Use cases
This reference architecture supports the following scenarios:
- You have databases that can tolerate some downtime and data loss since last backup.
- You want to protect your AlloyDB Omni database from user-error, corruption, or physical failures at the database level (as opposed to server or VM image snapshots).
- You want to be able to recover your database in-place or remotely, possibly up to a specific point in time.
How the reference architecture works
The Standard Availability reference architecture covers the backup and recovery of your AlloyDB Omni databases, whether they're running as a standalone instance on a host server, as a virtual machine (Install AlloyDB Omni), or in a Kubernetes cluster (Install AlloyDB Omni on Kubernetes).
While Standard Availability is a basic implementation and minimizes required additional hardware or services, the Recovery Time Objective (RTO) increases as the database gets larger. The more data there is to back up, the longer it takes to restore and recover the database. Data loss depends on the type of backup. If only data files are backed up periodically, then when you restore, you incur data loss since the last backup.
Reducing RPO
The PostgreSQL continuous archiving feature lets you achieve a low Recovery Point Objective (RPO) and enable point-in-time recovery through backups. This process involves archiving Write-Ahead Logging (WAL) files and streaming WAL data, potentially to a remote storage location.
If WAL files are archived only when full or at specific intervals, a complete database loss (including current WAL files) restricts recovery to the last archived WAL file, which means that the Recovery Point Objective (RPO) must consider potential data loss. Conversely, continuous WAL data transfer maximizes zero data loss.
When doing continuous backups, you can perform recovery to a specific point in time. Point-in-time recovery allows restoration to a state before an error, such as accidental table deletion or incorrect batch updates. However, this recovery method impacts the Recovery Point Objective (RPO) unless a temporary auxiliary database is utilized.
Backup strategies
You can configure AlloyDB Omni Postgres-level backups to be stored on either local or remote storage. While local storage might be faster to back up and recover from, remote storage is usually more robust for handling failures when an entire host or VM fails.
