當要最佳化應用程式的效能時,請考慮使用 NDB。 舉例來說,如果應用程式讀取的值不在快取中,讀取作業就會耗費一段時間。您或許可以與其他作業並行執行 Datastore 動作,或並行執行幾個 Datastore 動作,藉此加快應用程式速度。
NDB 用戶端程式庫提供許多非同步 (「async」) 函式。應用程式可透過這些函式向 Datastore 傳送要求。函式會立即傳回內容,並傳回一個 Future 物件。應用程式可以在 Datastore 處理要求時執行其他工作。Datastore 處理要求後,應用程式即可從 Future 物件取得結果。
簡介
假設應用程式的其中一個要求處理常式需要使用 NDB 寫入內容 (例如記錄要求),此外,它還需要執行一些其他 NDB 作業,可能需要擷取某些資料。
將 put() 的呼叫替換為其非同步對等項目 put_async() 的呼叫後,應用程式可以立即執行其他作業,而不必等待 put() 封鎖。
這能讓 Datasore 在寫入資料時,顯示其他 NBD 函式以及範本。應用程式不會在從 Datastore 取得資料前封鎖 Datastore。
在這個範例中,呼叫 future.get_result 有點愚蠢,因為應用程式從未使用 NDB 的結果。這段程式碼只是為了確保要求處理常式不會在 NDB put 完成前結束;如果要求處理常式太早結束,可能永遠不會發生放置作業。為方便起見,您可以使用 @ndb.toplevel 裝飾要求處理常式。這告訴處理常式在完成非同步要求之前不要退出。這樣一來,您就能傳送要求,不必擔心結果。
您可以指定整個 WSGIApplication 做為 ndb.toplevel。這樣可確保每個 WSGIApplication 的處理常式都會等待所有非同步要求,然後再傳回。(不會「頂層」所有 WSGIApplication 的處理常式)。
使用 toplevel 應用程式比使用所有處理常式函式更方便。但如果處理常式方法使用 yield,該方法仍須包裝在另一個裝飾器 @ndb.synctasklet 中;否則,執行作業會在 yield 停止,不會完成。
使用非同步 API 及 Future
幾乎每個同步 NDB 函式都有對應的 _async 函式。例如:put() 有 put_async()。非同步函式的引數一律與同步版本相同。
非同步方法的傳回值一律為 Future,或是 (針對「multi」函式) Future 清單。
「Future」是一個物件,用來維持已啟動但尚未完成的作業狀態。所有非同步 API 都會傳回一或多個 Futures。
您可以呼叫 Future 的 get_result() 函式,要求提供作業結果。如有必要,Future 會封鎖,直到結果可用為止,然後將結果提供給您。get_result() 會傳回 API 同步版本所傳回的值。
附註:
若您在其他程式語言使用過 Future,您可能會認為您可以直接使用 Future 做為結果,這項功能不適用於此。
這些語言使用
隱含的 Future,NDB 則使用明確的 Future。呼叫 get_result() 取得 NDB Future 的結果。
如果作業引發例外狀況怎麼辦?這取決於例外狀況發生的時間。如果 NDB 在「發出」要求時發現問題 (可能是引數類型錯誤),則 _async() 方法會引發例外狀況。但如果例外狀況是由 Datastore 伺服器偵測到,_async() 方法會傳回 Future,而應用程式呼叫 get_result() 時,就會引發例外狀況。請別太擔心,這一切最終都會以相當自然的方式運作;或許最大的差異在於,如果列印回溯,您會看到一些低階非同步機制曝光。
舉例來說,假設您正在編寫留言簿應用程式。如果使用者已登入,您想顯示的頁面應包含最新的留言簿貼文。此頁面應該亦要向使用者顯示他們的暱稱。應用程式需要兩種資訊:已登入使用者的帳戶資訊,以及留言板所發布的內容。此應用程式的「同步」版本可能如下所示:
這裡有兩個獨立的 I/O 動作:取得 Account 實體和擷取近期 Guestbook 實體。使用同步 API 的話,這些將接連發生,我們在擷取留言板實體之前,等待收到帳戶資訊。但是應用程式不需要立即取得帳戶資訊。我們可以利用這一點並使用非同步 API:
這個版本的程式碼會先建立兩個 Futures (acct_future 和 recent_entries_future),然後等待這兩個物件。伺服器會並行處理這兩項要求。
