適用於裸機的 Google Distributed Cloud (僅限軟體) 支援多種叢集記錄和監控選項,包括雲端代管服務、開放原始碼工具,以及通過驗證的第三方商業解決方案相容性。本頁面將說明這些選項,並提供基本指南,協助您為環境選取合適的解決方案。
本頁面適用於想監控已部署應用程式或服務健康狀態的管理員、架構師和營運人員,例如服務水準目標 (SLO) 遵循情形。如要進一步瞭解內容中提及的常見角色和範例工作,請參閱「常見的 GKE 使用者角色和工作」。 Google Cloud
Google Distributed Cloud 選項
您可以透過下列幾種方式記錄及監控叢集:
- Cloud Logging 和 Cloud Monitoring,預設會在裸機系統元件上啟用。
- 您可以透過 Cloud Marketplace 取得 Prometheus 和 Grafana。
- 已驗證的第三方解決方案設定。
Cloud Logging 和 Cloud Monitoring
Google Cloud Observability 是Google Cloud的內建觀測解決方案。提供全代管記錄解決方案、指標收集、監控、資訊主頁和快訊功能。Cloud Monitoring 監控 Google Distributed Cloud 叢集的方式,與監控雲端 GKE 叢集類似。
使用必要的服務帳戶和 Identity and Access Management (IAM) 角色建立叢集時,系統預設會啟用 Cloud Logging 和 Cloud Monitoring。您無法停用 Cloud Logging 和 Cloud Monitoring。如要進一步瞭解服務帳戶和必要角色,請參閱「設定服務帳戶」。
您可以設定代理程式變更下列項目:
- 記錄和監控範圍,從僅限系統元件 (預設) 到系統元件和應用程式。
- 收集的指標層級,從僅限最佳化指標組合 (預設) 到所有指標。
詳情請參閱本文的「為 Google Distributed Cloud 設定 Stackdriver 代理程式」一節。
Logging 和 Monitoring 提供單一雲端式觀測解決方案,設定簡便且功能強大。在 Google Distributed Cloud 上執行工作負載時,我們強烈建議使用 Logging 和 Monitoring。如果應用程式的元件在 Google Distributed Cloud 和標準內部部署基礎架構上執行,建議您考慮使用其他解決方案,取得這些應用程式的端對端檢視畫面。
如要進一步瞭解架構、設定,以及預設會複製到 Google Cloud 專案的資料,請參閱「Google Distributed Cloud 的記錄和監控功能運作方式」。
如要進一步瞭解 Cloud Logging,請參閱 Cloud Logging 說明文件。
如要進一步瞭解 Monitoring,請參閱 Cloud Monitoring 說明文件。
如要瞭解如何查看及使用 Google Distributed Cloud 的 Cloud Monitoring 資源用量指標 (以機群層級為準),請參閱「使用 Google Kubernetes Engine 總覽」。
Prometheus 和 Grafana
Prometheus 和 Grafana 是兩項熱門的開放原始碼監控產品,可透過 Cloud Marketplace 取得:
Prometheus 會收集應用程式和系統指標。
Alertmanager 會透過多種不同的警示機制傳送警示。
Grafana 是儀表板工具。
建議您使用以 Cloud Monitoring 為基礎的 Google Cloud Managed Service for Prometheus,滿足所有監控需求。使用 Google Cloud Managed Service for Prometheus 時,您可以免費監控系統元件。Google Cloud Managed Service for Prometheus 也與 Grafana 相容。不過,如果您偏好純粹的本機監控系統,也可以選擇在叢集中安裝 Prometheus 和 Grafana。
如果您在本機安裝 Prometheus,並想從系統元件收集指標,就必須授予本機 Prometheus 執行個體權限,才能存取系統元件的指標端點:
將 Prometheus 執行個體的服務帳戶繫結至預先定義的
gke-metrics-agentClusterRole,並使用服務帳戶權杖做為憑證,從下列系統元件抓取指標:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
使用儲存在
