Il peut être difficile de trouver la cause des erreurs qui surviennent lors de l'entraînement d'un modèle ou de l'obtention de prédictions dans le cloud. Cette page vous explique comment identifier et déboguer les problèmes que vous rencontrez sur AI Platform Prediction. Si vous rencontrez des problèmes avec le framework de machine learning que vous utilisez, consultez plutôt la documentation du framework de machine learning.
Outil de ligne de commande
- ERROR: (gcloud) Invalid choice: 'ai-platform'.
Cette erreur signifie que vous devez mettre à jour gcloud. Pour mettre à jour gcloud, exécutez la commande suivante :
gcloud components update- ERREUR : (gcloud) arguments non reconnus : --framework=SCIKIT_LEARN.
Cette erreur signifie que vous devez mettre à jour gcloud. Pour mettre à jour gcloud, exécutez la commande suivante :
gcloud components update- ERREUR : (gcloud) arguments non reconnus : --framework=XGBOOST.
Cette erreur signifie que vous devez mettre à jour gcloud. Pour mettre à jour gcloud, exécutez la commande suivante :
gcloud components update- ERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\x03'. (Code d'erreur : 0)
Ce message d'erreur signifie que la bibliothèque qui a été utilisée pour exporter le modèle n'était pas la bonne. Pour y remédier, réexportez le modèle en utilisant la bibliothèque appropriée. Par exemple, exportez des modèles de la forme
model.pklavec la bibliothèquepickleet les modèles de la formemodel.joblibavec la bibliothèquejoblib.- ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.
Cette erreur signifie que vous avez spécifié
jsoncomme valeur de l'indicateur--data-formatlors de l'envoi d'une tâche de prédiction par lot. Pour pouvoir utiliser le format de donnéesJSON, vous devez indiquertextcomme valeur de l'indicateur--data-format.
Versions Python
- ERROR: Bad model detected with error: "Failed to load model: Could not load the
- model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
- sure the model was exported using python 2. Otherwise, please specify the
- correct 'python_version' parameter when deploying the model. Currently,
- 'python_version' accepts 2.7 and 3.5. (Error code: 0)"
- Ce message d'erreur signifie qu'un fichier de modèle exporté avec Python 3 a été déployé sur une ressource de version de modèle AI Platform Prediction paramétrée sur Python 2.7.
Pour remédier à ce problème, procédez comme suit :
- Créez une ressource de version de modèle en définissant "python_version" sur "3.5".
- Déployez le même fichier de modèle sur la nouvelle ressource de version de modèle.
La commande virtualenv est introuvable.
Si vous rencontrez cette erreur lorsque vous tentez d'activer virtualenv, une solution consiste à ajouter le répertoire contenant virtualenv à votre variable d'environnement $PATH. La modification de cette variable vous permet d'utiliser les commandes virtualenv sans avoir besoin de saisir leur chemin d'accès complet.
Pour commencer, installez virtualenv en exécutant la commande suivante :
pip install --user --upgrade virtualenv
Le programme d'installation vous invite à modifier la variable d'environnement $PATH et indique le chemin d'accès au script virtualenv. Sur macOS, ce chemin d'accès ressemble à ceci : /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Ouvrez le fichier dans lequel l'interface système charge les variables d'environnement. En règle générale, il s'agit du fichier ~/.bashrc ou ~/.bash_profile dans macOS.
Ajoutez la ligne suivante, en remplaçant [VALUES-IN-BRACKETS] par les valeurs appropriées :
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Enfin, exécutez la commande suivante pour charger votre fichier .bashrc ou .bash_profile mis à jour :
source ~/.bashrc
Utiliser des journaux de tâches
Les journaux de tâches enregistrés par Cloud Logging constituent un bon point de départ pour la résolution des problèmes.
Journalisation des différents types d'opérations
Votre expérience de journalisation varie selon le type d'opération, comme illustré dans les sections ci-dessous.
Journaux de prédiction par lot
Toutes vos tâches de prédiction par lot sont enregistrées.
