Cortex para Meridian
Esta página detalha o processo de preparação de dados e automatização na nuvem para o Google Meridian. O Cortex Framework para o Meridian simplifica a Marketing Mix Modeling (MMM) de código aberto com dados de vendas e multimédia. O Cortex Framework simplifica este processo fornecendo modelos de dados pré-configurados e automatizando a execução do modelo de código aberto Meridian através de Google Cloud serviços como o Colab Enterprise e os fluxos de trabalho.
Uma das principais propostas de valor do Google Cloud Cortex Framework é fornecer uma base de dados e inteligência artificial (IA) para a inteligência empresarial de próxima geração que permite a análise em áreas importantes, como vendas, marketing, processamento de encomendas e gestão de inventário.
O Cortex Framework para marketing fornece indicadores essenciais de desempenho (IEDs) e métricas de várias plataformas de meios de comunicação. Estas métricas são uma parte significativa do passo de preparação dos dados pré-modelagem para executar a MMM de código aberto mais recente da Google, denominada Meridian. Os anunciantes, as agências e os parceiros podem acelerar o processo de preparação de dados pré-modelagem tirando partido da base de dados do Google Cloud Cortex Framework.
O Cortex for Meridian simplifica o processo de pré-modelagem através da recolha e transformação eficientes de dados das origens de dados principais do Cortex Framework, incluindo:
Para mais informações, consulte a documentação do Meridian.
Ficheiro de configuração
Durante a execução do bloco de notas, o sistema obtém os parâmetros de configuração do ficheiro cortex_meridian_config.json localizado na pasta configuration no Cloud Storage.
A secção seguinte partilha exemplos de diferentes ficheiros YAML de configuração para a execução do Meridian:
Vendas
Exemplo de ficheiro YAML de configuração para vendas como KPIs:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
Conversões
Exemplos de ficheiros YAML de configuração para conversões como KPIs:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
A tabela seguinte descreve o valor de cada parâmetro de configuração do ficheiro cortex_meridian_config.json:
| Parâmetro | Significado | Valor predefinido | Descrição |
cortex_bq_project_id
|
Projeto com os conjuntos de dados do Cortex Framework. | {PROJECT_ID}
|
O Google Cloud ID do projeto. |
cortex_meridian_marketing_data_set_id
|
Conjunto de dados do BigQuery com o Cortex para a vista Meridian. | O valor de configuração de k9.datasets.reporting no ficheiro config.json.
|
O conjunto de dados que contém a vista cortex_meridian_marketing_view_name.
|
cortex_meridian_marketing_view_name
|
Vista do BigQuery com o Cortex para dados de marketing e vendas da Meridian. | "CrossMediaSalesInsightsWeeklyAgg"
|
A vista que contém dados de marketing e vendas agregados semanalmente. |
column_mappings.controls
|
Opcional: pode conter os fatores de confusão que têm um efeito causal no IED alvo e na métrica dos meios. | []
|
Para ver detalhes da modelagem de dados do Meridian sobre as variáveis de controlo, consulte o artigo Variáveis de controlo. |
column_mappings.geo
|
As colunas que fornecem informações geográficas. | "geo"
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.kpi
|
O IED alvo para o modelo. | "number_of_sales_orders" ou "conversions" .
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.media
|
Matriz de colunas que fornecem impressões para o canal. | [
"Tiktok_impression",
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.media_spend
|
Colunas que indicam os gastos do canal. | [
"Tiktok_spend",
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.population
|
A população de cada área geográfica. | "population"
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.revenue_per_kpi
|
A receita média de uma unidade de IED. | "average_revenue_per_sales_order" ou ""
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
column_mappings.time
|
A coluna de tempo: início da semana (segunda-feira). | "time"
|
Para ver detalhes da modelagem de dados do Meridian, consulte o artigo Recolha e organize os seus dados. |
channel_names
|
Matriz de nomes de canais. | [
"TikTok",
|
Os nomes usados para o índice do canal devem corresponder a column_mappings.media
e column_mappings.media_spend.
|
data_processing.kpi_type
|
O KPI pode ser a receita ou outro KPI que não seja a receita. O tipo de KPI sem receita também pode ser usado mesmo quando a receita é, em última análise, o KPI. | "{USE_CASE_SPECIFIC}"
|
Para ver detalhes da modelagem de dados do Meridian para o IED, consulte IED. |
data_processing.roi_mu
|
Distribuição prévia no ROI de cada canal de comunicação. roi_mu
(usado com ROI_M no bloco de notas).
|
{USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados do Meridian, certifique-se de que lê e compreende: Configure o modelo e a referência da API. |
data_processing.roi_sigma
|
Distribuição prévia no ROI de cada canal de comunicação roi_sigma
(usado com ROI_M no bloco de notas).
|
{USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados do Meridian, certifique-se de que lê e compreende os seguintes artigos: Configure o modelo e Referência da API. |
data_processing.sample.prior
|
Número de amostras retiradas da distribuição anterior. | {USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o processamento de dados do Meridian, certifique-se de que lê e compreende os seguintes artigos: Parametrizações anteriores predefinidas e Referência da API. |
data_processing.sample.posterior.n_chains
|
Número de cadeias MCMC. | {USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados da Meridian, certifique-se de que lê e compreende os seguintes artigos: Configure o modelo e Referência da API |
data_processing.sample.posterior.n_adapt
|
Número de resultados de adaptação por cadeia. | {USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados do Meridian, certifique-se de que lê e compreende o seguinte: Configure o modelo e referência da API. |
data_processing.sample.posterior.n_burnin
|
Número de resultados de preenchimento por cadeia. | {USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados do Meridian, certifique-se de que lê e compreende os seguintes artigos: Configure o modelo e Referência da API. |
data_processing.sample.posterior.n_keep
|
Número de resultados por cadeia a manter para inferência. | {USE_CASE_SPECIFIC}
|
Para ver detalhes sobre o tratamento de dados do Meridian, certifique-se de que lê e compreende os seguintes artigos: Configure o modelo e Referência da API. |
Compatibilidade com o Meridian
A base de dados do Cortex Framework e o Meridian são lançados em separado. As notas de lançamento do Cortex Framework oferecem uma vista geral dos respetivos lançamentos e versões. No repositório do GitHub do Meridian pode ver as versões mais recentes disponíveis do Meridian. Os pré-requisitos e as recomendações do sistema do Meridian estão disponíveis no manual do utilizador do Meridian.
