如需了解有关将 AlloyDB Omni 安装到标准 Linux 环境的说明,请参阅安装 AlloyDB Omni。
概览
如需将 AlloyDB Omni 部署到 Kubernetes 集群,请安装 AlloyDB Omni 操作器(一种由 Google 提供的 Kubernetes API 扩展程序)。
您可以通过将声明性清单文件与 kubectl 实用程序配对来配置和控制基于 Kubernetes 的 AlloyDB Omni 数据库集群,就像任何其他基于 Kubernetes 的部署一样。您不会使用 AlloyDB Omni CLI,因为它旨在用于部署到单个 Linux 机器,而不是部署到 Kubernetes 集群。
基础映像
从 1.5.0 版开始,AlloyDB Omni 操作器 Kubernetes 映像基于 Red Hat 的通用基础映像 (UBI) 9 构建。这项迁移可提高部署的安全性、一致性和合规性。
AlloyDB Omni 操作器 1.1.0(及更高版本)兼容性
AlloyDB Omni 操作器 1.1.0 版与 AlloyDB Omni 15.5.3 和 15.5.4 版不兼容。如果您使用的是其中一个版本的 AlloyDB Omni,可能会收到类似以下内容的错误:
Error from server (Forbidden): error when creating "[...]/dbcluster.yaml": admission webhook "vdbcluster.alloydbomni.dbadmin.goog" denied the request: unsupported database version 15.5.3
准备工作
在通过 AlloyDB Omni 操作器将 AlloyDB Omni 安装到 Kubernetes 集群之前,请先确保您满足以下要求。
选择下载或安装选项
请从下面的下载和安装选项中选择一项:
| 媒体 | 下载位置及安装指南 | 部署目标 |
|---|---|---|
| OpenShift 操作器及 OLM 软件包 | OpenShift Container Platform Web 控制台 | OpenShift 环境 |
| Kubernetes 操作器及 OLM 软件包 | Artifacthub.io | 自备 Kubernetes 容器环境 - 例如,本地、公有云、Google Kubernetes Engine、Amazon EKS 和 Azure AKS。 |
| Kubernetes 操作器及 Helm 图表 | 在 Kubernetes 上安装 AlloyDB Omni(本页内容) | 自备 Kubernetes 容器环境 - 例如,本地、公有云、GKE、Amazon EKS 和 Azure AKS。 |
验证访问权限
验证您有权访问以下资源:
- 运行以下软件的 Kubernetes 集群:
- Kubernetes 1.21 版或更高版本。
cert-manager服务。
kubectl实用程序。helm软件包管理系统或 Operator Lifecycle Manager。- Google Cloud CLI。 安装 gcloud CLI 后,您必须通过运行
gcloud auth login对您的 Google Cloud 账号进行身份验证。
满足硬件和软件要求
Kubernetes 集群中的每个节点都必须具有以下内容:
- 至少两个 x86 或 AMD64 CPU。
- 至少 8 GB RAM。
- Linux 内核 4.18 版或更高版本。
- 启用了对照组 (cgroup) v2。
安装 AlloyDB Omni 操作器
您可以使用不同的方法(包括 Helm 和 Operator Lifecycle Manager [OLM])安装 AlloyDB Omni 操作器。
