借助于 AI Platform Pipelines,您可以将机器学习 (ML) 工作流程编排成可重复使用且可重现的流水线。AI Platform Pipelines 便于您在 Google Kubernetes Engine 上设置 Kubeflow Pipelines 和 TensorFlow Extended。
本指南介绍在 GKE 上部署 AI Platform Pipelines 的几个选项。您可以在现有 GKE 集群上部署 Kubeflow Pipelines,也可以创建新的 GKE 集群。如果要重复使用现有的 GKE 集群,请确保集群满足以下要求:
- 您的集群必须至少有 3 个节点。每个节点必须至少有 2 个 CPU 和 4 GB 可用内存。
- 集群的访问权限范围必须授予对所有 Cloud API 的完整访问权限,否则您的集群必须使用自定义服务账号。
- 集群不能已安装 Kubeflow Pipelines。
选择最适合您的情况的部署选项:
- 使用 AI Platform Pipelines 创建对 Google Cloud 拥有完整访问权限的新 GKE 集群,并将 Kubeflow Pipelines 部署到该集群。此选项可让您更轻松地部署和使用 AI Platform Pipelines。
- 创建一个对Google Cloud 拥有精细访问权限的新 GKE 集群,并将 Kubeflow Pipelines 部署到此集群。通过此选项,您可以指定集群上的工作负载可以访问的资源和 API。 Google Cloud
- 将 AI Platform Pipelines 部署到现有 GKE 集群此选项介绍如何将 AI Platform Pipelines 部署到现有 GKE 集群。
准备工作
在按照本指南操作之前,请检查您的 Google Cloud 项目是否已正确设置,以及您是否有足够的权限来部署 AI Platform Pipelines。- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 请按照以下说明检查您是否已获得部署 AI Platform Pipelines 所需的角色。
-
打开 Cloud Shell 会话。
Cloud Shell 在 Google Cloud Console 底部的框架中打开。
-
您必须对项目具有 Viewer (
roles/viewer) 和 Kubernetes Engine Admin (roles/container.admin) 角色,或者对项目具有其他包含相同权限的角色(例如 Ownerroles/owner角色),才能部署 AI Platform Pipelines。在 Cloud Shell 中运行以下命令,以列出具有 Viewer 和 Kubernetes Engine Admin 角色的主账号。gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
将 PROJECT_ID 替换为您的 Google Cloud 项目的 ID。
使用此命令的输出来验证您的账号是否具有 Viewer 和 Kubernetes Engine Admin 角色。
-
如果要授予集群精细访问权限,您还必须对项目具有 Service Account Admin (
roles/iam.serviceAccountAdmin) 角色,或者对项目具有其他包含相同权限的角色,例如 Editor (roles/editor) 或 Owner (roles/owner) 角色。在 Cloud Shell 中运行以下命令以列出具有 Service Account Admin 角色的主账号。gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
将 PROJECT_ID 替换为您的 Google Cloud 项目的 ID。
使用此命令的输出来验证您的账号是否具有 Service Account Admin 角色。
-
如果您未获授予所需的角色,请与您的 Google Cloud 项目管理员联系以获取更多帮助。
-
部署对 Google Cloud拥有完整访问权限的 AI Platform Pipelines
AI Platform Pipelines 通过为您创建 GKE 集群并将 Kubeflow Pipelines 部署到集群,让您可以更轻松地设置和使用 Kubeflow Pipelines。当 AI Platform Pipelines 为您创建 GKE 集群时,该集群将使用默认 Compute Engine 服务账号。若要向集群提供对您在项目中启用的 Google Cloud 资源和 API 的完整访问权限,您可以向集群授予对 https://www.googleapis.com/auth/cloud-platform 访问权限范围的访问权限。通过这种方式授予访问权限,可让在集群上运行的 ML Pipelines 访问 Google CloudAPI,例如 AI Platform Training 和 AI Platform Prediction。虽然此过程可让您更轻松地设置 AI Platform Pipelines,但可能会给流水线开发者授予过多的 Google Cloud 资源和 API 访问权限。
按照以下说明部署拥有对资源和 API 的完整访问权限的 AI Platform Pipelines。 Google Cloud