每次呼叫 _async() 函式都會建立 Future 物件,並將要求傳送至 Datastore 伺服器。伺服器可以立即開始處理要求。伺服器回應可能會以任意順序傳回;Future 物件會將回應連結至對應的要求。
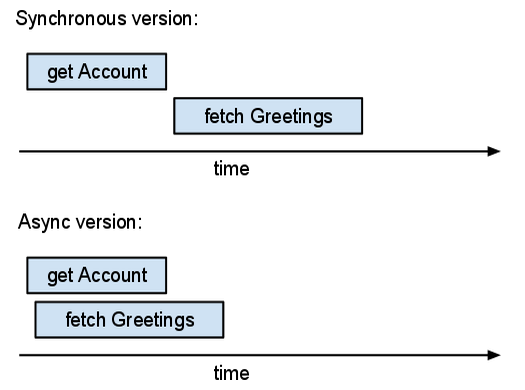
在非同步版本中所花費的總時間大約等於作業的最大時間。同步版本所花費的總時間超過作業時間總和。如果可以平行執行更多作業,非同步作業就更有幫助。
如要瞭解應用程式的查詢時間長度,或每個要求執行的 I/O 作業數量,請考慮使用 Appstats。 這個工具可根據即時應用程式的插樁,顯示類似上圖的圖表。
使用 Tasklet
NDB 的 tasklet 是一小段程式碼,可能與其他程式碼一同執行。如果您編寫 tasklet,應用程式就能像使用非同步 NDB 函式一樣使用 tasklet:呼叫 tasklet,後者會傳回 Future;稍後呼叫 Future 的 get_result() 方法即可取得結果。
tasklet 是一種可在沒有執行緒的情況下編寫並行函式的方法,由事件迴圈執行,且可以使用 yield 陳述式暫停自身,以封鎖 I/O 或其他作業。封鎖作業的概念會抽象化為 Future 類別,但 tasklet 也可能會 yield RPC,以便等待該 RPC 完成。當 tasklet 產生結果時,會 raise 一個 ndb.Return 例外狀況;接著 NDB 會將結果與過去 yielded 的 Future 建立關聯。
編寫 NDB tasklet 時,您會以不尋常的方式使用 yield 和 raise。因此,如果您尋找如何使用這些項目的範例,可能找不到類似 NDB tasklet 的程式碼。
若要將函式轉換成 NBD tasklet:
- 使用
@ndb.tasklet裝飾函式, - 將所有同步資料儲存庫呼叫替換為非同步資料儲存庫呼叫的
yields, - 使函式「傳回」其傳回值
raise ndb.Return(retval)(函式未傳回任何內容時則不需要)。
應用程式可以使用 tasklet 以更精細地控制非同步 API。例如,不妨考慮以下結構定義:
...
顯示訊息時,顯示作者的暱稱是合理的做法。 「同步」擷取資料以顯示訊息清單的方式可能如下所示:
不過這種方法的效率很低。若您在 Appstats 中查看,您會看到一連串的「Get」要求。您可能會看到下列「階梯」模式。
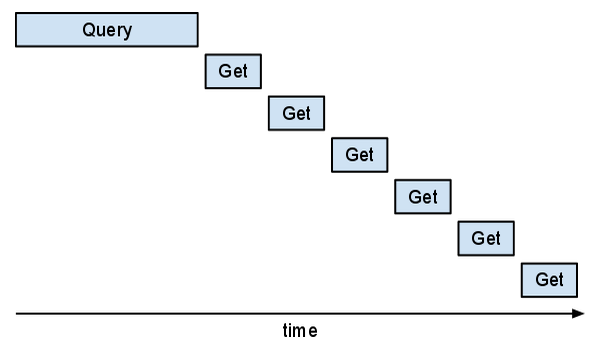 同步「取得」作業會依序進行。
同步「取得」作業會依序進行。如果這些「Gets」可以重疊,程式的這部分就會更快。
您可以重寫程式碼來使用 get_async,但要追蹤哪些非同步要求和訊息屬於同一組,會比較棘手。
應用程式能夠將其做為 tasklet 來定義自己的「非同步」函式。 可讓您以較不易混淆的方式整理這些程式碼。
此外,函式應使用 acct = yield key.get_async(),而非 acct = key.get() 或 acct = key.get_async().get_result()。此 yield 會告訴 NDB 這是停用 tasklet 且讓其他 tasklet 執行的好時機。
使用 @ndb.tasklet 裝飾產生器函式,可讓函式傳回 Future,而非產生器物件。在 tasklet 中,任何 yield 的 Future 都會等待並傳回 Future 的結果。
例如:
請注意,雖然 get_async() 會傳回 Future,但 tasklet 架構會導致 yield 運算式將 Future 的結果傳回給變數 acct。
map() 會多次呼叫 callback()。
但 callback() 中的 yield ..._async() 可讓 NDB 的排程器傳送多個非同步要求,然後等待其中任何一個要求完成。
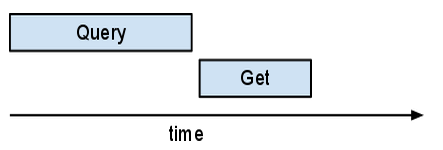
如果您在 Appstats 中查看這項資訊,可能會驚訝地發現這些多個 Get 不僅重疊,而且全都透過同一個要求傳送。NDB 實作了「自動批次處理器」。自動批次處理器會將多個要求捆綁在單一批次 RPC 中傳送至伺服器;只要還有工作要做 (可能會執行另一個回呼),就會收集鍵。只要需要其中一個結果,自動批次處理器就會傳送批次 RPC。與大多數要求不同,查詢不會「批次處理」。