Journaux de prédiction en ligne
Vos requêtes de prédiction en ligne ne génèrent pas de journaux par défaut. Vous pouvez activer Cloud Logging lorsque vous créez une ressource de modèle :
gcloud
Incluez l'indicateur --enable-logging lorsque vous exécutez la commande gcloud ai-platform models create.
Python
Définissez onlinePredictionLogging sur True dans la ressource Model que vous utilisez pour appeler projects.models.create.
Trouver les journaux
Les journaux de tâches contiennent tous les événements de l'opération, y compris les événements de tous les processus de votre cluster lorsque vous effectuez un entraînement distribué. Si vous exécutez une tâche d'entraînement distribué, les journaux au niveau de la tâche sont signalés pour le processus du nœud maître. La première étape de la résolution d'une erreur consiste généralement à examiner les journaux de ce processus, en filtrant les événements enregistrés pour les autres processus de votre cluster. Les exemples de cette section illustrent ce type de filtre.
Vous pouvez filtrer les journaux à partir de la ligne de commande ou dans la section Cloud Logging de Google Cloud Console. Dans les deux cas, utilisez les valeurs de métadonnées suivantes dans votre filtre si nécessaire :
| Élément de métadonnées | Filtrer les journaux affichant les événements pour lesquels cet élément est… |
|---|---|
| resource.type | égal à "cloud_ml_job". |
| resource.labels.job_id | égal au nom de votre tâche. |
| resource.labels.task_name | égal à "master-replica-0" pour lire uniquement les entrées de journal de votre nœud de calcul maître. |
| severity | supérieur ou égal à ERROR pour lire uniquement les entrées de journal correspondant à des conditions d'erreur. |
Ligne de commande
Exécutez gcloud beta logging read pour construire une requête répondant à vos besoins. Vous trouverez quelques exemples ci-dessous.
Chaque exemple s'appuie sur les variables d'environnement suivantes :
PROJECT="my-project-name"
JOB="my_job_name"
Vous pouvez remplacer ces variables par des chaînes littérales si vous le souhaitez.
Pour générer une sortie-écran de vos journaux de tâche, exécutez cette commande :
gcloud ai-platform jobs stream-logs $JOB
Vous pouvez consulter l'intégralité des options disponibles pour la commande gcloud ai-platform jobs stream-logs.
Pour générer une sortie-écran du journal correspondant au nœud de calcul maître, exécutez cette commande :
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
Pour générer une sortie-écran uniquement pour les erreurs détectées sur le nœud de calcul maître, exécutez cette commande :
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Les exemples précédents illustrent les cas les plus courants de filtrage de journaux à partir de votre tâche d'entraînement AI Platform Prediction. Cloud Logging fournit de nombreuses options de filtrage puissantes que vous pouvez utiliser si vous avez besoin d'affiner votre recherche. La documentation sur le filtrage avancé décrit ces options en détail.
Console
Accédez à la page des tâches AI Platform Prediction dans la console Google Cloud :
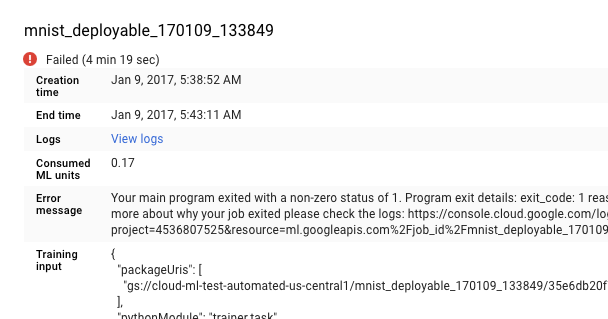
Sélectionnez la tâche qui a échoué dans la liste affichée sur la page Jobs (Tâches) pour en consulter les détails.

- Cliquez sur Afficher les journaux pour ouvrir Cloud Logging.
