Mit AI Platform Pipelines können Sie Workflows für maschinelles Lernen (ML) als wiederverwendbare und reproduzierbare Pipelines orchestrieren. AI Platform Pipelines erspart Ihnen die Einrichtung von Kubeflow Pipelines mit TensorFlow Extended in der Google Kubernetes Engine.
In dieser Anleitung werden mehrere Optionen zum Bereitstellen von AI Platform Pipelines in GKE beschrieben. Sie können Kubeflow Pipelines in einem vorhandenen GKE-Cluster bereitstellen oder einen neuen GKE-Cluster erstellen. Wenn Sie einen vorhandenen GKE-Cluster wiederverwenden möchten, stellen Sie sicher, dass Ihr Cluster die folgenden Anforderungen erfüllt.
- Ihr Cluster muss mindestens drei Knoten haben. Jeder Knoten muss mindestens zwei CPUs und 4 GB Arbeitsspeicher haben.
- Der Zugriffsbereich des Clusters muss vollständigen Zugriff auf alle Cloud APIs gewähren oder Ihr Cluster muss ein benutzerdefiniertes Dienstkonto verwenden.
- Auf dem Cluster darf Kubeflow Pipelines noch nicht installiert sein.
Wählen Sie die für Ihre Anforderungen beste Bereitstellungsoption aus:
- Mit AI Platform Pipelines einen neuen GKE-Cluster mit uneingeschränktem Zugriff auf Google Cloud erstellen und Kubeflow Pipelines im Cluster bereitstellen Diese Option vereinfacht die Bereitstellung und Verwendung von AI Platform Pipelines.
- Einen neuen GKE-Cluster mit detailliertem Zugriff aufGoogle Cloud erstellen und Kubeflow Pipelines in diesem Cluster bereitstellen. Mit dieser Option können Sie die Google Cloud Ressourcen und APIs angeben, auf die Arbeitslasten in Ihrem Cluster Zugriff haben.
- AI Platform Pipelines in einem vorhandenen GKE-Cluster bereitstellen. Hier wird beschrieben, wie AI Platform Pipelines in einem vorhandenen GKE-Cluster bereitgestellt wird.
Hinweis
Bevor Sie mit dieser Anleitung beginnen, prüfen Sie, ob Ihr Google Cloud Projekt richtig eingerichtet ist und Sie ausreichende Berechtigungen zum Bereitstellen von AI Platform Pipelines haben.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Folgen Sie der nachstehenden Anleitung, um festzustellen, ob Ihnen die für die Bereitstellung von AI Platform Pipelines erforderlichen Rollen zugewiesen wurden.
-
Öffnen Sie eine Cloud Shell-Sitzung.
Cloud Shell wird im unteren Bereich der Google Cloud Console in einem Frame geöffnet.
-
Sie müssen den Betrachter (
roles/viewer) und den Kubernetes Engine-Administrator (roles/container.admin), oder andere Rollen, die dieselben Berechtigungen wie die Inhaber-Rolle (roles/owner) in dem Projekt haben, um AI Platform Pipelines bereitzustellen. Führen Sie in Cloud Shell den folgenden Befehl aus, um die Hauptkonten mit den Rollen „Betrachter“ und „Kubernetes Engine-Administrator“ aufzulisten.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
Ersetzen Sie PROJECT_ID durch die ID Ihres Google Cloud-Projekts.
Stellen Sie anhand der Ausgabe dieses Befehls fest, ob Ihr Konto die Rollen "Betrachter" und "Kubernetes Engine-Administrator" hat.
-
Wenn Sie Ihrem Cluster detaillierten Zugriff gewähren möchten, müssen Sie auch die Rolle "Dienstkontoadministrator" (
roles/iam.serviceAccountAdmin) für das Projekt oder andere Rollen mit den gleichen Berechtigungen wie "Bearbeiter" haben (roles/editor) oder Inhaber (roles/owner) für das Projekt sein. Führen Sie in Cloud Shell den folgenden Befehl aus, um die Hauptkonten mit der Rolle „Dienstkontoadministrator“ aufzulisten.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
Ersetzen Sie PROJECT_ID durch die ID Ihres Google Cloud-Projekts.
