このページでは、テキストモデルとチャットモデルのチューニングとテキストモデルの抽出の概要について説明します。利用可能なチューニングの種類と、抽出の仕組みについて説明します。また、チューニングと抽出のメリットと、テキストモデルをチューニングまたは抽出する必要があるシナリオについても説明します。
モデルをチューニングする
テキストモデルをチューニングするには、次のいずれかの方法を選択します。
教師ありのチューニング - テキスト生成モデルとテキスト チャットモデルは、教師ありのチューニングをサポートしています。テキストモデルの教師ありチューニングは、モデルの出力が複雑ではなく、比較的定義が簡単な場合に適しています。分類、感情分析、エンティティ抽出、複雑でないコンテンツの要約、ドメイン固有のクエリの作成には、教師ありのチューニングが推奨されます。コードモデルの場合は、教師ありのチューニングが唯一の選択肢です。教師ありチューニングを使用してテキストモデルをチューニングする方法については、教師ありチューニングを使用してテキストモデルをチューニングするをご覧ください。
人間からのフィードバックを用いた強化学習(RLHF) - テキスト生成基盤モデルと一部の Flan Text-to-Text Transfer Transformer(Flan-T5)モデルは、RLHF チューニングをサポートしています。RLHF チューニングは、モデルの出力が複雑な場合に適しています。RLHF は、教師ありのチューニングでは簡単に区別できないシーケンス レベルの目標を持つモデルで良好に機能します。RLHF チューニングは、質問応答、複雑なコンテンツの要約、リライトなどのコンテンツ作成に推奨されます。RLHF チューニングを使用してテキストモデルをチューニングする方法については、RLHF チューニングを使用してテキストモデルをチューニングするをご覧ください。
テキストモデルのチューニングのメリット
チューニング済みテキストモデルは、プロンプトに収まりきらない多くの例でトレーニングされています。このため、事前トレーニング済みモデルをチューニングした後は、元の事前トレーニング済みモデルの場合よりも、プロンプトに表示する例を少なくできます。必要な例の数を削減できることには、次のようなメリットがあります。
- リクエストのレイテンシを短縮できます。
- 使用されるトークンが少なくなります。
- レイテンシを短縮し、トークンを減らすことで、推論の費用を抑えることができます。
モデル抽出