Backups in non-Kubernetes
For non-Kubernetes deployments, you can schedule backups using the following PostgreSQL tools:
- pgBackRest. For more information, see Set up pgBackRest for AlloyDB Omni.
- Barman. For more information, see Set up Barman for AlloyDB Omni.
Alternatively, for small databases, you can choose to perform a logical backup of the database (using pg_dump for a single database or pg_dumpall for the entire cluster). You can restore using pg_restore.
Backups in Kubernetes using the AlloyDB Omni operator
For AlloyDB Omni deployed in a Kubernetes cluster, you can configure continuous backups using a backup plan for each database cluster. For more information, see Back up and restore in Kubernetes.
You can store AlloyDB Omni backups locally or remotely in Cloud Storage, including options provided by any cloud vendor. For more information, see Figure 1, which shows potential backup destinations.
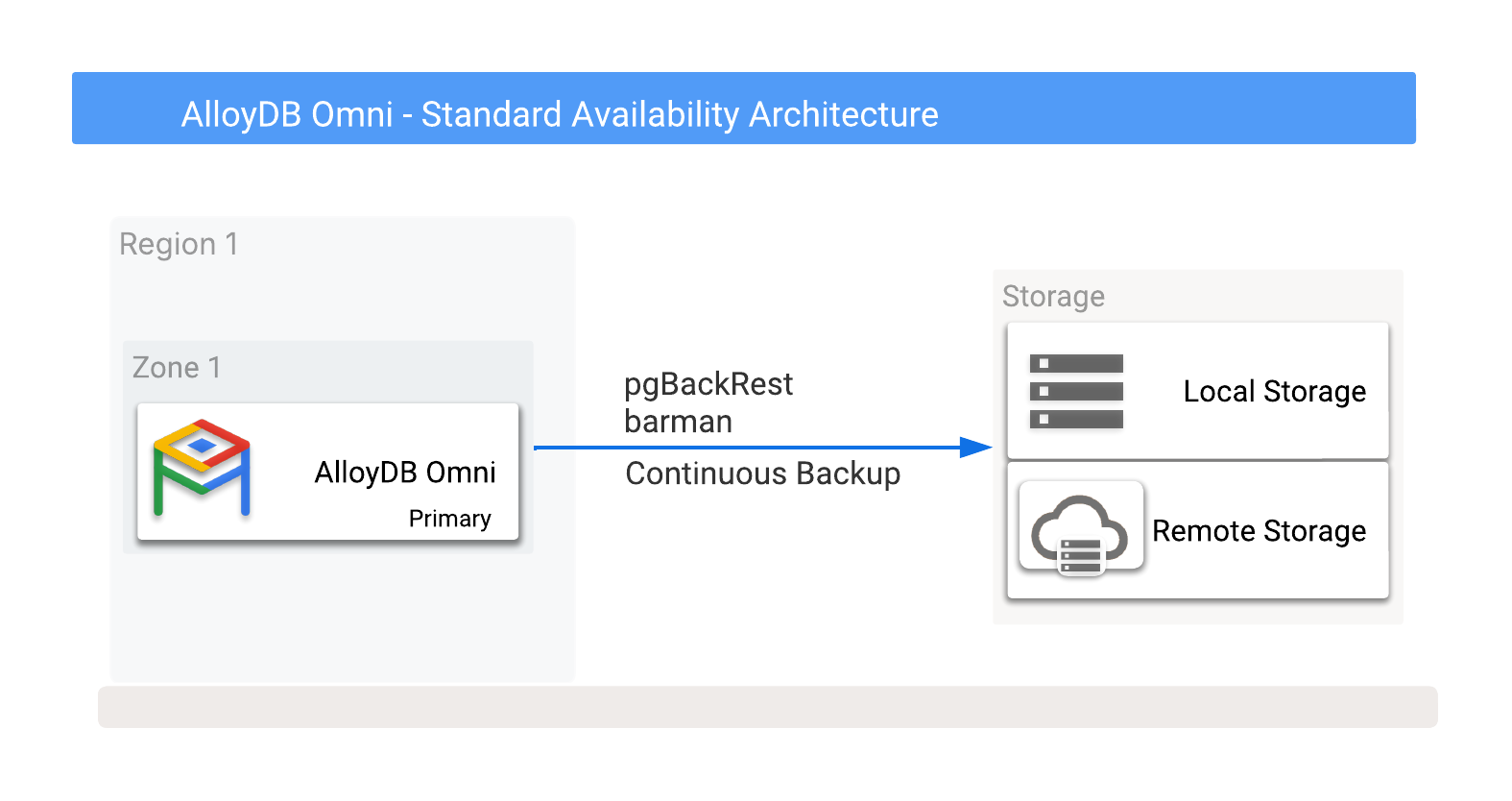
Figure 1. AlloyDB Omni with backup options.
Backups can be taken to either local or remote storage options. Local backups tend to be quicker because they rely on only I/O throughput, whereas remote backups usually have a higher latency and lower network bandwidth. However, remote backups provide optimal protection, including zonal failures.
You can also split local backups into local or shared storage. While local storage options are impacted by the lack of disaster recovery options when a database host fails, shared storage allows for that storage to be relocated to another server and then used for recovery. This means that shared storage potentially offers a faster RTO.
For local and shared storage deployments, the following types of backup might be scheduled or taken manually on demand:
- Full backups: complete backups of all the database files needed for data recovery.
- Differential backups: backups of only the file changes since the last full backup.
- Incremental backups: backups of only the file changes since the last backup of any kind.
Point-in-time recovery
Continuous backups of the PostgreSQL Write-Ahead Logging (WAL) files support point-in-time recovery. If, after a failure event, the WAL files are intact and usable, then you can use these files to recover with no data loss.