在 Google Cloud Console 中打开 AI Platform Pipelines。
在 AI Platform Pipelines 工具栏中,点击新建实例。 Kubeflow Pipelines 将在 Google Cloud Marketplace 中打开。
点击配置。系统将打开部署 Kubeflow Pipelines 表单。
如果显示创建新集群链接,请点击创建新集群。否则,请继续下一步操作。

选择您的集群所在的集群地区。 如需帮助决定使用哪个地区,请参阅有关地区选择的最佳做法。
勾选允许访问以下 Cloud API,以便为 GKE 集群上运行的应用授予对 Google Cloud 资源的访问权限。勾选此复选框即表示您授予集群对
https://www.googleapis.com/auth/cloud-platform访问权限范围的访问权限。此访问权限范围可提供对您已在项目中启用的 Google Cloud 资源的完整访问权限。以这种方式授予集群对 Google Cloud 资源的访问权限可省去创建和管理服务账号或创建 Kubernetes Secret 的麻烦。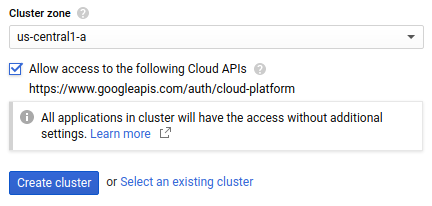
点击创建集群。此步骤可能需要几分钟时间。
命名空间用于管理大型 GKE 集群中的资源。如果您不打算在集群中使用命名空间,请在命名空间下拉列表中选择默认。
如果您打算在 GKE 集群中使用命名空间,请使用命名空间下拉列表创建命名空间。如需创建命名空间,请执行以下操作:
- 在命名空间下拉列表中选择创建命名空间。此时会显示新建命名空间名称文本框。
- 在新建命名空间名称中输入命名空间名称。
如需详细了解命名空间,请参阅有关使用命名空间组织 Kubernetes 的博文。
在应用实例名称框中,输入 Kubeflow Pipelines 实例的名称。
借助托管存储,您可以使用 Cloud SQL 和 Cloud Storage 存储机器学习流水线的元数据和工件,而不是将它们存储在 Compute Engine 永久性磁盘上。通过使用代管式服务来存储流水线工件和元数据,可让您更轻松地备份和恢复集群的数据。若要部署具有托管存储的 Kubeflow Pipelines,请选择使用托管存储并提供以下信息:
工件存储 Cloud Storage 存储分区:借助托管存储,Kubeflow Pipelines 可将流水线工件存储在 Cloud Storage 存储分区中。指定您希望 Kubeflow Pipelines 在其中存储工件的存储分区的名称。如果指定的存储分区不存在,Kubeflow Pipelines 部署程序将在
us-central1地区中为您自动创建存储分区。Cloud SQL 实例连接名称:借助托管存储,Kubeflow Pipelines 可将流水线元数据存储在 Cloud SQL 上的 MySQL 数据库中。指定 Cloud SQL MySQL 实例的连接名称。
数据库用户名:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库用户名。目前,数据库用户必须具有
ALLMySQL 特权才能部署具有托管存储的 Kubeflow Pipelines。如果将此字段留空,则此值默认为 root。数据库密码:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库密码。如果将此字段留空,Kubeflow Pipelines 将在不提供密码的情况下连接到数据库;如果您指定的用户名需要密码,该操作将失败。
数据库名称前缀:指定数据库名称前缀。前缀值必须以字母开头,并且只能包含小写字母、数字和下划线。
在部署过程中,Kubeflow Pipelines 会创建两个数据库:“DATABASE_NAME_PREFIX_pipeline”和“DATABASE_NAME_PREFIX_metadata”。如果您的 MySQL 实例中存在使用这些名称的数据库,Kubeflow Pipelines 将重复使用现有数据库。如果未指定此值,则将使用应用实例名称作为数据库名称前缀。
点击部署。此步骤可能需要几分钟时间。
要访问流水线信息中心,请在 Google Cloud 控制台中打开 AI Platform Pipelines。
然后,如需查看您的 AI Platform Pipelines 实例,请点击打开流水线信息中心。
部署对 Google Cloud拥有精细访问权限的 AI Platform Pipelines
ML Pipelines 使用 GKE 集群节点池的服务账号和访问权限范围访问资源。 Google Cloud 目前,如需限制集群对特定资源的访问权限,您必须将 AI Platform Pipelines 部署到使用用户代管式服务账号的 GKE 集群。 Google Cloud
按照以下部分中的说明创建和配置服务账号,使用服务账号创建 GKE 集群,并将 Kubeflow Pipelines 部署到您的 GKE 集群。
为 GKE 集群创建服务账号
按照以下说明为 GKE 集群设置服务账号。
打开 Cloud Shell 会话。
Cloud Shell 在 Google Cloud Console 底部的框架中打开。
在 Cloud Shell 中运行以下命令,以创建服务账号并向其授予足够的权限来运行 AI Platform Pipelines。详细了解使用用户代管式服务账号运行 AI Platform Pipelines 所需的角色。