Helm
如需安装 AlloyDB Omni operator,请按照以下步骤操作:
- 定义以下环境变量:
export GCS_BUCKET=alloydb-omni-operator export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest) export OPERATOR_VERSION="${HELM_PATH%%/*}" - 下载 AlloyDB Omni 操作器:
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
- 安装 AlloyDB Omni 操作器:
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \ --create-namespace \ --namespace alloydb-omni-system \ --atomic \ --timeout 5m安装成功后,系统会显示以下输出:
NAME: alloydbomni-operator LAST DEPLOYED: CURRENT_TIMESTAMP NAMESPACE: alloydb-omni-system STATUS: deployed REVISION: 1 TEST SUITE: None
- 如需进行清理,请删除下载的 AlloyDB Omni 操作器安装文件。该文件名为
alloydbomni-operator-VERSION_NUMBER.tgz,位于当前工作目录中。
OLM
如需使用 Operator Lifecycle Manager 安装 AlloyDB Omni 操作器,请按以下步骤操作:
点击安装按钮以显示相关说明。
完成所有安装步骤。
安装 AlloyDB Omni 操作器后,在集群中手动创建 cert-manager 资源。这是一项强制性要求。使用以下命令:
kubectl create ns ${NAMESPACE:?} kubectl apply -f - <<EOF apiVersion: cert-manager.io/v1 kind: ClusterIssuer metadata: name: alloydbomni-selfsigned-cluster-issuer spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Issuer metadata: name: fleet-selfsigned-issuer namespace: ${NAMESPACE:?} spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Certificate metadata: name: fleet-serving-cert namespace: ${NAMESPACE:?} spec: dnsNames: - fleet-webhook-service.alloydb-omni-system.svc - fleet-webhook-service.alloydb-omni-system.svc.cluster.local issuerRef: kind: Issuer name: fleet-selfsigned-issuer secretName: fleet-webhook-server-cert --- apiVersion: cert-manager.io/v1 kind: Issuer metadata: name: local-selfsigned-issuer namespace: ${NAMESPACE:?} spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Certificate metadata: name: local-serving-cert namespace: ${NAMESPACE:?} spec: dnsNames: - local-webhook-service.alloydb-omni-system.svc - local-webhook-service.alloydb-omni-system.svc.cluster.local issuerRef: kind: Issuer name: local-selfsigned-issuer secretName: local-webhook-server-cert EOF
将
NAMESPACE替换为您的操作器所在的命名空间,例如alloydb-omni-system。
OLM
如需使用 OLM 在 Red Hat OpenShift 环境中安装 AlloyDB Omni 操作器,请登录 Red Hat OpenShift Web 控制台。
依次选择操作器 > OperatorHub。
使用搜索字段查找 AlloyDB Omni 操作器。
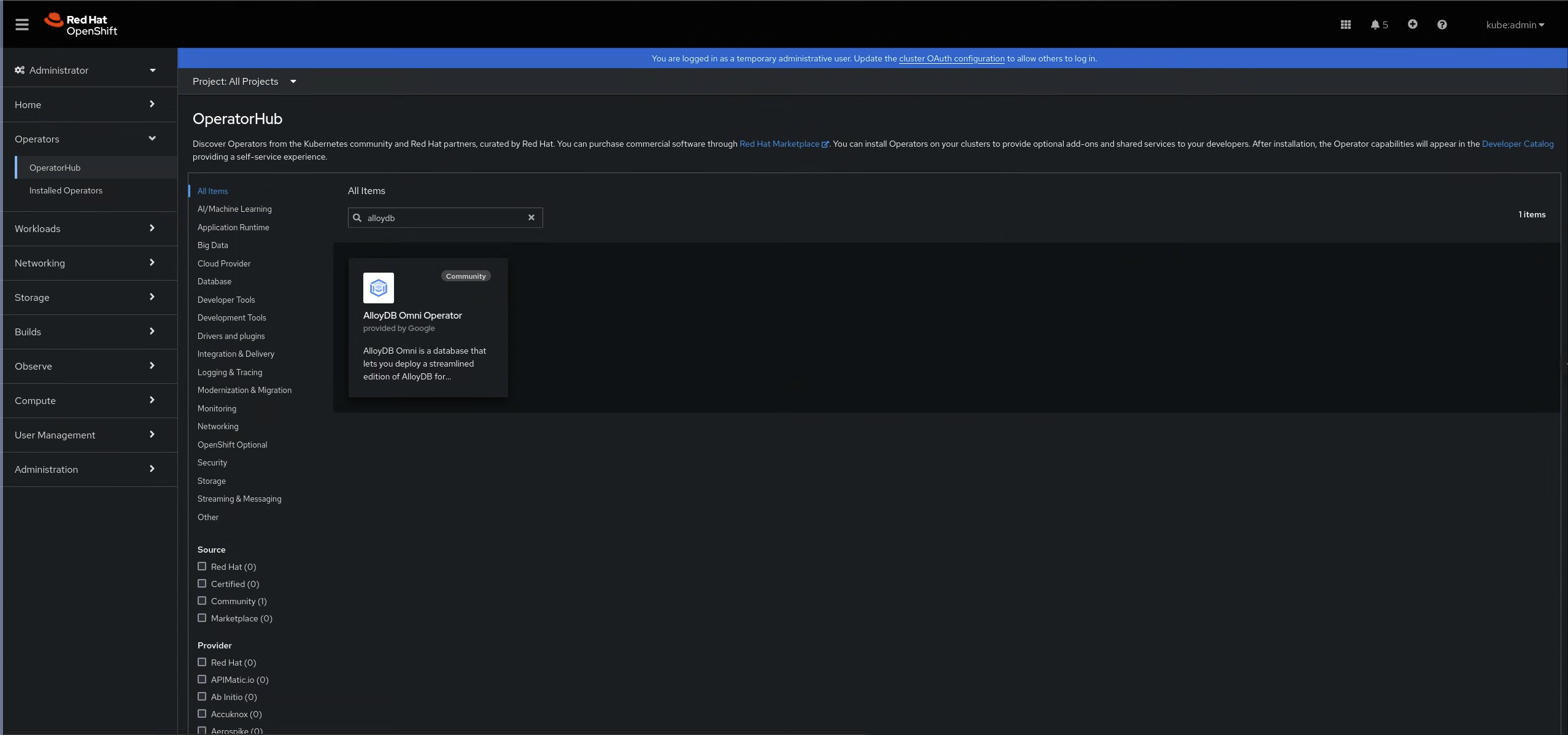
图 1:OperatorHub 中的 AlloyDB Omni 操作器 在 AlloyDB Omni 操作器窗格中,点击安装。
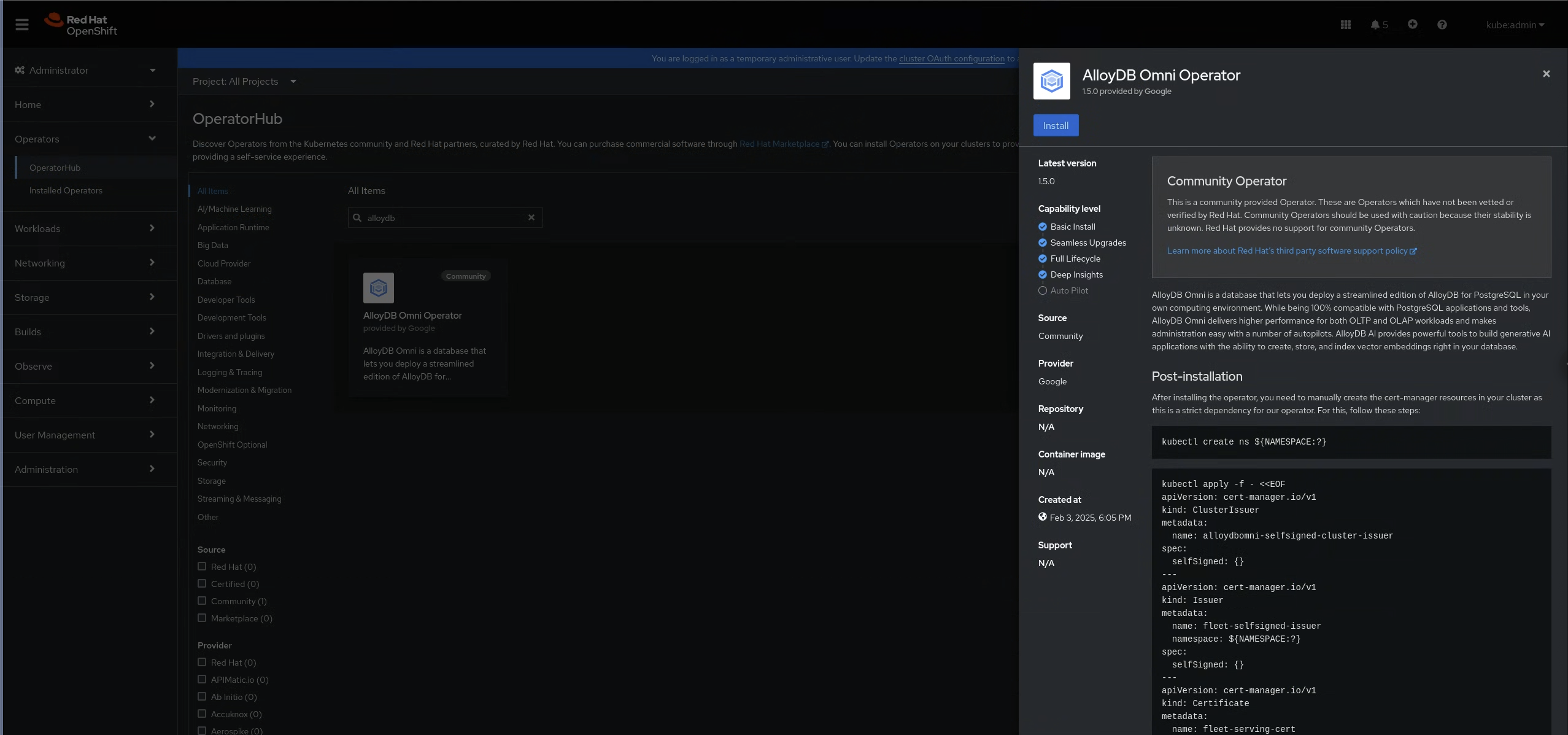
图 2:AlloyDB Omni 操作器窗格 安装 AlloyDB Omni 操作器后,在集群中手动创建 cert-manager 资源。这是一项强制性要求。使用以下命令:
kubectl create ns ${NAMESPACE:?} kubectl apply -f - <<EOF apiVersion: cert-manager.io/v1 kind: ClusterIssuer metadata: name: alloydbomni-selfsigned-cluster-issuer spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Issuer metadata: name: fleet-selfsigned-issuer namespace: ${NAMESPACE:?} spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Certificate metadata: name: fleet-serving-cert namespace: ${NAMESPACE:?} spec: dnsNames: - fleet-webhook-service.alloydb-omni-system.svc - fleet-webhook-service.alloydb-omni-system.svc.cluster.local issuerRef: kind: Issuer name: fleet-selfsigned-issuer secretName: fleet-webhook-server-cert --- apiVersion: cert-manager.io/v1 kind: Issuer metadata: name: local-selfsigned-issuer namespace: ${NAMESPACE:?} spec: selfSigned: {} --- apiVersion: cert-manager.io/v1 kind: Certificate metadata: name: local-serving-cert namespace: ${NAMESPACE:?} spec: dnsNames: - local-webhook-service.alloydb-omni-system.svc - local-webhook-service.alloydb-omni-system.svc.cluster.local issuerRef: kind: Issuer name: local-selfsigned-issuer secretName: local-webhook-server-cert EOF