Ermitteln Sie anhand der Befehlsausgabe, ob Ihr Konto die Rolle "Dienstkonto-Administrator" hat.
-
Wenn Sie die erforderlichen Rollen nicht haben, wenden Sie sich an Ihren Google Cloud-Projektadministrator.
Weitere Informationen dazu, wie Sie Identity and Access Management-Rollen zuweisen
-
AI Platform Pipelines mit uneingeschränktem Zugriff auf Google Cloud
AI Platform Pipelines erleichtert die Einrichtung und Verwendung von Kubeflow Pipelines, da automatisch ein GKE-Cluster erstellt und Kubeflow Pipelines auf dem Cluster bereitgestellt wird. Ein von AI Platform Pipelines erstellter GKE-Cluster verwendet das Compute Engine-Standarddienstkonto. Wenn Sie Ihrem Cluster vollständigen Zugriff auf die Google Cloud Ressourcen und APIs gewähren möchten, die Sie in Ihrem Projekt aktiviert haben, können Sie dem Cluster Zugriff auf den Zugriffsbereich https://www.googleapis.com/auth/cloud-platform gewähren. Wenn Sie auf diese Weise Zugriff gewähren, können ML-Pipelines, die auf Ihrem Cluster ausgeführt werden, auf Google CloudAPIs wie AI Platform Training und AI Platform Prediction zugreifen. Dieser Prozess erleichtert zwar die Einrichtung von AI Platform Pipelines, kann Ihren Pipelineentwicklern jedoch einen zu umfangreichen Zugriff auf Google Cloud Ressourcen und APIs gewähren.
Gehen Sie nach der folgenden Anleitung vor, um AI Platform Pipelines mit uneingeschränktem Zugriff auf Google Cloud -Ressourcen und ‑APIs bereitzustellen.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console.
Klicken Sie in der Symbolleiste von AI Platform Pipelines auf Neue Instanz. Kubeflow Pipelines wird in Google Cloud Marketplace geöffnet.
Klicken Sie auf Konfigurieren. Das Formular Kubeflow Pipelines bereitstellen wird geöffnet.
Wenn der Link Neuen Cluster erstellen angezeigt wird, klicken Sie auf Neuen Cluster erstellen. Ist dies nicht der Fall, fahren Sie mit dem nächsten Schritt fort.

Wählen Sie die Clusterzone aus, in der sich Ihr Cluster befinden soll. Tipps zur Wahl der Zone finden Sie in den Best Practices zur Auswahl der Region.
Aktivieren Sie Zugriff auf folgende Cloud APIs zulassen, um Anwendungen, die in Ihrem GKE-Cluster ausgeführt werden, Zugriff auf Google Cloud -Ressourcen zu gewähren. Durch Anklicken dieses Kästchens gewähren Sie Ihrem Cluster Zugriff auf den Zugriffsbereich
https://www.googleapis.com/auth/cloud-platform. Dieser Zugriffsbereich bietet uneingeschränkten Zugriff auf die Google Cloud Ressourcen, die Sie in Ihrem Projekt aktiviert haben. Wenn Sie Ihrem Cluster auf diese Weise Zugriff auf Google Cloud Ressourcen gewähren, müssen Sie weder ein Dienstkonto erstellen und verwalten noch ein Kubernetes-Secret erstellen.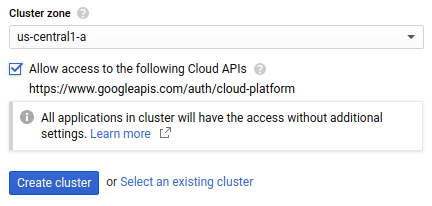
Klicken Sie auf Cluster erstellen. Dieser Schritt kann einige Minuten dauern.
Mithilfe von Namespaces werden Ressourcen in großen GKE-Clustern verwaltet. Wenn Sie keine Namespaces in Ihrem Cluster verwenden möchten, wählen Sie in der Drop-down-Liste Namespace die Option Standard aus.