當一個 tasklet 執行時,會從 tasklet 生成時的任何預設內容,或在執行過程 tasklet 更改的任何內容中,取得其預設的命名空間。換句話說,預設的命名空間不會與 context 關聯,亦不會儲存在 Context 中,且更改一個 tasklet 中的預設命名空間不會影響其他 tasklet 中的預設命名空間,除非是由 context 所生成。
Tasklet、並行查詢、並行 yield
您可以使用工作小程式,讓多個查詢同時擷取記錄。 舉例來說,假設您的應用程式有一個頁面,會顯示購物車內容和特惠清單。結構定義可能如下所示:
擷取購物車項目以及特別優惠的「同步」函式可能如下所示:
這個範例會使用查詢擷取購物車項目和優惠清單,然後使用 get_multi() 擷取目錄項目的詳細資料。(這個函式不會直接使用 get_multi() 的傳回值。(這會呼叫 get_multi(),將所有目錄詳細資料擷取到快取中,以便稍後快速讀取。)get_multi
將多個 Get 合併為一個要求。但查詢擷取作業會依序執行。為了要讓這些擷取同時發生,請重疊兩個查詢:
get_multi() 呼叫仍是獨立的:這取決於查詢結果,因此無法與查詢合併。
假設此應用程式有時需要購物車,有時需要優惠,有時兩者皆需。您需要要整理您的程式碼,以做成能取得購物車的函式以及取得優惠的函式。如果應用程式同時呼叫這些函式,理想情況下,這些函式的查詢可能會「重疊」。如要這麼做,請將這些函式設為 Tasklet:
yield x, y 很重要,但卻容易受到忽視。如果是兩個獨立的 yield 陳述式,則這兩個陳述式會一連串地發生。但是對一個 tasklet 組合進行 yield 屬於「並行 yield」:tasklet 可並行執行,且 yield 會等待所有內容完成並傳回結果 (在一些程式語言中,會稱為「障礙 (barrier)」)。
若您將一小段程式碼轉換為一個 tasklet,您可能希望盡快繼續轉換。如果您發現「同步」程式碼可以與 Tasklet 平行執行,最好也將其設為 Tasklet。然後,您可以使用平行 yield 將其平行化。
若您編寫一個要求函式 (webapp2要求函式、Django 查看函式等) 做為 tasklet,其作業並不會符合您的預期:tasklet 會在 yield 後即停止執行。在這種情況下,您要使用 @ndb.synctasklet 裝飾函式。@ndb.synctasklet 類似於 @ndb.tasklet,但經過修改,會在 tasklet 上呼叫 get_result()。這會將工作單元轉換為函式,並以一般方式傳回結果。
在 tasklet 中查詢迭代
若要在 tasklet 中迭代查詢結果,請使用以下模式:
此與以下內容相等且適用 tasklet:
第一個版本中的三行粗體文字,相當於第二個版本中的一行粗體文字,且都適用於 Tasklet。工作小程式只能在 yield 關鍵字暫停。
yield-less for 迴圈不會讓其他 tasklet 執行。
您可能會想知道,為什麼這段程式碼要使用查詢疊代器,而不是使用 qry.fetch_async() 擷取所有實體。應用程式可能含有大量實體,導致 RAM 無法容納。您可能正在尋找實體,找到後即可停止疊代;但您無法只使用查詢語言表達搜尋條件。您可能會使用疊代器載入要檢查的實體,然後在找到所需內容時跳出迴圈。
使用 NDB 進行非同步的 Urlfetch
NDB Context 具有非同步的 urlfetch() 函式,能與 NBD 的 tasklet 順暢地平行處理,例如:
網址擷取服務有自己的 非同步要求 API。這項功能沒問題,但並非一律都能輕鬆搭配 NDB 工作單元使用。
使用非同步交易
交易亦可以同步執行。您可以將現有函式傳遞至 ndb.transaction_async(),或使用 @ndb.transactional_async 裝飾器。與其他非同步函式一樣,這個函式會傳回 NDB Future:
交易也可與 tasklet 一起執行。舉例來說,我們可以將 update_counter 程式碼變更為 yield,同時等待封鎖 RPC:
使用 Future.wait_any()
有時您想發出多個非同步要求,並在第一個要求完成時傳回。您可以使用 ndb.Future.wait_any() 類別方法執行此操作:
不過,您無法輕鬆地將上述程式碼轉換為 tasklet;平行 yield 會等待所有 Future 完成,包含那些您不想等待的。