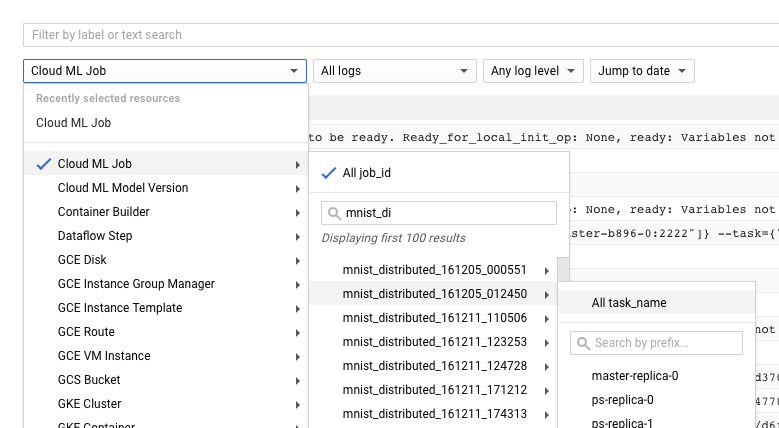
Vous pouvez également accéder directement à Cloud Logging, mais cette procédure implique de rechercher votre tâche :
- Développez le sélecteur de ressources.
- Dans la liste des ressources, développez "Tâche AI Platform Prediction".
- Recherchez le nom de votre tâche dans la liste "ID de tâche". (Vous pouvez saisir les premières lettres du nom dans le champ de recherche pour affiner les résultats.)
- Développez la tâche et sélectionnez
master-replica-0dans la liste des tâches.
Obtenir des informations à partir des journaux
Une fois que vous avez trouvé le journal correspondant à votre tâche et que vous l'avez filtré sur master-replica-0, vous pouvez examiner les événements enregistrés afin d'identifier la source du problème. Vous devez suivre la procédure de débogage Python standard, mais gardez à l'esprit les points suivants :
- Les événements possèdent plusieurs niveaux de gravité. Vous pouvez appliquer un filtre pour n'afficher que les événements d'un certain niveau (par exemple, les erreurs, ou encore les erreurs et les avertissements).
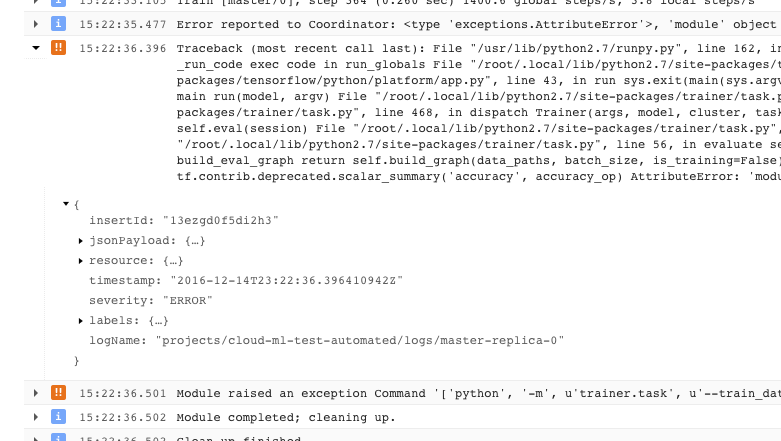
- Un problème entraînant la fermeture de votre application d'entraînement avec une condition d'erreur non récupérable (code renvoyé supérieur à 0) est enregistré en tant qu'exception, précédée de la trace de la pile :
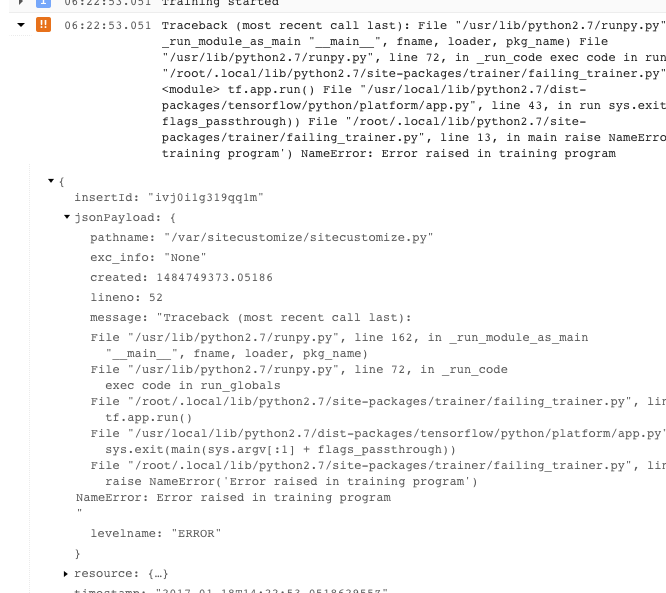
- Pour obtenir plus d'informations, développez les objets dans le message JSON enregistré (indiqué par une flèche orientée vers la droite et le contenu répertorié en tant que {...}). Par exemple, vous pouvez développer jsonPayload pour afficher la trace de la pile sous une forme plus lisible que celle indiquée dans la description de l'erreur principale :
- Certaines erreurs indiquent des instances d'erreurs renouvelables. Elles n'incluent généralement pas de trace de la pile, et leur diagnostic peut être plus difficile à établir.