As versões da base de dados do Cortex Framework são testadas com uma versão específica do Meridian. Pode encontrar o Meridian compatível no bloco de notas do Jupyter, conforme mostra a imagem seguinte:

Para atualizar para uma versão mais recente do Meridian, modifique a linha correspondente no notebook. Tenha em atenção que podem ser necessários ajustes de código adicionais no bloco de notas.
Modelo de dados
Esta secção descreve o CrossMediaSalesInsightsWeeklyAggmodelo de dados através do diagrama de relação entre entidades (ERD).
O Cortex para o Meridian baseia-se numa única vista, CrossMediaSalesInsightsWeeklyAgg, para funcionar. A origem de dados desta vista é determinada pela
definição de configuração k9.Meridian.salesDataSourceType, que pode ser:
BYOD(Bring Your Own Data): integração de dados personalizados.SAP_SALES: dados de vendas de sistemas SAP.ORACLE_SALES: dados de vendas de sistemas Oracle EBS.
A secção seguinte partilha os diagramas de relação de entidades para CrossMediaForMeridian:
TSPD
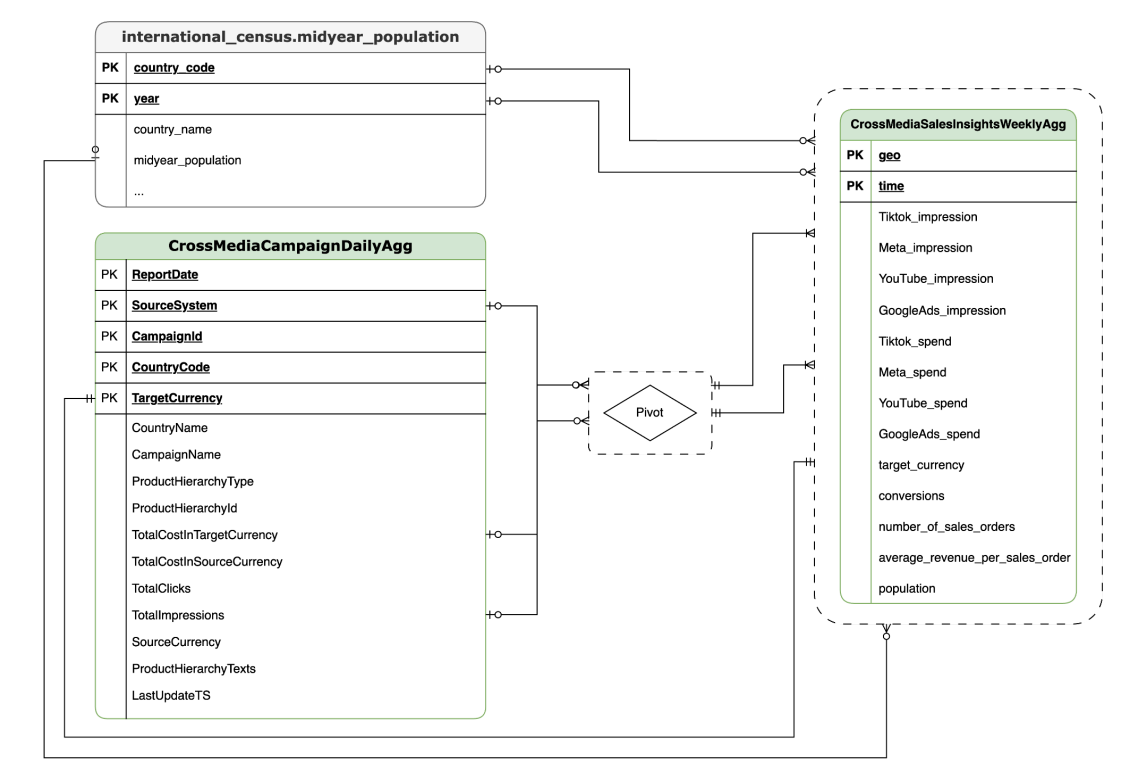
CortexForMeridian sem dados de vendas.SAP
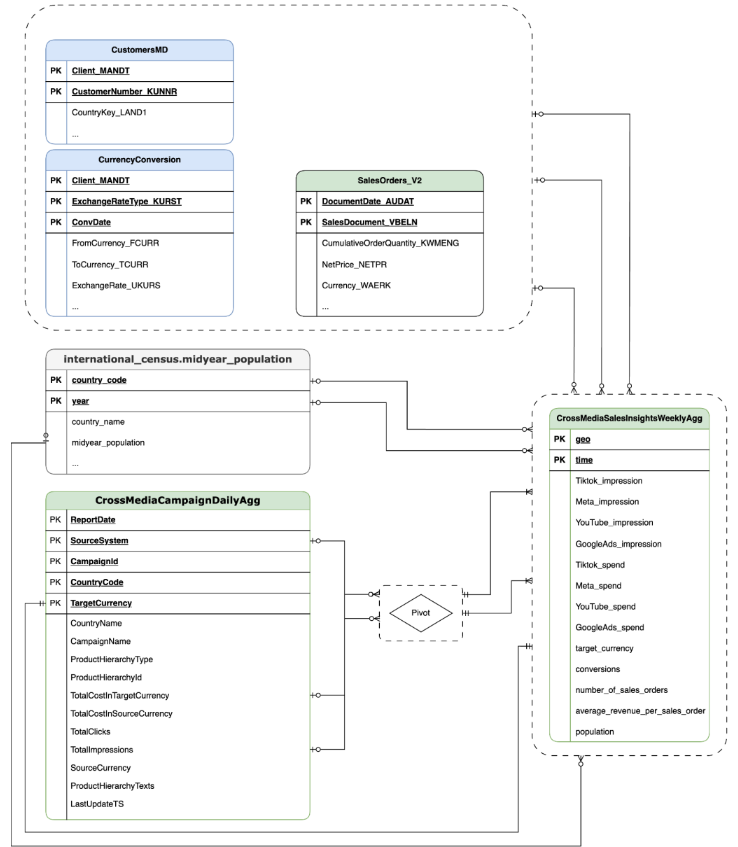
CortexForMeridian com dados SAP.OracleEBS
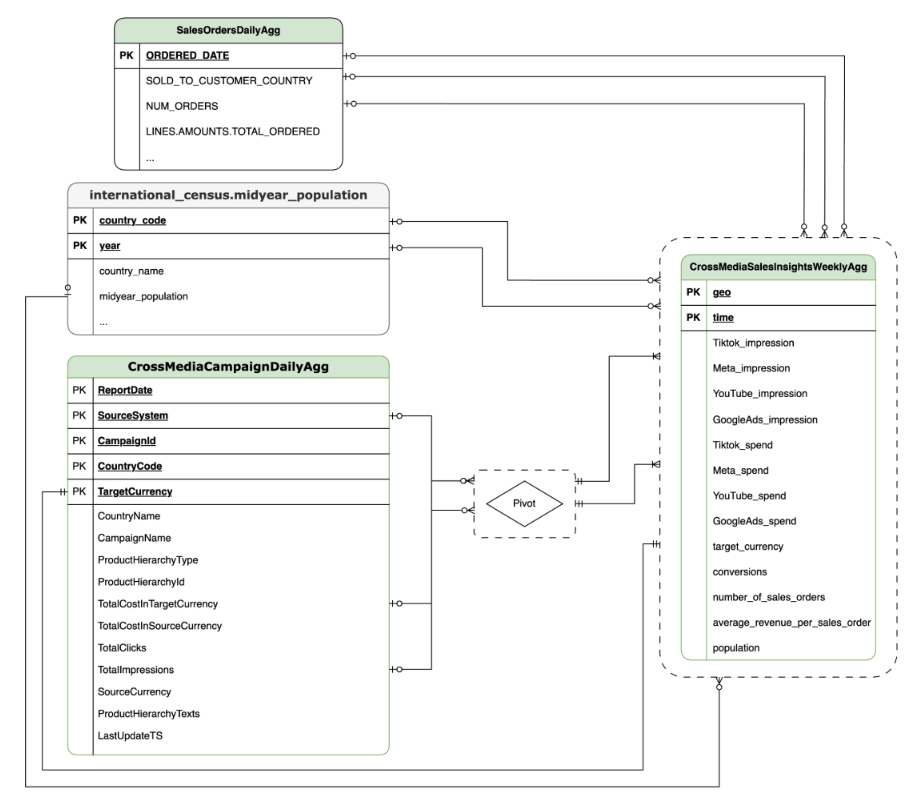
CortexForMeridian com dados do Oracle EBS.A tabela seguinte mostra o esquema detalhado da vista CrossMediaSalesInsightsWeeklyAgg, que faz parte do Cortex para Meridian:
| Coluna | Tipo | Descrição |
| geo | String | A área geográfica usada para agregar todos os outros valores. |
| tempo | String | A dimensão de tempo que é usada para agregar todos os outros valores. |