Wenn Sie Namespaces in Ihrem GKE-Cluster verwenden möchten, erstellen Sie über die Drop-down-Liste Namespace einen Namespace. So erstellen Sie einen Namespace:
- Wählen Sie in der Drop-down-Liste Namespace die Option Namespace erstellen aus. Das Feld Name des neuen Namespace wird angezeigt.
- Geben Sie den Namespace-Namen unter Name des neuen Namespace ein.
Weitere Informationen zu Namespaces finden Sie in einem Blogpost zum Organisieren von Kubernetes mit Namespaces.
Geben Sie im Feld Name der Anwendungsinstanz einen Namen für Ihre Kubeflow Pipelines-Instanz ein.
Mit verwalteten Speichern können Sie die Metadaten und Artefakte Ihrer ML-Pipeline mithilfe von Cloud SQL und Cloud Storage speichern, anstatt sie auf nichtflüchtigen Compute Engine-Speichern zu speichern. Die Verwendung von verwalteten Diensten zum Speichern Ihrer Pipeline-Artefakte und -Metadaten erleichtert das Sichern und Wiederherstellen der Clusterdaten. Wählen Sie Verwaltete Speicher verwenden aus, um Kubeflow Pipelines mit einem verwalteten Speicher bereitzustellen:
Cloud Storage-Bucket-Artefakt: Mit verwalteter Speicherung speichert Kubeflow Pipelines Pipeline-Artefakte in einem Cloud Storage-Bucket. Geben Sie den Namen des Buckets an, in dem Kubeflow Pipelines Artefakte speichern soll. Wenn der angegebene Bucket nicht vorhanden ist, erstellt der Kubeflow Pipelines-Bereitsteller automatisch einen Bucket für Sie in der Region
us-central1.Name der Cloud SQL-Instanzverbindung: Bei der verwalteten Speicherung speichert Kubeflow Pipelines Pipeline-Metadaten in einer MySQL-Datenbank in Cloud SQL. Geben Sie den Verbindungsnamen für die MySQL-Instanz von Cloud SQL an.
Weitere Informationen zum Einrichten einer Cloud SQL-Instanz
Datenbank-Nutzername: Geben Sie den Datenbank-Nutzernamen für Kubeflow Pipelines an, die beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden sollen. Derzeit muss der Datenbanknutzer
ALL-MySQL-Berechtigungen haben, um Kubeflow Pipelines mit verwaltetem Speicher bereitstellen zu können. Wenn Sie dieses Feld leer lassen, wird standardmäßig root verwendet.Datenbankpasswort: Geben Sie das Datenbankpasswort für Kubeflow Pipelines an, das beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden soll. Wenn Sie dieses Feld leer lassen, stellt Kubeflow Pipelines eine Verbindung zu Ihrer Datenbank her, ohne ein Passwort anzugeben. Dabei tritt ein Fehler auf, wenn für den angegebenen Nutzernamen ein Passwort erforderlich ist.
Namenspräfix der Datenbank: Geben Sie das Präfix des Datenbanknamens an. Der Präfixwert muss mit einem Buchstaben beginnen und darf nur Kleinbuchstaben, Ziffern und Unterstriche enthalten.
Während des Bereitstellungsprozesses erstellt Kubeflow Pipelines zwei Datenbanken: "DATABASE_NAME_PREFIX_pipeline" und "DATABASE_NAME_PREFIX_metadata". Wenn in Ihrer MySQL-Instanz Datenbanken mit diesen Namen vorhanden sind, verwendet Kubeflow Pipelines die vorhandenen Datenbanken. Wenn dieser Wert nicht angegeben ist, wird der Name der Anwendungsinstanz als Präfix für den Datenbanknamen verwendet.
Klicken Sie auf Bereitstellen. Dieser Schritt kann einige Minuten dauern.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console, um auf das Pipeline-Dashboard zuzugreifen.