Tirer pleinement parti de la journalisation
Le service d'entraînement AI Platform Prediction enregistre automatiquement les événements suivants :
- Informations sur l'état interne au service.
- Messages envoyés par votre application d'entraînement à
stderr - Texte de sortie envoyé par votre application d'entraînement à
stdout
Vous pouvez faciliter la résolution des problèmes de votre application d'entraînement en suivant les bonnes pratiques de programmation ci-dessous :
- Envoyez des messages pertinents à stderr (comprenant des informations de journalisation, par exemple).
- Relevez l'exception la plus logique et la plus descriptive en cas de problème.
- Ajoutez des chaînes descriptives aux objets de l'exception.
La documentation Python fournit plus d'informations sur les exceptions.
Résoudre des problèmes de prédiction
Vous trouverez dans cette section la description de certains problèmes fréquemment rencontrés lors de l'obtention de prédictions.
Gérer les conditions spécifiques à la prédiction en ligne
Cette section fournit des conseils sur des conditions d'erreur de prédiction en ligne spécifiques que rencontrent certains utilisateurs.
Exécution trop longue des prédictions (30 à 180 secondes)
La lenteur d'exécution des prédictions en ligne est souvent due au scaling des nœuds de traitement à partir de zéro. Si des requêtes de prédiction sont régulièrement effectuées auprès de votre modèle, le système maintient en permanence un ou plusieurs nœuds prêts à diffuser des prédictions. Si votre modèle n'a pas diffusé de prédiction depuis longtemps, le service s'adapte à la baisse en faisant repasser le nombre de nœuds prêts à zéro. La prochaine requête de prédiction effectuée après une telle réduction prendra beaucoup plus de temps que d'habitude, car le service devra de nouveau provisionner des nœuds pour la traiter.
Codes d'état HTTP
Lorsqu'une erreur se produit au moment d'une requête de prédiction en ligne, le service renvoie généralement un code d'état HTTP. Voici les codes les plus courants, accompagnés de leur signification, dans le cadre des prédictions en ligne :
- 429 : mémoire saturée
Le nœud de traitement s'est trouvé à court de mémoire durant l'exécution de votre modèle. Il n'existe aucun moyen d'augmenter la mémoire allouée aux nœuds de prédiction pour le moment. Vous pouvez essayer les solutions suivantes pour faire fonctionner votre modèle :
- Réduisez la taille de votre modèle en appliquant l'une de ces méthodes :
- Utilisez des variables moins précises.
- Quantifiez vos données continues.
- Diminuez la taille des autres caractéristiques d'entrée (par exemple, en utilisant des termes plus courts).
- Renvoyez la requête avec un lot d'instances plus petit.
- Réduisez la taille de votre modèle en appliquant l'une de ces méthodes :
- 429 - Too many pending requests
Votre modèle reçoit plus de requêtes qu'il ne peut en traiter. Si vous utilisez l'autoscaling, le délai nécessaire aux requêtes pour arriver est plus court que celui dont a besoin le système pour évoluer. En outre, si la valeur minimale des nœuds est 0, cette configuration peut mener à un scénario de "démarrage à froid" où un taux d'erreur de 100% sera observé jusqu'à ce que le premier nœud soit viable.