将
NAMESPACE替换为您的操作器所在的命名空间,例如alloydb-omni-system。
配置互联 GDC 存储空间
如需在互联 GDC 上安装 AlloyDB Omni 操作器,您需要执行额外的步骤来配置存储空间,因为互联 GDC 集群未设置默认存储类别。您必须先设置默认存储类别,然后才能创建 AlloyDB Omni 数据库集群。
如需了解如何将 Symcloud Storage 设置为默认存储类别,请参阅将 Symcloud Storage 设置为默认存储类别。
如需详细了解如何更改所有其他存储类别的默认值,请参阅更改默认 StorageClass。
创建数据库集群
AlloyDB Omni 数据库集群包含运行 AlloyDB Omni 服务器所需的所有存储和计算资源,包括主服务器、所有副本以及您的所有数据。
在 Kubernetes 集群上安装 AlloyDB Omni 操作器后,您可以通过应用类似以下内容的清单,在 Kubernetes 集群上创建 AlloyDB Omni 数据库集群:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-DB_CLUSTER_NAME
namespace: DB_CLUSTER_NAMESPACE
type: Opaque
data:
DB_CLUSTER_NAME: "ENCODED_PASSWORD"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: DB_CLUSTER_NAME
namespace: DB_CLUSTER_NAMESPACE
spec:
databaseVersion: "16.3.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-DB_CLUSTER_NAME
resources:
cpu: CPU_COUNT
memory: MEMORY_SIZE
disks:
- name: DataDisk
size: DISK_SIZE
替换以下内容:
DB_CLUSTER_NAME:此数据库集群的名称,例如my-db-cluster。DB_CLUSTER_NAMESPACE(可选):要在其中创建数据库集群的命名空间,例如my-db-cluster-namespace。ENCODED_PASSWORD:默认postgres用户角色的数据库登录密码(以 base64 字符串编码),例如Q2hhbmdlTWUxMjM=表示ChangeMe123。CPU_COUNT:此数据库集群中的每个数据库实例可用的 CPU 数量。MEMORY_SIZE:此数据库集群的每个数据库实例的内存量。建议将此值设置为每个 CPU 8 千兆字节。例如,如果您之前在此清单中将cpu设置为2,则建议将memory设置为16Gi。DISK_SIZE:每个数据库实例的磁盘大小,例如10Gi。
应用此清单后,您的 Kubernetes 集群将包含具有指定内存、CPU 和存储配置的 AlloyDB Omni 数据库集群。如需与新数据库集群建立测试连接,请参阅使用预安装的 psql 进行连接。
如需详细了解 Kubernetes 清单以及如何进行应用,请参阅管理资源。