Klicken Sie dann für Ihre AI Platform Pipelines-Instanz auf Pipelines-Dashboard öffnen.
AI Platform Pipelines mit detailliertem Zugriff auf Google Cloudbereitstellen
ML-Pipelines greifen über das Dienstkonto und den Zugriffsbereich des Knotenpools des GKE-Clusters auf Google Cloud Ressourcen zu. Derzeit müssen Sie AI Platform Pipelines in einem GKE-Cluster bereitstellen, der ein vom Nutzer verwaltetes Dienstkonto verwendet, um den Zugriff Ihres Clusters auf bestimmte Google Cloud Ressourcen zu beschränken.
Gehen Sie nach der Anleitung in den folgenden Abschnitten vor, um ein Dienstkonto zu erstellen und zu konfigurieren, einen GKE-Cluster zu erstellen, der Ihr Dienstkonto verwendet, und Kubeflow Pipelines in Ihrem GKE-Cluster bereitzustellen.
Dienstkonto für Ihren GKE-Cluster erstellen
Gehen Sie nach der folgenden Anleitung vor, um ein Dienstkonto für Ihren GKE-Cluster einzurichten.
Öffnen Sie eine Cloud Shell-Sitzung.
Cloud Shell wird im unteren Bereich der Google Cloud Console in einem Frame geöffnet.
Führen Sie in Cloud Shell die folgenden Befehle aus, um Ihr Dienstkonto zu erstellen und diesem ausreichenden Zugriff für das Ausführen von AI Platform Pipelines zu gewähren. Weitere Informationen zu den Rollen, die zum Ausführen von AI Platform Pipelines mit einem nutzerverwalteten Dienstkonto erforderlich sind
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewerErsetzen Sie Folgendes:
- SERVICE_ACCOUNT_NAME: Name des zu erstellenden Dienstkontos.
- PROJECT_ID: Google Cloud-Projekt, in dem das Dienstkonto erstellt wird.
Gewähren Sie Ihrem Dienstkonto Zugriff auf alle Google Cloud Ressourcen oder APIs, die für Ihre ML-Pipelines erforderlich sind. Weitere Informationen zu IAM-Rollen (Identitäts- und Zugriffsverwaltung) und zum Verwalten von Dienstkonten
Weisen Sie Ihrem Nutzerkonto die Rolle "Dienstkontonutzer" (
iam.serviceAccountUser) für das Dienstkonto zu.gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
Ersetzen Sie Folgendes:
- SERVICE_ACCOUNT_NAME: Name Ihres Dienstkontos.
- PROJECT_ID: Ihr Google Cloud-Projekt.
- USERNAME: Ihr Nutzername bei Google Cloud.
GKE-Cluster einrichten
Gehen Sie nach der folgenden Anleitung vor, um Ihren GKE-Cluster einzurichten.
Öffnen Sie Google Kubernetes Engine in der Google Cloud Console.
Klicken Sie auf Cluster erstellen. Das Formular Clustergrundlagen wird geöffnet.
Geben Sie den Namen für den Cluster ein.
Wählen Sie als Standorttyp die Option Zonal und dann die gewünschte Zone für den Cluster aus. Tipps zur Wahl der Zone finden Sie in den Best Practices zur Auswahl der Region.
Klicken Sie im Navigationsbereich unter Knotenpools auf default-pool. Das Formular Knotenpooldetails wird angezeigt.
Geben Sie die Anzahl der Knoten ein, die im Cluster erstellt werden sollen. Ihr Cluster muss für die Bereitstellung von AI Platform Pipelines mindestens drei Knoten haben. Sie müssen verfügbare Ressourcenkontingente für die Knoten und ihre Ressourcen (z. B. Firewallrouten) haben.
Klicken Sie im Navigationsbereich unter Knotenpools auf Knoten. Das Formular Knoten wird geöffnet.