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewer替换以下内容:
- SERVICE_ACCOUNT_NAME:要创建的服务账号的名称。
- PROJECT_ID:在其中创建服务账号的 Google Cloud 项目。
向服务账号授予对机器学习流水线所需的任何资源或 API 的访问权限。 Google Cloud 详细了解 Identity and Access Management 角色和管理服务账号。
向服务账号授予用户账号的 Service Account User (
iam.serviceAccountUser) 角色。gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
替换以下内容:
- SERVICE_ACCOUNT_NAME:您的服务账号的名称。
- PROJECT_ID:您的 Google Cloud 项目。
- USERNAME:您在 Google Cloud上的用户名。
设置 GKE 集群
按照以下说明设置 GKE 集群。
在 Google Cloud 控制台中打开 Google Kubernetes Engine。
点击创建集群按钮。 此时将打开集群基本信息表单。
输入集群的名称。
对于位置类型,选择可用区,然后为您的集群选择所需的可用区。如需帮助决定使用哪个地区,请参阅有关地区选择的最佳做法。
在导航窗格的节点池下,点击默认池 (default-pool)。 此时将显示节点池详细信息表单。
输入要在集群中创建的节点数。您的集群必须具有 3 个或更多节点才能部署 AI Platform Pipelines。您必须具有节点及其资源(例如防火墙路由)的可用资源配额。
在导航窗格的节点池下,点击节点。 此时将打开节点表单。
选择要用于实例的默认机器配置。您必须选择具有至少 2 个 CPU 和 4 GB 内存的机器类型(例如
n1-standard-2),才能部署 AI Platform Pipelines。每种机器类型的计费方式都各不相同。如需了解机器类型价格信息,请参阅机器类型价格表。在导航窗格的节点池下,点击安全。此时将显示节点安全表单。
从服务账号下拉列表中,选择您之前在本指南中创建的服务账号。
否则,请根据需要配置 GKE 集群。详细了解如何创建 GKE 集群。
点击创建。
在 GKE 集群上安装 Kubeflow Pipelines
使用以下说明在 GKE 集群上设置 Kubeflow Pipelines。
在 Google Cloud Console 中打开 AI Platform Pipelines。
在 AI Platform Pipelines 工具栏中,点击新建实例。 Kubeflow Pipelines 将在 Google Cloud Marketplace 中打开。
点击配置。系统将打开部署 Kubeflow Pipelines 表单。
在集群下拉列表中,选择您在上一步中创建的集群。如果您要使用的集群不符合部署条件,请验证您的集群是否满足部署 Kubeflow Pipelines 的要求。
命名空间用于管理大型 GKE 集群中的资源。如果您不打算在集群中使用命名空间,请在命名空间下拉列表中选择默认。
如果您打算在 GKE 集群中使用命名空间,请使用命名空间下拉列表创建命名空间。如需创建命名空间,请执行以下操作:
- 在命名空间下拉列表中选择创建命名空间。此时会显示新建命名空间名称文本框。
- 在新建命名空间名称中输入命名空间名称。
如需详细了解命名空间,请参阅有关使用命名空间组织 Kubernetes 的博文。
在应用实例名称框中,输入 Kubeflow Pipelines 实例的名称。
借助托管存储,您可以使用 Cloud SQL 和 Cloud Storage 存储机器学习流水线的元数据和工件,而不是将它们存储在 Compute Engine 永久性磁盘上。通过使用代管式服务来存储流水线工件和元数据,可让您更轻松地备份和恢复集群的数据。若要部署具有托管存储的 Kubeflow Pipelines,请选择使用托管存储并提供以下信息:
工件存储 Cloud Storage 存储分区:借助托管存储,Kubeflow Pipelines 可将流水线工件存储在 Cloud Storage 存储分区中。指定您希望 Kubeflow Pipelines 在其中存储工件的存储分区的名称。如果指定的存储分区不存在,Kubeflow Pipelines 部署程序将在
us-central1地区中为您自动创建存储分区。Cloud SQL 实例连接名称:借助托管存储,Kubeflow Pipelines 可将流水线元数据存储在 Cloud SQL 上的 MySQL 数据库中。指定 Cloud SQL MySQL 实例的连接名称。
数据库用户名:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库用户名。目前,数据库用户必须具有
ALLMySQL 特权才能部署具有托管存储的 Kubeflow Pipelines。如果将此字段留空,则此值默认为 root。数据库密码:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库密码。如果将此字段留空,Kubeflow Pipelines 将在不提供密码的情况下连接到数据库;如果您指定的用户名需要密码,该操作将失败。