kube-system/stackdriver-prometheus-etcd-scrape密鑰中的用戶端金鑰和憑證,驗證來自 etcd 的指標擷取作業。建立 NetworkPolicy,允許從命名空間存取 kube-state-metrics。
第三方解決方案
Google 與多家第三方記錄和監控解決方案供應商合作,確保他們的產品能與 Google Distributed Cloud 順暢搭配使用。包括 Datadog、Elastic 和 Splunk。日後會新增更多經過驗證的第三方。
如要搭配使用第三方解決方案與 Google Distributed Cloud,請參閱下列解決方案指南:
Google Distributed Cloud 的記錄與監控功能運作方式
建立新的管理員或使用者叢集時,系統會在每個叢集中安裝並啟用 Cloud Logging 和 Cloud Monitoring。
Stackdriver 代理程式在每個叢集上包含下列元件:
Stackdriver 運算子 (
stackdriver-operator-*):管理部署至叢集的所有其他 Stackdriver 代理程式生命週期。Stackdriver 自訂資源。系統會在 Google Distributed Cloud 安裝程序中自動建立的資源。
GKE 指標代理程式 (
gke-metrics-agent-*):以 OpenTelemetry 收集器為基礎的 DaemonSet,可從每個節點擷取指標至 Cloud Monitoring。此外,系統也會納入node-exporterDaemonSet 和kube-state-metrics部署作業,提供更多叢集指標。Stackdriver Log Forwarder (
stackdriver-log-forwarder-*):Fluent Bit DaemonSet,可將每部機器的記錄轉送至 Cloud Logging。記錄轉送器會在節點上緩衝處理記錄項目,並在最多 4 小時內重新傳送。如果緩衝區已滿,或記錄轉送器無法連上 Cloud Logging API 超過 4 小時,系統就會捨棄記錄。中繼資料代理程式 (
stackdriver-metadata-agent-):部署作業,可將 Kubernetes 資源 (例如 Pod、部署作業或節點) 的中繼資料傳送至作業設定監控 API。新增中繼資料後,您就能依部署名稱、節點名稱,甚至是 Kubernetes 服務名稱查詢指標資料。
如要查看 Stackdriver 安裝的代理程式,請執行下列指令:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
這個指令會輸出類似以下的結果:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Cloud Monitoring 指標
如需 Cloud Monitoring 收集的指標清單,請參閱「查看 Google Distributed Cloud 指標」。
為 Google Distributed Cloud 設定 Stackdriver 代理程式
Google Distributed Cloud 安裝的 Stackdriver 代理程式會收集系統元件的資料,以維護叢集並排解相關問題。以下各節說明 Stackdriver 設定和運作模式。
僅限系統元件 (預設模式)
安裝後,Stackdriver 代理程式預設會收集記錄和指標,包括 Google 提供的系統元件效能詳細資料 (例如 CPU 和記憶體使用率) 和類似的中繼資料。包括管理員叢集中的所有工作負載,以及使用者叢集中的 kube-system、gke-system、gke-connect、istio-system 和 config-management-system 命名空間中的工作負載。
系統元件和應用程式
如要在預設模式中啟用應用程式記錄和監控功能,請按照「啟用應用程式記錄與監控功能」一文的步驟操作。
最佳化指標 (預設指標)
根據預設,叢集中執行的 kube-state-metrics 部署作業會收集一組經過最佳化的 Kube 指標,並回報給 Google Cloud Observability (原稱 Stackdriver)。
收集這組最佳化指標所需的資源較少,可提升整體效能和延展性。
如要停用最佳化指標 (不建議),請在 Stackdriver 自訂資源中覆寫預設設定。
針對所選系統元件使用 Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus 是 Cloud Monitoring 的一部分,可做為系統元件的選項。Google Cloud Managed Service for Prometheus 的優點包括:
您可以繼續使用現有的 Prometheus 型監控功能,無須變更快訊和 Grafana 資訊主頁。