Wählen Sie die Maschinenkonfiguration aus, die standardmäßig für die Instanzen verwendet werden soll. Sie müssen einen Maschinentyp mit mindestens zwei CPUs und 4 GB Arbeitsspeicher wie
n1-standard-2auswählen, um AI Platform Pipelines bereitzustellen. Jeder Maschinentyp wird unterschiedlich abgerechnet. Informationen zu den Preisen für Maschinentypen finden Sie in der Preisübersicht für Maschinentypen.Klicken Sie im Navigationsbereich unter Knotenpools auf Sicherheit. Das Formular Knotensicherheit wird angezeigt.
Wählen Sie in der Drop-down-Liste Dienstkonto das Dienstkonto aus, das Sie in einem vorherigen Schritt dieser Anleitung erstellt haben.
Konfigurieren Sie andernfalls den GKE-Cluster wie gewünscht. Weitere Informationen zum Erstellen eines GKE-Clusters
Klicken Sie auf Erstellen.
Kubeflow Pipelines auf Ihrem GKE-Cluster installieren
Verwenden Sie die folgende Anleitung, um Kubeflow Pipelines für einen GKE-Cluster einzurichten.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console.
Klicken Sie in der Symbolleiste von AI Platform Pipelines auf Neue Instanz. Kubeflow Pipelines wird in Google Cloud Marketplace geöffnet.
Klicken Sie auf Konfigurieren. Das Formular Kubeflow Pipelines bereitstellen wird geöffnet.
Wählen Sie in der Drop-down-Liste Cluster den Cluster aus, den Sie in einem früheren Schritt erstellt haben. Wenn der Cluster, den Sie verwenden möchten, nicht für das Deployment zur Verfügung steht, prüfen Sie, ob Ihr Cluster die Anforderungen zum Bereitstellen von Kubeflow Pipelines erfüllt.
Mithilfe von Namespaces werden Ressourcen in großen GKE-Clustern verwaltet. Wenn Sie keine Namespaces in Ihrem Cluster verwenden möchten, wählen Sie in der Drop-down-Liste Namespace die Option Standard aus.
Wenn Sie Namespaces in Ihrem GKE-Cluster verwenden möchten, erstellen Sie über die Drop-down-Liste Namespace einen Namespace. So erstellen Sie einen Namespace:
- Wählen Sie in der Drop-down-Liste Namespace die Option Namespace erstellen aus. Das Feld Name des neuen Namespace wird angezeigt.
- Geben Sie den Namespace-Namen unter Name des neuen Namespace ein.
Weitere Informationen zu Namespaces finden Sie in einem Blogpost zum Organisieren von Kubernetes mit Namespaces.
Geben Sie im Feld Name der Anwendungsinstanz einen Namen für Ihre Kubeflow Pipelines-Instanz ein.
Mit verwalteten Speichern können Sie die Metadaten und Artefakte Ihrer ML-Pipeline mithilfe von Cloud SQL und Cloud Storage speichern, anstatt sie auf nichtflüchtigen Compute Engine-Speichern zu speichern. Die Verwendung von verwalteten Diensten zum Speichern Ihrer Pipeline-Artefakte und -Metadaten erleichtert das Sichern und Wiederherstellen der Clusterdaten. Wählen Sie Verwaltete Speicher verwenden aus, um Kubeflow Pipelines mit einem verwalteten Speicher bereitzustellen:
Cloud Storage-Bucket-Artefakt: Mit verwalteter Speicherung speichert Kubeflow Pipelines Pipeline-Artefakte in einem Cloud Storage-Bucket. Geben Sie den Namen des Buckets an, in dem Kubeflow Pipelines Artefakte speichern soll. Wenn der angegebene Bucket nicht vorhanden ist, erstellt der Kubeflow Pipelines-Bereitsteller automatisch einen Bucket für Sie in der Region
us-central1.Name der Cloud SQL-Instanzverbindung: Bei der verwalteten Speicherung speichert Kubeflow Pipelines Pipeline-Metadaten in einer MySQL-Datenbank in Cloud SQL. Geben Sie den Verbindungsnamen für die MySQL-Instanz von Cloud SQL an.