数据库名称前缀:指定数据库名称前缀。前缀值必须以字母开头,并且只能包含小写字母、数字和下划线。
在部署过程中,Kubeflow Pipelines 会创建两个数据库:“DATABASE_NAME_PREFIX_pipeline”和“DATABASE_NAME_PREFIX_metadata”。如果您的 MySQL 实例中存在使用这些名称的数据库,Kubeflow Pipelines 将重复使用现有数据库。如果未指定此值,则将使用应用实例名称作为数据库名称前缀。
点击部署。此步骤可能需要几分钟时间。
要访问流水线信息中心,请在 Google Cloud 控制台中打开 AI Platform Pipelines。
然后,如需查看您的 AI Platform Pipelines 实例,请点击打开流水线信息中心。
将 AI Platform Pipelines 部署到现有 GKE 集群
如需使用 Google Cloud Marketplace 在 GKE 集群上部署 Kubeflow Pipelines,必须满足以下条件:
- 您的集群必须至少有 3 个节点。每个节点必须至少有 2 个 CPU 和 4 GB 可用内存。
- 集群的访问权限范围必须授予对所有 Cloud API 的完整访问权限,否则您的集群必须使用自定义服务账号。
- 集群不能已安装 Kubeflow Pipelines。
详细了解如何为 AI Platform Pipelines 配置 GKE 集群。
使用以下说明在 GKE 集群上设置 Kubeflow Pipelines。
在 Google Cloud Console 中打开 AI Platform Pipelines。
在 AI Platform Pipelines 工具栏中,点击新建实例。 Kubeflow Pipelines 将在 Google Cloud Marketplace 中打开。
点击配置。系统将打开部署 Kubeflow Pipelines 表单。
在集群下拉列表中,选择您的集群。如果您要使用的集群不符合部署条件,请验证您的集群是否满足部署 Kubeflow Pipelines 的要求。
命名空间用于管理大型 GKE 集群中的资源。如果您的集群未使用命名空间,请在命名空间下拉列表中选择默认。
如果您的集群使用命名空间,请使用命名空间下拉列表选择现有命名空间或创建命名空间。如需创建命名空间,请执行以下操作:
- 在命名空间下拉列表中选择创建命名空间。此时会显示新建命名空间名称文本框。
- 在新建命名空间名称中输入命名空间名称。
如需详细了解命名空间,请参阅有关使用命名空间组织 Kubernetes 的博文。
在应用实例名称框中,输入 Kubeflow Pipelines 实例的名称。
借助托管存储,您可以使用 Cloud SQL 和 Cloud Storage 存储机器学习流水线的元数据和工件,而不是将它们存储在 Compute Engine 永久性磁盘上。通过使用代管式服务来存储流水线工件和元数据,可让您更轻松地备份和恢复集群的数据。若要部署具有托管存储的 Kubeflow Pipelines,请选择使用托管存储并提供以下信息:
工件存储 Cloud Storage 存储分区:借助托管存储,Kubeflow Pipelines 可将流水线工件存储在 Cloud Storage 存储分区中。指定您希望 Kubeflow Pipelines 在其中存储工件的存储分区的名称。如果指定的存储分区不存在,Kubeflow Pipelines 部署程序将在
us-central1地区中为您自动创建存储分区。Cloud SQL 实例连接名称:借助托管存储,Kubeflow Pipelines 可将流水线元数据存储在 Cloud SQL 上的 MySQL 数据库中。指定 Cloud SQL MySQL 实例的连接名称。
数据库用户名:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库用户名。目前,数据库用户必须具有
ALLMySQL 特权才能部署具有托管存储的 Kubeflow Pipelines。如果将此字段留空,则此值默认为 root。数据库密码:指定在连接到 MySQL 实例时 Kubeflow Pipelines 要使用的数据库密码。如果将此字段留空,Kubeflow Pipelines 将在不提供密码的情况下连接到数据库;如果您指定的用户名需要密码,该操作将失败。
数据库名称前缀:指定数据库名称前缀。前缀值必须以字母开头,并且只能包含小写字母、数字和下划线。
在部署过程中,Kubeflow Pipelines 会创建两个数据库:“DATABASE_NAME_PREFIX_pipeline”和“DATABASE_NAME_PREFIX_metadata”。如果您的 MySQL 实例中存在使用这些名称的数据库,Kubeflow Pipelines 将重复使用现有数据库。如果未指定此值,则将使用应用实例名称作为数据库名称前缀。
点击部署。此步骤可能需要几分钟时间。
要访问流水线信息中心,请在 Google Cloud 控制台中打开 AI Platform Pipelines。
然后,如需查看您的 AI Platform Pipelines 实例,请点击打开流水线信息中心。
后续步骤
- 将机器学习流程编排为流水线。
- 使用 Kubeflow Pipelines 界面运行流水线。
- 详细了解 AI Platform Pipelines 和机器学习流水线