如果您同時使用 GKE 和 Google Distributed Cloud,可以對所有叢集的指標使用相同的 Prometheus 查詢語言 (PromQL)。您也可以在 Google Cloud 控制台的指標探索工具中,使用 PromQL 分頁。
啟用及停用 Google Cloud Managed Service for Prometheus
從 Google Distributed Cloud 1.30.0-gke.1930 版開始,Google Cloud Managed Service for Prometheus 一律會啟用。在舊版中,您可以編輯 Stackdriver 資源 stackdriver,啟用或停用 Google Cloud Managed Service for Prometheus。如要為 1.30.0-gke.1930 之前的叢集版本停用 Google Cloud Managed Service for Prometheus,請在 stackdriver 資源中將 spec.featureGates.enableGMPForSystemMetrics 設為 false。
查看指標資料
如果將 enableGMPForSystemMetrics 設為 true,下列元件的指標在 Cloud Monitoring 中的儲存和查詢格式會有所不同:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet 和 cadvisor
- kube-state-metrics
- node-exporter
在新格式中,您可以使用 Prometheus 查詢語言 (PromQL) 查詢上述指標。
PromQL 查詢範例:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
使用 Google Cloud Managed Service for Prometheus 設定 Grafana 資訊主頁
如要搭配使用 Grafana 和 Google Cloud Managed Service for Prometheus 的指標資料,您必須先設定 Grafana 資料來源並完成驗證。如要設定及驗證資料來源,請使用資料來源同步器 (datasource-syncer) 產生 OAuth2 憑證,並透過 Grafana 資料來源 API 將憑證同步到 Grafana。資料來源同步器會在 Grafana 的資料來源中,將 Cloud Monitoring API 設為 Prometheus 伺服器網址 (網址值開頭為 https://monitoring.googleapis.com)。
請按照「使用 Grafana 查詢」一文中的步驟,驗證及設定 Grafana 資料來源,以便查詢 Google Cloud Managed Service for Prometheus 的資料。
GitHub 上的 anthos-samples 存放區提供一組 Grafana 資訊主頁範例。如要安裝範本資訊主頁,請按照下列步驟操作:
下載 JSON 範例檔案:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
如果建立 Grafana 資料來源時使用的名稱不是
Managed Service for Prometheus,請變更所有 JSON 檔案中的datasource欄位:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
將 [DATASOURCE_NAME] 替換為 Grafana 中指向 Prometheus
frontend服務的資料來源名稱。在瀏覽器中存取 Grafana UI,然後選取「資訊主頁」選單下方的「+ 匯入」。

上傳 JSON 檔案,或複製並貼上檔案內容,然後選取「載入」。檔案內容載入完成後,請選取「匯入」。您也可以選擇在匯入前變更資訊主頁名稱和 UID。
如果 Google Distributed Cloud 和資料來源設定正確,匯入的資訊主頁應可順利載入。舉例來說,下圖顯示由
cluster-capacity.json設定的資訊主頁。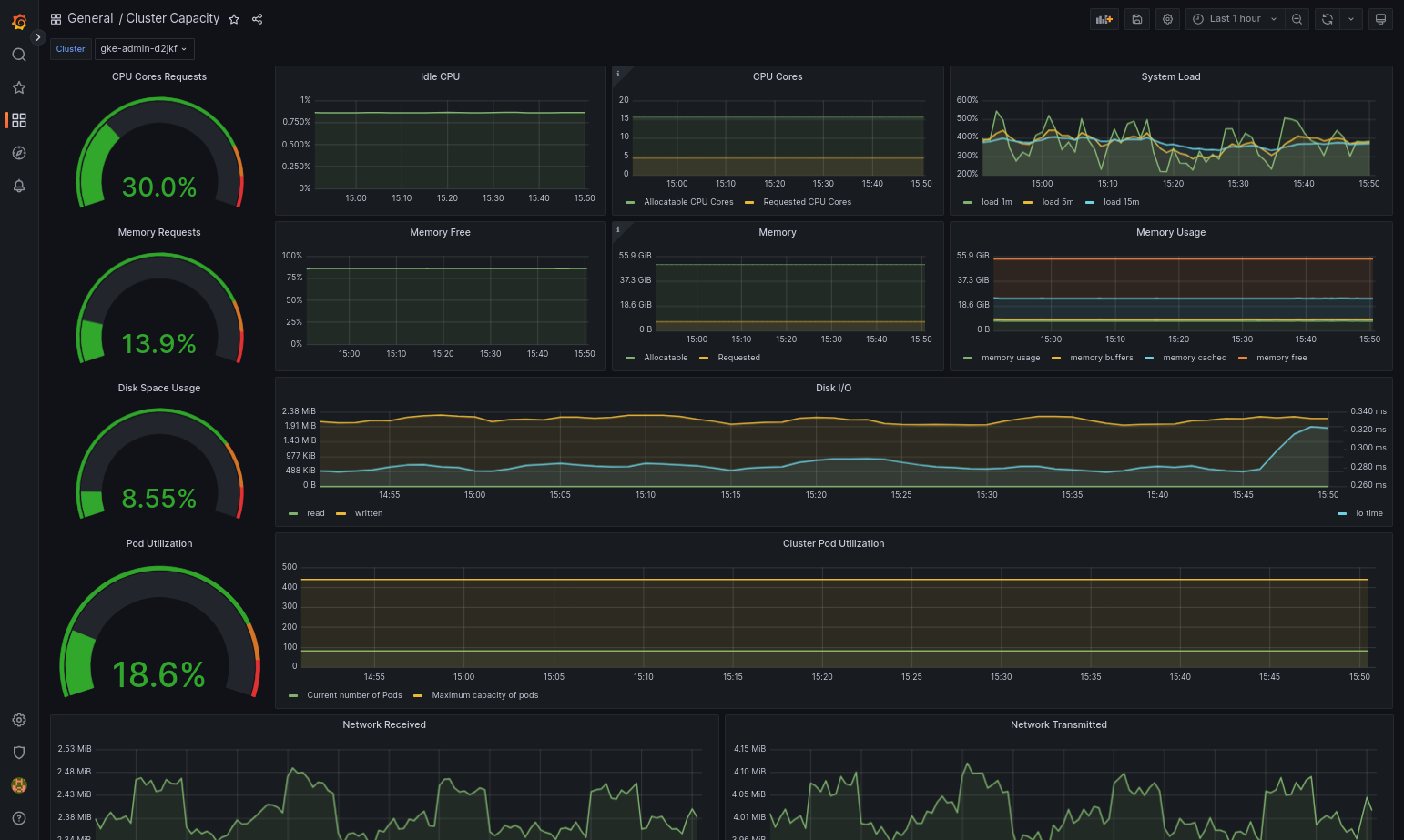
其他資源
如要進一步瞭解 Google Cloud Managed Service for Prometheus,請參閱下列文章:
設定 Stackdriver 元件資源
建立叢集時,Google Distributed Cloud 會自動建立 Stackdriver 自訂資源。您可以編輯自訂資源中的規格,覆寫 Stackdriver 元件的 CPU 和記憶體要求與限制預設值,也可以個別覆寫預設的最佳化指標設定。