Weitere Informationen zum Einrichten einer Cloud SQL-Instanz
Datenbank-Nutzername: Geben Sie den Datenbank-Nutzernamen für Kubeflow Pipelines an, die beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden sollen. Derzeit muss der Datenbanknutzer
ALL-MySQL-Berechtigungen haben, um Kubeflow Pipelines mit verwaltetem Speicher bereitstellen zu können. Wenn Sie dieses Feld leer lassen, wird standardmäßig root verwendet.Datenbankpasswort: Geben Sie das Datenbankpasswort für Kubeflow Pipelines an, das beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden soll. Wenn Sie dieses Feld leer lassen, stellt Kubeflow Pipelines eine Verbindung zu Ihrer Datenbank her, ohne ein Passwort anzugeben. Dabei tritt ein Fehler auf, wenn für den angegebenen Nutzernamen ein Passwort erforderlich ist.
Namenspräfix der Datenbank: Geben Sie das Präfix des Datenbanknamens an. Der Präfixwert muss mit einem Buchstaben beginnen und darf nur Kleinbuchstaben, Ziffern und Unterstriche enthalten.
Während des Bereitstellungsprozesses erstellt Kubeflow Pipelines zwei Datenbanken: "DATABASE_NAME_PREFIX_pipeline" und "DATABASE_NAME_PREFIX_metadata". Wenn in Ihrer MySQL-Instanz Datenbanken mit diesen Namen vorhanden sind, verwendet Kubeflow Pipelines die vorhandenen Datenbanken. Wenn dieser Wert nicht angegeben ist, wird der Name der Anwendungsinstanz als Präfix für den Datenbanknamen verwendet.
Klicken Sie auf Bereitstellen. Dieser Schritt kann einige Minuten dauern.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console, um auf das Pipeline-Dashboard zuzugreifen.
Klicken Sie dann für Ihre AI Platform Pipelines-Instanz auf Pipelines-Dashboard öffnen.
AI Platform Pipelines in einem vorhandenen GKE-Cluster bereitstellen
Damit Sie Kubeflow Pipelines mit Google Cloud Marketplace in einem GKE-Cluster bereitstellen können, müssen folgende Bedingungen erfüllt sein:
- Ihr Cluster muss mindestens drei Knoten haben. Jeder Knoten muss mindestens zwei CPUs und 4 GB Arbeitsspeicher haben.
- Der Zugriffsbereich des Clusters muss vollständigen Zugriff auf alle Cloud APIs gewähren oder Ihr Cluster muss ein benutzerdefiniertes Dienstkonto verwenden.
- Auf dem Cluster darf Kubeflow Pipelines noch nicht installiert sein.
Weitere Informationen zum Konfigurieren Ihres GKE-Clusters für AI Platform Pipelines
Verwenden Sie die folgende Anleitung, um Kubeflow Pipelines für einen GKE-Cluster einzurichten.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console.
Klicken Sie in der Symbolleiste von AI Platform Pipelines auf Neue Instanz. Kubeflow Pipelines wird in Google Cloud Marketplace geöffnet.
Klicken Sie auf Konfigurieren. Das Formular Kubeflow Pipelines bereitstellen wird geöffnet.
Wählen Sie in der Drop-down-Liste Cluster Ihren Cluster aus. Wenn der Cluster, den Sie verwenden möchten, nicht für das Deployment zur Verfügung steht, prüfen Sie, ob Ihr Cluster die Anforderungen zum Bereitstellen von Kubeflow Pipelines erfüllt.
Mithilfe von Namespaces werden Ressourcen in großen GKE-Clustern verwaltet. Wenn Ihr Cluster keine Namespaces verwendet, wählen Sie in der Drop-down-Liste Namespace die Option Standard aus.
Wenn Ihr Cluster Namespaces verwendet, wählen Sie einen vorhandenen Namespace aus oder erstellen Sie einen Namespace mithilfe der Drop-down-Liste Namespace. So erstellen Sie einen Namespace:
- Wählen Sie in der Drop-down-Liste Namespace die Option Namespace erstellen aus. Das Feld Name des neuen Namespace wird angezeigt.