| Tiktok_impression | Número inteiro | O número de vezes que os seus anúncios foram apresentados no TikTok. |
| Meta_impression | Número inteiro | O número de vezes que os seus anúncios foram apresentados no Meta. |
| YouTube_impression | Número inteiro | O número de vezes que os seus anúncios foram apresentados no YouTube. |
| GoogleAds_impression | Número inteiro | O número de vezes que os seus anúncios foram apresentados no Google Ads. |
| Tiktok_spend | Flutuante | O valor gasto em publicidade no TikTok. |
| Meta_spend | Flutuante | O valor gasto em publicidade na Meta. |
| YouTube_spend | Flutuante | O valor gasto em publicidade no YouTube. |
| GoogleAds_spend | Flutuante | O valor gasto em publicidade no Google Ads. |
| target_currency | String | Moeda alvo usada para todas as colunas de receita. |
| conversões | Número inteiro | Conversões. |
| number_of_sales_orders | Número inteiro | Número de encomendas de vendas do Oracle EBS ou SAP. |
| average_revenue_per_sales_order | Flutuante | Receita média por encomenda de vendas do Oracle EBS ou SAP. |
| população | Número inteiro | Tamanho da população da área geográfica. |
Implementação
Esta página descreve os passos para implementar o Cortex Framework para o Meridian, o que permite ter a melhor MMM no seu ambiente Google Cloud .
Para uma demonstração de início rápido, consulte o artigo Demonstração de início rápido para o Meridian.
Arquitetura
O Cortex for Meridian usa o Cortex Framework para marketing e dados de vários meios combinados com dados de vendas. Pode importar dados de vendas do Oracle EBS, SAP ou outro sistema de origem.