Avec l'autoscaling, vous pouvez essayer de renvoyer les requêtes avec un intervalle exponentiel entre les tentatives. Le renvoi des requêtes avec un intervalle exponentiel entre les tentatives peut laisser le temps au système de s'adapter.
Par défaut, l'autoscaling est déclenché par une utilisation du processeur dépassant 60% et est configurable.
- 429 - Quota
Votre projet Google Cloud Platform est limité à 10 000 requêtes toutes les 100 secondes (soit environ 100 par seconde). Si cette erreur se produit lors de pics d'activité temporaires, vous pouvez généralement réessayer en spécifiant un intervalle exponentiel entre les tentatives, afin que toutes vos requêtes finissent par être traitées. Si ce code s'affiche systématiquement, vous pouvez demander une augmentation de quota. Pour en savoir plus, consultez la page relative aux quotas.
- 503 : nos systèmes ont détecté un trafic inhabituel provenant de votre réseau informatique
La fréquence à laquelle votre modèle a reçu des requêtes depuis une seule et même adresse IP est si élevée que le système soupçonne une attaque par déni de service. N'envoyez plus de requêtes pendant une minute, puis reprenez les envois à un rythme moins soutenu.
- 500 : impossible de charger le modèle
Le système n'est pas parvenu à charger votre modèle. Pour remédier au problème, suivez les étapes ci-dessous :
- Assurez-vous que votre application d'apprentissage exporte le bon modèle.
- Exécutez une prédiction test à l'aide de la commande
gcloud ai-platform local predict. - Réexportez votre modèle, puis réessayez.
Erreurs de mise en forme pour les requêtes de prédiction
Les messages ci-dessous sont tous liés à vos données de saisie de prédiction.
- "JSON vide ou mal formé/non valide dans le corps de la requête"
- Le service n'a pas pu analyser le texte JSON spécifié dans votre requête, ou votre requête est vide. Vérifiez votre message pour trouver des erreurs ou des omissions empêchant l'analyse du texte JSON.
- "Missing 'instances' field in request body"
- Le corps de la requête ne respecte pas le format approprié. Il doit s'agir d'un objet JSON avec une seule clé nommée
"instances"qui contient une liste avec toutes vos instances d'entrée. - Erreur d'encodage JSON lors de la création d'une requête
Votre requête inclut des données encodées en base64, mais pas au format JSON approprié. Chaque chaîne encodée en base64 doit être représentée par un objet avec une seule clé nommée
"b64". Exemple :{"b64": "an_encoded_string"}Une autre erreur base64 se produit lorsque des données binaires ne sont pas encodées en base64. Encodez vos données et mettez-les en forme de la manière suivante :
{"b64": base64.b64encode(binary_data)}En savoir plus sur la mise en forme et l'encodage des données binaires.
La prédiction dans le cloud prend plus de temps que via l'application de bureau
La prédiction en ligne est conçue pour être un service évolutif qui diffuse rapidement un nombre élevé de requêtes de prédiction. Ce service est optimisé pour assurer des performances globales sur l'ensemble des requêtes diffusées. L'accent étant mis sur l'évolutivité, les critères de performances ne sont pas les mêmes que pour l'exécution d'un petit nombre de prédictions sur votre ordinateur local.
Étapes suivantes
- Accédez à l'assistance.
- Obtenez plus d'informations sur le modèle d'erreur des API Google, en particulier sur les codes d'erreur canoniques définis dans
google.rpc.Codeet sur les informations relatives aux erreurs courantes définies dans google/rpc/error_details.proto. - Apprenez à surveiller vos tâches d’entraînement.
- Reportez-vous à la page Dépannage et FAQ sur Cloud TPU pour obtenir de l'aide afin de diagnostiquer et résoudre des problèmes lors de l'exécution d'AI Platform Prediction avec Cloud TPU.