- Geben Sie den Namespace-Namen unter Name des neuen Namespace ein.
Weitere Informationen zu Namespaces finden Sie in einem Blogpost zum Organisieren von Kubernetes mit Namespaces.
Geben Sie im Feld Name der Anwendungsinstanz einen Namen für Ihre Kubeflow Pipelines-Instanz ein.
Mit verwalteten Speichern können Sie die Metadaten und Artefakte Ihrer ML-Pipeline mithilfe von Cloud SQL und Cloud Storage speichern, anstatt sie auf nichtflüchtigen Compute Engine-Speichern zu speichern. Die Verwendung von verwalteten Diensten zum Speichern Ihrer Pipeline-Artefakte und -Metadaten erleichtert das Sichern und Wiederherstellen der Clusterdaten. Wählen Sie Verwaltete Speicher verwenden aus, um Kubeflow Pipelines mit einem verwalteten Speicher bereitzustellen:
Cloud Storage-Bucket-Artefakt: Mit verwalteter Speicherung speichert Kubeflow Pipelines Pipeline-Artefakte in einem Cloud Storage-Bucket. Geben Sie den Namen des Buckets an, in dem Kubeflow Pipelines Artefakte speichern soll. Wenn der angegebene Bucket nicht vorhanden ist, erstellt der Kubeflow Pipelines-Bereitsteller automatisch einen Bucket für Sie in der Region
us-central1.Name der Cloud SQL-Instanzverbindung: Bei der verwalteten Speicherung speichert Kubeflow Pipelines Pipeline-Metadaten in einer MySQL-Datenbank in Cloud SQL. Geben Sie den Verbindungsnamen für die MySQL-Instanz von Cloud SQL an.
Weitere Informationen zum Einrichten einer Cloud SQL-Instanz
Datenbank-Nutzername: Geben Sie den Datenbank-Nutzernamen für Kubeflow Pipelines an, die beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden sollen. Derzeit muss der Datenbanknutzer
ALL-MySQL-Berechtigungen haben, um Kubeflow Pipelines mit verwaltetem Speicher bereitstellen zu können. Wenn Sie dieses Feld leer lassen, wird standardmäßig root verwendet.Datenbankpasswort: Geben Sie das Datenbankpasswort für Kubeflow Pipelines an, das beim Herstellen einer Verbindung zu Ihrer MySQL-Instanz verwendet werden soll. Wenn Sie dieses Feld leer lassen, stellt Kubeflow Pipelines eine Verbindung zu Ihrer Datenbank her, ohne ein Passwort anzugeben. Dabei tritt ein Fehler auf, wenn für den angegebenen Nutzernamen ein Passwort erforderlich ist.
Namenspräfix der Datenbank: Geben Sie das Präfix des Datenbanknamens an. Der Präfixwert muss mit einem Buchstaben beginnen und darf nur Kleinbuchstaben, Ziffern und Unterstriche enthalten.
Während des Bereitstellungsprozesses erstellt Kubeflow Pipelines zwei Datenbanken: "DATABASE_NAME_PREFIX_pipeline" und "DATABASE_NAME_PREFIX_metadata". Wenn in Ihrer MySQL-Instanz Datenbanken mit diesen Namen vorhanden sind, verwendet Kubeflow Pipelines die vorhandenen Datenbanken. Wenn dieser Wert nicht angegeben ist, wird der Name der Anwendungsinstanz als Präfix für den Datenbanknamen verwendet.
Klicken Sie auf Bereitstellen. Dieser Schritt kann einige Minuten dauern.
Öffnen Sie AI Platform Pipelines in der Google Cloud Console, um auf das Pipeline-Dashboard zuzugreifen.
Klicken Sie dann für Ihre AI Platform Pipelines-Instanz auf Pipelines-Dashboard öffnen.
Nächste Schritte
- ML-Prozess als Pipeline orchestrieren
- Mit der Benutzeroberfläche von Kubeflow Pipelines eine Pipeline ausführen
- Mehr zu AI Platform Pipelines und ML-Pipelines