O diagrama seguinte descreve os componentes principais do Cortex para Meridian:
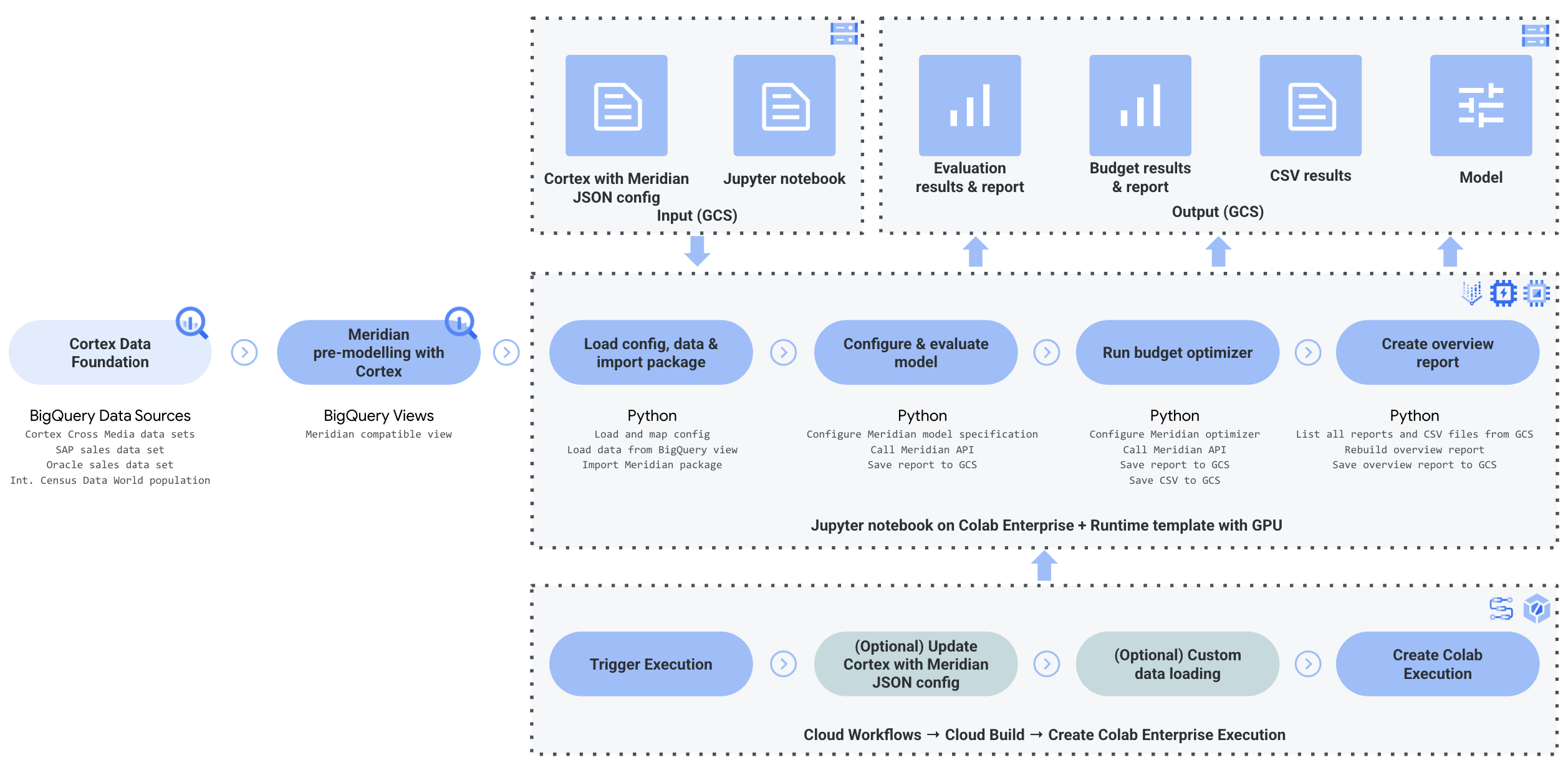
Componentes e serviços Meridian
Durante a implementação da base de dados do Cortex Framework (consulte os pré-requisitos de implementação),
pode ativar o Cortex para o Meridian definindo deployMeridian como true no ficheiro config.json. Esta opção inicia um pipeline do Cloud Build adicional, que instala os seguintes componentes e serviços necessários para o Meridian:
Visualização do BigQuery: é criada uma visualização no conjunto de dados de relatórios do K9 denominada
CrossMediaSalesInsightsWeeklyAgg. Isto permite consultar dados de marketing e dados de vendas do Cortex Framework. A implementação real da vista e das origens subjacentes depende da origem de dados de vendas que selecionar durante a implementação.Contentor do Cloud Storage: o contentor contém todos os artefactos necessários e produzidos pelo Cortex para o Meridian nas seguintes pastas:
PROJECT_ID-cortex-meridianconfiguration: defina as definições e os parâmetros do Cortex para o Meridian. É usado pelo bloco de notas do Colab Enterprise durante a execução do bloco de notas.csv: os dados não processados resultantes da execução do Meridian são guardados como ficheiros CSV aqui.models: O modelo gerado a partir da execução do Meridian é guardado aqui.notebook-run-logs: as cópias dos notebooks para cada execução e registos são guardadas aqui.notebooks: contém o bloco de notas principal com código e lógica para executar o Cortex para o Meridian. Este bloco de notas destina-se a personalização adicional para dar resposta às suas necessidades e requisitos específicos.reporting: esta é a pasta onde os relatórios das execuções do Meridian são guardados. Também contém um modelo HTML para gerar um relatório de vista geral com links para o resultado do relatório do Meridian.