To control the writing of the WAL files, you can configure the following parameters:
| Parameter | Description |
|---|---|
|
Specifies how often the WAL writer flushes the WAL to disk unless the write is woken up sooner by a transaction that commits asynchronously The default value is 200ms. Increasing this value reduces the frequency of writes, but it might increase the amount of data lost if the server crashes. |
|
Specifies how much WAL data can accumulate before the WAL writer forces a flush to disk. The default value is 1MB. If set to zero, then WAL data is always flushed to disk immediately. |
|
Specifies whether the commit returns a response to the user before
the WAL data is flushed to disk. The default setting is
on, which ensures that the transaction is durable. In
other words, the commit has been written to disk before returning a
success code to the user. If set to off, then there is
up to three times wal_writer_delay before the
transaction is written to disk. |
WAL usage monitoring
You can use the following methods to observe WAL usage:
| Observation method | Description |
|---|---|
|
This standard view has the columns wal_write
and wal_sync, which store the
counts of the number of WAL writes and WAL synchronises. When the
configuration parameter track_wal_io_timing
is enabled, then the wal_write_time
and wal_sync_time are also
stored. Regular snapshots of this view can help to display the WAL write
and sync activity over time. |
pg_current_wal_lsn() |
This function returns the current log sequence number (lsn) position
which, when associated with a timestamp and collected as snapshots
over time, can provide the bytes/second of WAL generated using the
function pg_wal_lsn_diff(lsn1, lsn2).
This function is a useful metric in understanding the transaction
rate and how the WAL files are performing. |
Streaming WAL data to a remote location
When you use Barman, the WAL data can also be set up to stream in real-time to a remote location to ensure that there is little to no data loss on recovery. Despite the streaming in real time, there is a small chance of losing committed transactions as the streaming writes to the remote barman server are asynchronous by default. However, it's possible to set up WAL streaming using the synchronous mode that stores the WAL and sends a status response back to the source database. Keep in mind that this approach can slow down transactions if they have to wait for this write to complete before continuing.
Backup schedules
In most environments, backups are usually scheduled on a weekly basis. The following is a typical weekly schedule of backups:
- Sunday: full backup
- Monday, Tuesday: backup
- Wednesday: differential backup
- Thursday, Friday: incremental backup
- Saturday: differential backup
Using this typical schedule, a rolling recovery window of one week requires storage space for up to three full backups plus the required incremental or differential backups. This approach supports recovery for a failure that takes place during the full backup on Sunday, and the database recovery is required to extend to the previous Sunday prior to the backup starting.
To minimize RTO with a potential for higher RPO, additional databases can operate in continuous recovery mode. This involves replaying backups and continuously updating the secondary environment by archiving and replaying new WAL files. The actual RPO, which reflects potential data loss, depends on transaction frequency, WAL file size, and the use of WAL streaming.
Restoring in non-Kubernetes
For non-Kubernetes deployments, restoring an AlloyDB Omni database involves either stopping the Docker container and then restoring data, or restoring the data to a different location and launching a new Docker instance using that restored data. Once the container restarts, the database is accessible with the restored data.
For more information about recovery options, see Restore an AlloyDB Omni cluster using pgBackRest and Restore an AlloyDB Omni cluster using Barman.
Restoring in Kubernetes using Operator
To restore a database in Kubernetes, the operator offers recovery into the same Kubernetes cluster and namespace, from a named backup or a clone from a Point In Time (PIT). To clone a database into a different Kubernetes cluster, use pgBackRest. For more information, see Back up and restore in Kubernetes and Clone a database cluster from a Kubernetes backup overview.
Implementation
When you choose an availability reference architecture, keep in mind the following benefits, limitations, and alternatives.
Benefits
- Straightforward to use and manage, and suitable for non-critical databases with lenient RTO/RPO.
- Minimal additional hardware required
- Backups are always required for a full disaster recovery plan
- Recovery to any point in time within the recovery window is possible
Limitations
- Storage requirements that are possibly larger than the database itself, depending on the retention requirements.
- Can be slow to recover and might result in higher RTO.
- Can result in some data loss, depending upon the availability of the current WAL data after database failure, which might negatively affect RPO.
Alternatives
- Consider the Enhanced or Premium Availability Architecture for improved availability and disaster recovery options.
What's next
- AlloyDB Omni availability reference architecture overview.
- AlloyDB Omni Enhanced Availability.
- AlloyDB Omni Premium Availability.
- Install AlloyDB Omni on Kubernetes.
- Set up pgBackRest for AlloyDB Omni.
- Set up Barman for AlloyDB Omni.
- Back up and restore in Kubernetes.
- Restore an AlloyDB Omni cluster using pgBackRest.
- Restore an AlloyDB Omni cluster using Barman.
- Back up and restore in Kubernetes.
- Clone a database cluster from a Kubernetes backup overview.