覆寫 Stackdriver 元件的預設 CPU 和記憶體要求與限制
Pod 密度高的叢集會增加記錄和監控的負擔。在極端情況下,Stackdriver 元件可能會回報 CPU 和記憶體使用率接近上限,甚至可能因資源限制而持續重新啟動。在本例中,如要覆寫 Stackdriver 元件的 CPU 和記憶體要求與限制預設值,請按照下列步驟操作:
執行下列指令,在指令列編輯器中開啟 Stackdriver 自訂資源:
kubectl -n kube-system edit stackdriver stackdriver
在 Stackdriver 自訂資源中,於
spec欄位下方新增resourceAttrOverride區段:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITY請注意,
resourceAttrOverride區段會覆寫您指定元件的所有現有預設限制和要求。resourceAttrOverride支援下列元件:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
範例檔案如下所示:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5Gi如要儲存對 Stackdriver 自訂資源所做的變更,請儲存並結束命令列編輯器。
檢查 Pod 的健康狀態:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
健康狀態良好的 Pod 回應如下:
gke-metrics-agent-4th8r 1/1 Running 1 40h
檢查元件的 Pod 規格,確認資源設定正確無誤。
kubectl -n kube-system describe pod POD_NAME
將
POD_NAME替換為您剛變更的 Pod 名稱。例如:gke-metrics-agent-4th8r。回應如下所示:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
停用最佳化指標
根據預設,叢集中執行的 kube-state-metrics 部署作業會收集一組經過最佳化的 Kube 指標,並回報至 Stackdriver。如需其他指標,建議您從 Google Distributed Cloud 指標清單中尋找替代指標。
以下列舉幾個可用的替代字詞:
| 已停用的指標 | 更換 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
如要停用最佳化指標預設設定 (不建議),請執行下列操作:
在指令列編輯器中開啟 Stackdriver 自訂資源:
kubectl -n kube-system edit stackdriver stackdriver
將
optimizedMetrics欄位設為false:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
儲存變更,然後結束指令列編輯器。
指標伺服器
指標伺服器是各種自動調度資源管道的容器資源指標來源。指標伺服器會從 Kubelet 擷取指標,並透過 Kubernetes 指標 API 公開這些指標。水平 Pod 自動配置器和垂直 Pod 自動配置器會使用這些指標,判斷何時觸發自動調度資源。系統會使用外掛程式調整器調整指標伺服器。
在極端情況下,如果 Pod 密度過高,導致記錄和監控的負荷過大,Metrics Server 可能會因資源限制而停止並重新啟動。在這種情況下,您可以編輯 gke-managed-metrics-server 命名空間中的 metrics-server-config configmap,並變更 cpuPerNode 和 memoryPerNode 的值,將更多資源分配給指標伺服器。
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
ConfigMap 的內容範例如下:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
更新 ConfigMap 後,請使用下列指令重新建立指標伺服器 Pod:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
記錄檔和指標的路由