Colab Enterprise: o Colab Enterprise é um serviço gerido no Google Cloud que oferece um ambiente seguro e colaborativo para fluxos de trabalho de ciência de dados e aprendizagem automática através de blocos de notas do Jupyter. Oferece funcionalidades como infraestrutura gerida, controlos de segurança de nível empresarial e integração com outros serviços, o que o torna adequado para equipas que trabalham com dados confidenciais e que requerem uma administração robusta. Google Cloud Um ambiente gerido para executar o Jupyter Notebook.
O Cortex para Meridian usa o Colab Enterprise para definir um modelo de tempo de execução com a infraestrutura necessária para automatizar as execuções do Meridian.
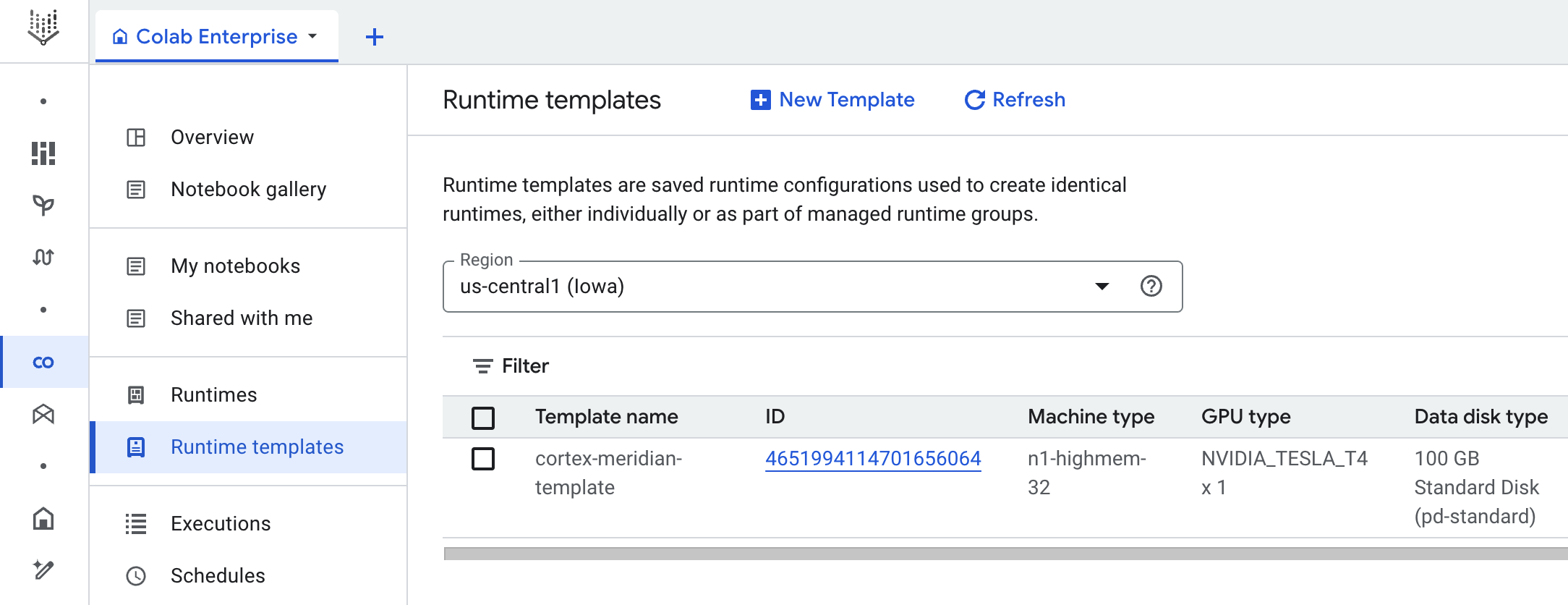
Quando aciona o pipeline completo, usando o fluxo de trabalho, é criada uma execução. Esta ação executa uma cópia do bloco de notas do Jupyter atual a partir do Cloud Storage com a configuração mais recente.
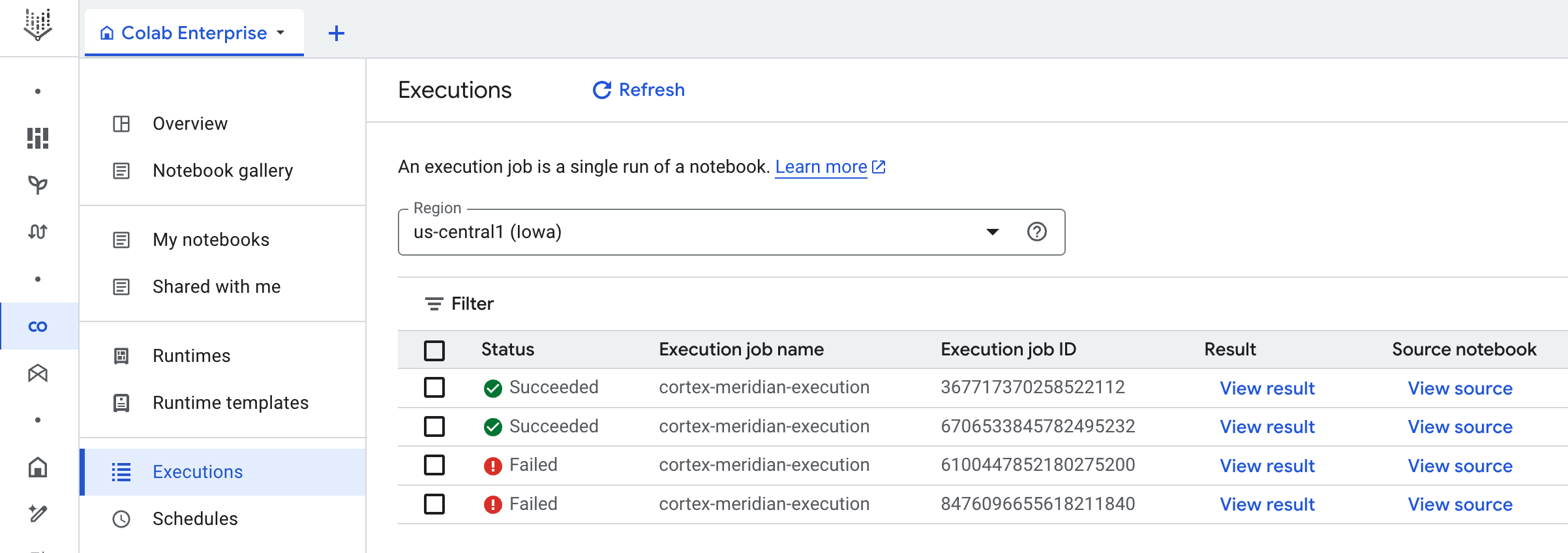
Fluxo de trabalho: um fluxo de trabalho do Google Cloud denominado
cortex-meridian-execute-notebookorquestra a execução do pipeline completo do Cortex for Meridian. O fluxo de trabalho chama a API Colab Enterprise que cria um tempo de execução com base no modelo de tempo de execução e executa uma execução do bloco de notas com as configurações atuais e, por fim, guarda todos os resultados no Cloud Storage.
