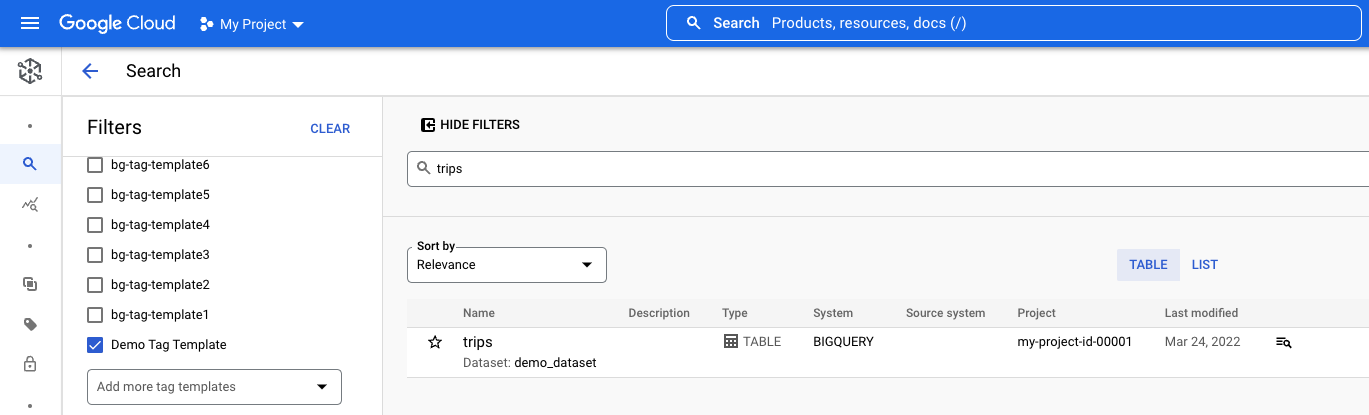
Consider an example where you want to search for the trips table that you set
up in
Tag a BigQuery table by using Data Catalog:
- In the search field, enter
trips, and click Search. In the Filters pane, select the following:
- In the Systems section, select BigQuery to exclude data assets with the same name that belong to other systems.
- In the Projects section, select your project ID to exclude data assets from other projects. If your project isn't displayed, click Add project and select your project.
- In the Tags section, select Demo Tag Template to check if a tag that
uses this template is attached to the
tripstable. If this template isn't displayed, click the Add more tag templates, search for and select the tag template, and click OK.
With all the selected filters, the search results contain only one
entry—the BigQuery trips table in your project with an attached
tag that uses the Demo Tag Template template.
Java
Before trying this sample, follow the Java setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Java API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
Node.js
Before trying this sample, follow the Node.js setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Node.js API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
Python
Before trying this sample, follow the Python setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Python API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
REST & CMD LINE
If you don't have access to Cloud Client libraries for your language or
want to test the API using REST requests, see the following examples
and refer to the
Data Catalog REST API
documentation.
Before using any of the request data,
make the following replacements:
HTTP method and URL:
Request JSON body:
To send your request, expand one of these options: You should receive a JSON response similar to the following:REST
1. Search catalog.
POST https://datacatalog.googleapis.com/v1/catalog:search
{
"query":"trips",
"scope":{
"includeOrgIds":[
"organization-id"
]
}
}
{
"results":[
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry1-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/taxi_trips"
},
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry2-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/tlc_yellow_trips_2018"
}
]
}
View table details
Use Data Catalog to view table details.
In the Google Cloud console, go to the Dataplex Universal Catalog Search page.
For Choose search platform, select Data Catalog as the search mode.
In the search box, enter the name of a dataset that has a table.
For example, if you completed the Tag a BigQuery table by using Data Catalog quickstart, you can search for
demo-datasetand select thetripstable.Click the table.
The BigQuery table details page opens.
The table details include the following sections:
BigQuery table details. Includes information such as the time of creation, time of last modification, time of expiration, resource URLs, and labels.
Tags. Lists the applied tags.You can edit the tags from this page and view the tag template. Click the Actions icon.
Schema and column tags. Lists the applied schema and their values.
Star your favorite entries and search for them
If you frequently browse the same data assets, you can include their entries in a personalized list by marking them with stars.
In the Google Cloud console, go to the Dataplex Universal Catalog Search page.
For Choose search platform, select Data Catalog as the search mode.
Find your asset, and then star its entry in one of two ways:
- Click next to the entry in the search results.
- Click the entry name to open its details page and click the STAR on the action bar at the top.
You can star up to 200 entries.
Starred entries appear in the Starred Entries list on the search page before you enter a search query in the search bar. This list is visible only to you.
To search for only starred entries, in the Filters pane, in the Scope section, select Starred.
You can also use the corresponding methods of
Data Catalog API to star and
unstar entries. When searching for assets, use the starredOnly parameter in
the scope object. For more information, see the
catalog.search
method.
What's next
Understand search syntax for Data Catalog.
Learn how to search for resources in Dataplex Universal Catalog.