Stackdriver 記錄轉送程式 (stackdriver-log-forwarder) 會將每個節點機器的記錄傳送至 Cloud Logging。同樣地,GKE 指標代理程式 (gke-metrics-agent) 會將每個節點機器的指標傳送至 Cloud Monitoring。傳送記錄和指標前,Stackdriver 運算子 (stackdriver-operator) 會將 stackdriver 自訂資源中的 clusterLocation 欄位值附加至每個記錄項目和指標,然後再將這些項目和指標傳送至 Google Cloud。此外,記錄和指標會與自訂資源規格 (spec.projectID) 中指定的 Google Cloud 專案stackdriver建立關聯。
stackdriver 資源會從叢集資源的 clusterOperations 區段中,在叢集建立時取得 clusterLocation 和 projectID 欄位的值。projectIDlocation
Stackdriver 代理程式傳送的所有指標和記錄項目都會轉送至全域擷取端點。接著,資料會轉送至最近的可連線區域 Google Cloud 端點,確保資料傳輸的可靠性。
全域端點收到指標或記錄項目後,接下來的動作會因服務而異:
記錄檔轉送的設定方式:記錄端點收到記錄訊息時,Cloud Logging 會透過記錄檔路由器傳送訊息。記錄路由器設定中的接收器和篩選器會決定訊息的轉送方式。您可以將記錄項目轉送至目的地,例如儲存記錄項目的地區 Logging bucket,或是 Pub/Sub。如要進一步瞭解記錄檔路徑的運作方式和設定方法,請參閱「轉送和儲存空間總覽」的說明。
在此路由程序中,系統不會考量
stackdriver自訂資源中的clusterLocation欄位,也不會考量叢集規格中的clusterOperations.location欄位。對於記錄檔,clusterLocation僅用於標記記錄項目,有助於在記錄檔探索工具中進行篩選。指標路由設定方式:指標端點收到指標項目時,系統會自動將項目路由至指標指定的儲存位置。指標中的位置來自
stackdriver自訂資源中的clusterLocation欄位。規劃設定:設定 Cloud Logging 和 Cloud Monitoring 時,請設定記錄檔路由器,並指定適當的
clusterOperations.location和位置,盡可能滿足您的需求。舉例來說,如果希望記錄和指標前往相同位置,請將clusterOperations.location設為與 Log Router 用於 Google Cloud 專案的 Google Cloud 地區相同。視需要更新記錄設定:您可以隨時變更記錄的目的地設定,以因應業務需求,例如災害復原計畫。在Google Cloud 中變更記錄路由器設定後,變更會迅速生效。叢集資源的
clusterOperations區段中,location和projectID欄位是不可變更的,因此叢集建立後就無法更新。我們不建議您直接變更stackdriver資源中的值,每當叢集作業 (例如升級) 觸發協調程序時,這項資源就會還原為原始叢集建立狀態。
記錄與監控功能的設定規定
如要透過 Google Distributed Cloud 啟用 Cloud Logging 和 Cloud Monitoring,必須符合幾項設定需求。這些步驟包含在「啟用 Google 服務」頁面的「設定服務帳戶以搭配記錄和監控功能使用」一節,以及下列清單中:
- 您必須在Google Cloud 專案中建立 Cloud Monitoring 工作區。方法是在Google Cloud 控制台中點選「Monitoring」(監控),然後按照工作流程操作。
您必須啟用下列 Stackdriver API:
您必須將下列 IAM 角色指派給 Stackdriver 代理程式使用的服務帳戶:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
記錄標記
許多 Google Distributed Cloud 記錄檔都有 F 標記:
logtag: "F"
這個標記表示記錄項目完整或完整。如要進一步瞭解這個標記,請參閱 GitHub 上 Kubernetes 設計提案中的記錄格式。
定價
在 Google Distributed Cloud 叢集中,系統記錄檔和指標包括下列內容:
- 來自管理員叢集中所有元件的記錄檔和指標。
- 來自使用者叢集中這些命名空間元件的記錄檔和指標:
kube-system、gke-system、gke-connect、knative-serving、istio-system、monitoring-system、config-management-system、gatekeeper-system、cnrm-system。
詳情請參閱 Google Cloud Observability 定價。
如要瞭解 Cloud Logging 指標的抵免額,請與銷售人員聯絡以取得定價資訊。