Figura 8. Fluxos de trabalho para o Meridian. Tem duas opções de configuração opcionais disponíveis para o fluxo de trabalho:
- Se puder fornecer uma nova configuração JSON do Cortex for Meridian como entrada para o fluxo de trabalho. Se o fizer, o fluxo faz uma cópia de segurança da configuração antiga e atualiza a configuração com as suas informações. Consulte REPLACE para mais informações.
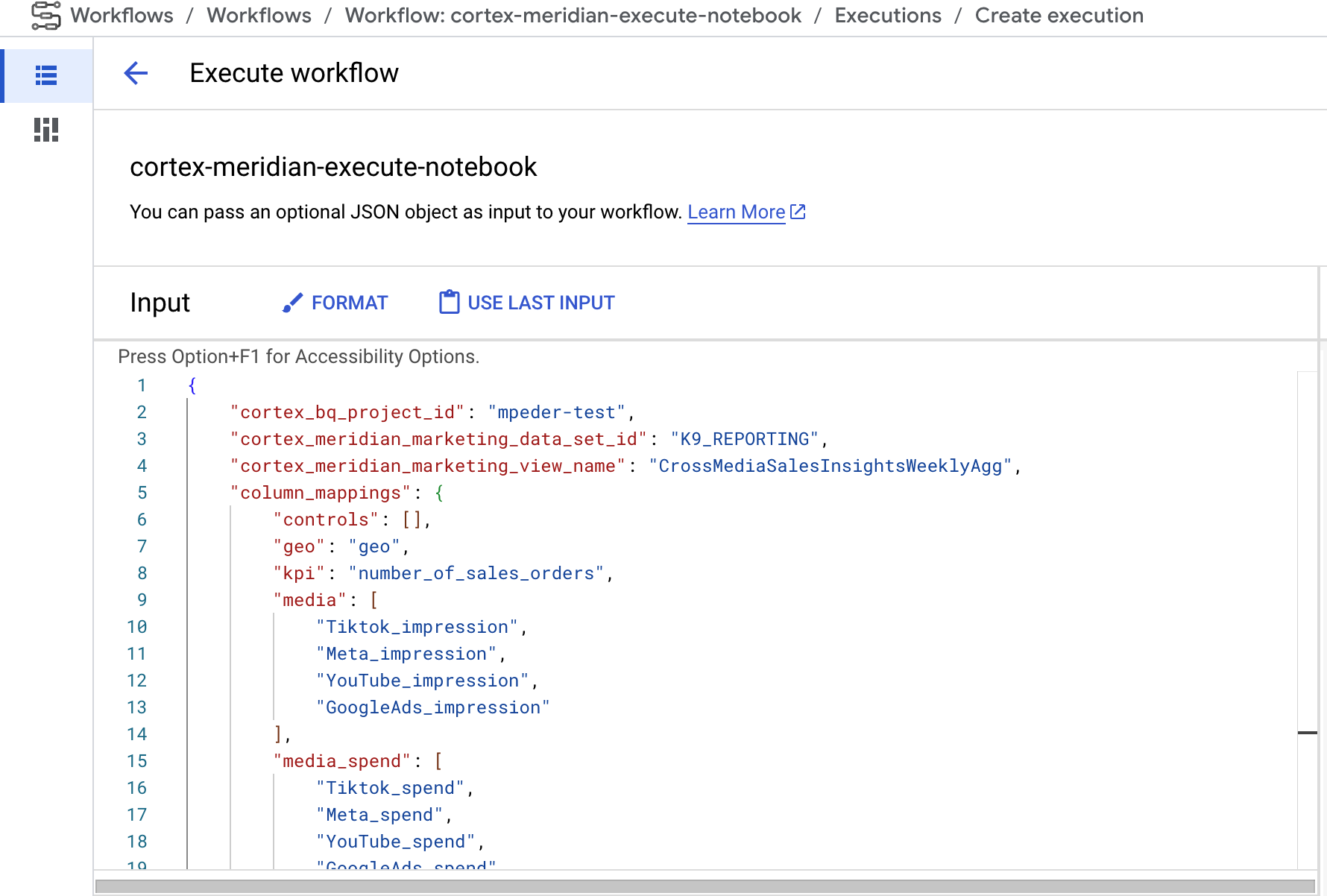
Figura 9. Exemplo de modificação e execução de um novo JSON de entrada. - O passo
pre_notebook_executionoferece um excelente ponto de partida para iniciar quaisquer tarefas adicionais que precise de automatizar antes de executar o bloco de notas. Por exemplo, carregar dados de origens externas ao Google Cloud Cortex Framework.
Conta de serviço: tem de ser fornecida uma conta de serviço dedicada durante a implementação. Isto é necessário para executar o fluxo de trabalho e o bloco de notas no Colab Enterprise.
Parâmetros de implementação adicionais para o Meridian
O ficheiro config.json configura as definições necessárias para executar o Meridian com a
Cortex Framework. Este ficheiro contém os seguintes parâmetros para o
Cortex for Meridian:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
A tabela seguinte descreve o valor e a descrição de cada parâmetro do Meridian:
| Parâmetro | Significado | Valor predefinido | Descrição |
k9.deployMeridian
|
Implementar o Meridian ou não. | false
|
Escolhe se quer ou não implementar o Cortex para o Meridian como parte de uma implementação da Data Foundation. |
k9.Meridian.salesDataSourceType
|
A origem dos dados de vendas. | - | Escolha entre BYOD, SAP ou OracleEBS
|
k9.Meridian.salesDatasetID
|
O ID do conjunto de dados de vendas. | - | O ID do conjunto de dados de vendas. Varia consoante a configuração da Cortex Data Foundation relacionada. |
k9.Meridian.deploymentType
|
Define se a implementação é limpa ou incremental. | - | Escolha entre initial e incremental.
|
k9.Meridian.defaultNotebookFile
|
Ficheiro de bloco de notas do Jupyter. | meridian_cortex_marketing.ipynb
|
O nome do ficheiro de bloco de notas localizado na pasta notebooks no Cloud Storage.
|
k9.Meridian.defaultConfigFile
|
O ficheiro de configuração para executar o bloco de notas. | cortex_meridian_config.json
|
Contém o Cortex para a configuração do Meridian usado quando o bloco de notas é executado.
Tem de estar localizado na pasta configuration no Cloud Storage.
|
k9.Meridian.gcsBucketNameSuffix
|
O sufixo do contentor do Cortex para o Meridian Cloud Storage. | cortex-meridian
|
O nome completo do contentor é {PROJECT_ID}-cortex-meridian por predefinição. |
k9.Meridian.workflow.template
|
O modelo do fluxo de trabalho. | create_notebook_execution_run.yaml
|
O modelo para criar o fluxo de trabalho. O fluxo de trabalho é usado para iniciar uma execução do bloco de notas. |
k9.Meridian.workflow.name
|
O nome do fluxo de trabalho. | cortex-meridian-execute-notebook
|
O nome apresentado no Google Cloud portal para o fluxo de trabalho. |
k9.Meridian.workflow.region
|
A região de implementação do fluxo de trabalho. | us-central1
|
A região de implementação do fluxo de trabalho. Normalmente, escolhe o mesmo que o resto da sua implementação. |
k9.Meridian.runnerServiceAccount
|
O nome da conta de serviço do Cortex para o Meridian. | cortex-meridian-colab-runner
|
O nome da conta de serviço usada para executar o fluxo de trabalho e as execuções do Colab Enterprise. |
k9.Meridian.colabEnterprise.region
|
A região de implementação das execuções do Colab Enterprise. | us-central1
|
A região de implementação das execuções do Colab Enterprise. Normalmente, escolhe a mesma opção que o resto da sua implementação. |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
Nome do modelo de ambiente de execução do Colab Enterprise. | cortex-meridian-template
|
Nome do modelo de ambiente de execução do Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
Tipo de máquina para o ambiente de execução do bloco de notas do Colab Enterprise. | n1-highmem-32
|
Tipo de máquina para o ambiente de execução do bloco de notas do Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
Número de núcleos. | 1
|
Número de núcleos do acelerador de GPU para o tempo de execução do bloco de notas do Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
Tipo de acelerador para o tempo de execução do bloco de notas do Colab Enterprise. | NVIDIA_TESLA_T4
|
O tipo de GPU. |
k9.Meridian.colabEnterprise.executionName
|
Nome da execução para o tempo de execução do bloco de notas do Colab Enterprise. | cortex-meridian-execution
|
O nome que é apresentado na interface Web do Colab Enterprise – Execuções. |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
Nome da pasta para as execuções de tempo de execução. | notebook-run-logs
|
As execuções do bloco de notas do Colab armazenam registos e cópias de execução do bloco de notas aqui. |
Fluxo de trabalho
Os fluxos de trabalho servem como a interface principal para iniciar as execuções do Cortex for Meridian. Um fluxo de trabalho predefinido denominado cortex-meridian-execute-notebook
é implementado como parte do Cortex para o Meridian.
Execução de notebooks
Para iniciar uma nova execução do Cortex for Meridian, siga estes passos:
- Aceda ao
cortex-meridian-execute-notebooknotebook no Workflows. - Clique em Executar para iniciar uma nova execução.
- Para execuções iniciais, deixe o campo de entrada vazio para usar a configuração predefinida
armazenada no
cortex_meridian_config.jsonficheiro de configuração no Cloud Storage. - Clique novamente em Executar para continuar.
Após um breve atraso, é apresentado o estado de execução do fluxo de trabalho:
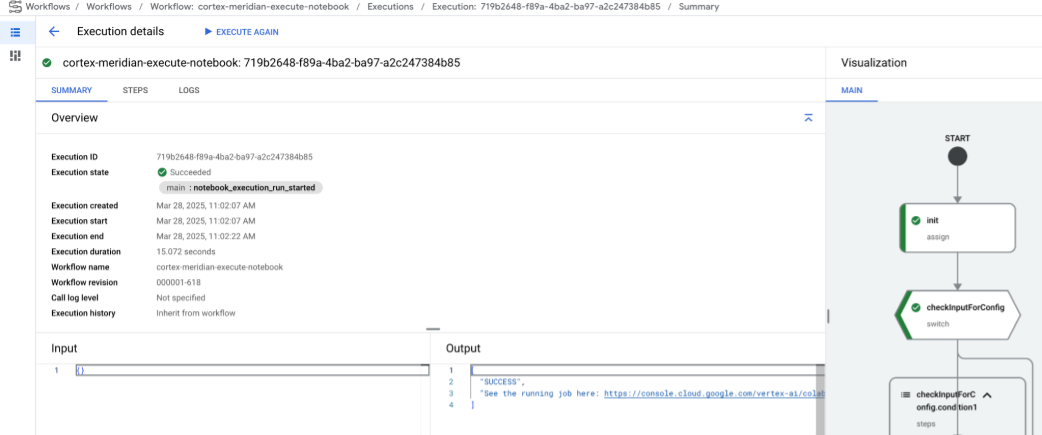
Figura 10. Exemplo de detalhes da execução. Acompanhe o progresso da execução do bloco de notas no Colab Enterprise.
Passos do fluxo de trabalho
O fluxo de trabalho cortex-meridian-execute-notebook contém os seguintes passos:
| Step | Sub-step | Descrição |
init
|
-
|
Inicialize os parâmetros. |
checkInputForConfig
|
-
|
Verifique se foi fornecido um novo ficheiro JSON de configuração como entrada do fluxo de trabalho. |
logBackupConfigFileName
|
Regista o nome do ficheiro de configuração da cópia de segurança. | |
backupConfigFile
|
Faz uma cópia de segurança do ficheiro de configuração no Cloud Storage. | |
logBackupResult
|
Regista o resultado da chamada da API Cloud Storage. | |
updateGCSConfigFile
|
Atualize o ficheiro de configuração no Cloud Storage com os novos valores. | |
pre_notebook_execution
|
-
|
Por predefinição, este passo está vazio. Está disponível para personalização. Por exemplo, o carregamento de dados ou outros passos relevantes antes de executar o bloco de notas. Para mais informações, consulte a Vista geral dos fluxos de trabalho e os conetores de fluxos de trabalho. |
create_notebook_execution_run
|
-
|
Crie a execução do bloco de notas do Colab Enterprise (através de um script de shell no Cloud Build). |
notebook_execution_run_started
|
-
|
Produz o resultado da conclusão. |
Personalize o fluxo de trabalho de execução do Meridian
Pode personalizar a execução do Meridian fornecendo o seu próprio ficheiro JSON de configuração no campo de entrada dos fluxos de trabalho:
- Introduza o JSON completo da configuração modificada no campo de entrada.
- O fluxo de trabalho vai:
- Substitua o ficheiro
cortex_meridian_config.jsonexistente no armazenamento na nuvem pelo JSON fornecido. - Crie uma cópia de segurança do ficheiro de configuração original no diretório
Cloud Storage/configuration. - O nome do ficheiro de cópia de segurança segue o formato
cortex_meridian_config_workflow_backup_workflow_execution_id.json, em que workflow_execution_id é um identificador exclusivo para a execução do fluxo de trabalho atual (por exemplo,cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json)
- Substitua o ficheiro
Vista geral do Jupyter Notebook
A funcionalidade principal de carregar dados de entrada para executar o modelo Meridian
é processada pelo bloco de notas Python meridian_cortex_marketing.ipynb,
localizado na pasta notebooks do seu contentor do Cloud Storage.
O fluxo de execução do bloco de notas é composto pelos seguintes passos:
- Instala os pacotes necessários (incluindo o Meridian) e importa as bibliotecas necessárias.
- Carregue funções auxiliares para interagir com o Cloud Storage e o BigQuery.
- Obtém a configuração de execução do ficheiro
configuration/cortex_meridian_config.jsonno Cloud Storage. - Carregue dados do Cortex Framework a partir da vista Cortex Framework Data Foundation no BigQuery.
- Configure a especificação do modelo Meridian e mapeie os modelos de dados da base de dados do Cortex Framework para marketing e vendas para o esquema de entrada do modelo Meridian.
- Executa a amostragem do Meridian e gera um relatório de resumo, guardado no
Cloud Storage (
/reporting). - Execute o otimizador de orçamento para o cenário predefinido e gere o relatório de resumo para o
Cloud Storage (
/reporting). - Guardar o modelo no Cloud Storage (
/models). - Guarde os resultados CSV no Cloud Storage (
/csv). - Gere um relatório de vista geral e guarde-o no Cloud Storage (
/reporting).
Importe o bloco de notas para execução e edição manuais
Para personalizar ou executar manualmente o bloco de notas, importe-o do Cloud Storage:
- Aceda ao Colab Enterprise.
- Clique em Os meus blocos de notas.
- Clique em Importar.
- Selecione Cloud Storage como origem da importação e selecione o notebook no Cloud Storage.
- Clique em Importar.
O bloco de notas é carregado e aberto.
Resultados das execuções de blocos de notas
Para rever os resultados da execução do bloco de notas, abra uma cópia completa do bloco de notas com todos os resultados das células:
- Aceda a Execuções no Colab Enterprise.
- Selecione a região relevante no menu pendente.
- Junto à execução do bloco de notas para a qual quer ver os resultados, clique em Ver resultado.
- O Colab Enterprise abre o resultado da execução do bloco de notas num novo separador.
- Para ver o resultado, clique no novo separador.
Modelo do ambiente de execução
Google Cloud O Colab Enterprise usa modelos de tempo de execução para definir ambientes de execução pré-configurados. É incluído um modelo de tempo de execução predefinido, adequado para executar o bloco de notas Meridian, com a implementação do Cortex for Meridian. Este modelo é usado automaticamente para criar ambientes de tempo de execução para execuções de blocos de notas.
Se necessário, pode criar manualmente modelos de tempo de execução adicionais.