Vertex AI は、教師ありチューニングと RLHF チューニングに加えて、モデル抽出をサポートしています。抽出とは、大規模な教師モデルで小規模な生徒モデルをトレーニングし、サイズを縮小しながら大規模なモデルの動作を模倣するプロセスです。
モデル抽出には、次のようなタイプがあります。
- レスポンス ベース: 教師モデルのレスポンス確率に基づいて、生徒モデルをトレーニングします。
- 特徴ベース: 教師モデルの内部レイヤを模倣するように生徒モデルをトレーニングします。
- リレーションベース: 教師モデルの入力データまたは出力データのリレーションに基づいて、生徒モデルをトレーニングします。
- 自己抽出: 教師モデルと生徒モデルが同じアーキテクチャで、モデルは自己学習します。
段階的な抽出のメリット
段階的な抽出のメリットは次のとおりです。
- 精度の向上: LLM では、段階的な抽出により、標準的な少数ショット プロンプトよりも優れた結果を得ることができます。
- 抽出された LLM は、はるかに大規模な LLM の結果と同様の結果をユーザー固有の最終タスクで達成できます。
- データの制約の克服。DSS では、サンプルが数千件ほどの、ラベルなしのプロンプト データセットを使用できます。
- ホスティング フットプリントの縮小。
- 推論レイテンシの短縮。
Vertex AI を使用した段階的な抽出
Vertex AI は、段階的な抽出(DSS)というレスポンスベースの抽出をサポートしています。DSS は、思考の連鎖(COT)プロンプトを通じて、タスク固有の小規模なモデルをトレーニングする方法です。
DSS を使用するには、入力とラベルで構成される小さなトレーニング データセットが必要です。ラベルが利用できない場合は、教師モデルがラベルを生成します。DSS プロセスによって根拠が抽出され、根拠生成タスクと一般的な予測タスクで小さなモデルをトレーニングする際に使用されます。これにより、小さなモデルでも最終的な予測に到達する前に中間推論を構築できます。
次の図は、段階的な抽出で COT プロンプトを使用して大規模言語モデル(LLM)から根拠を抽出する方法を示しています。根拠は、より小さなタスク固有のモデルをトレーニングするために使用されます。
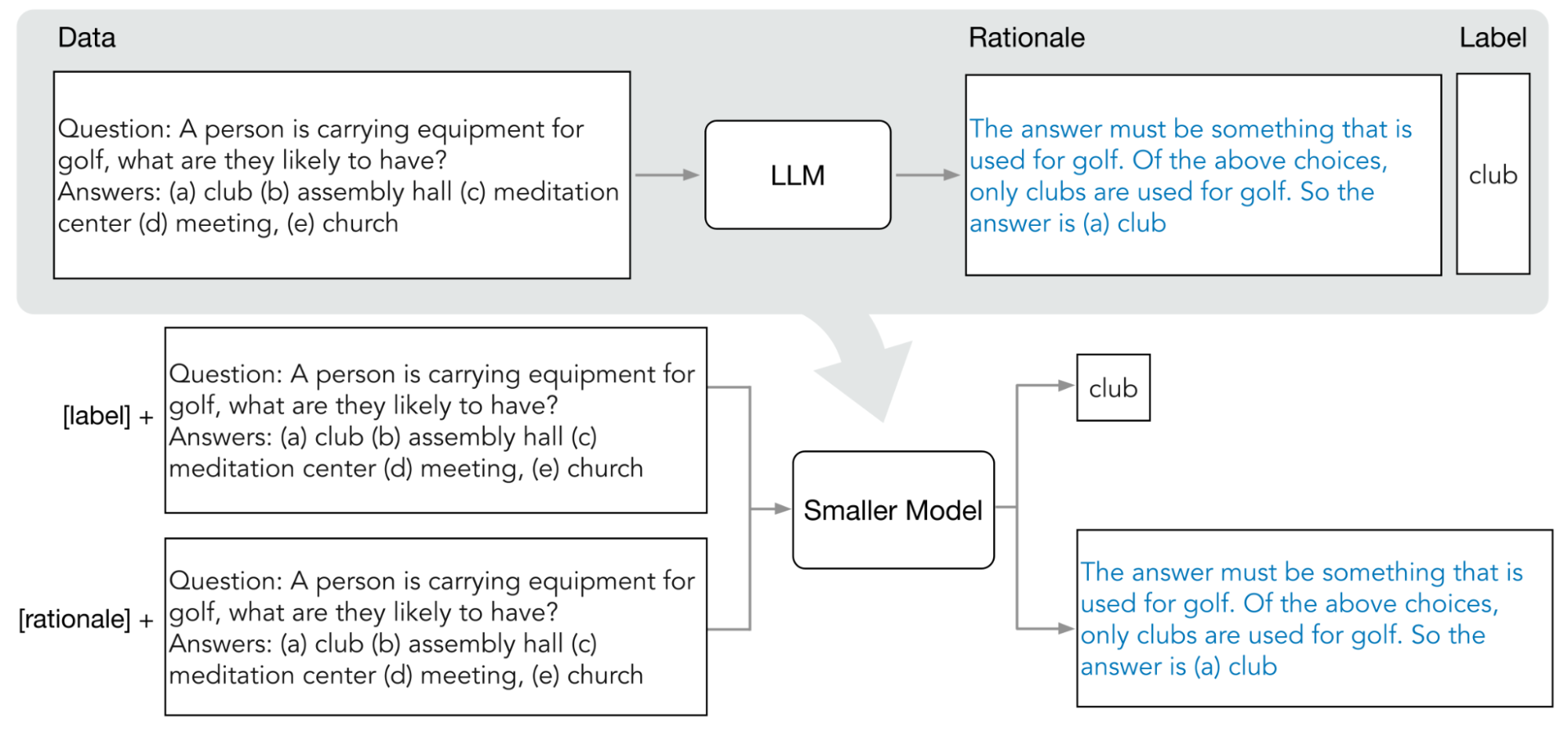
割り当て
Google Cloud の各プロジェクトには、1 つのチューニング ジョブの実行に十分な割り当てが必要です。1 つのチューニング ジョブでは 8 個の GPU を使用します。プロジェクトに 1 つのチューニング ジョブの実行に十分な割り当てがない場合や、プロジェクトで複数のチューニング ジョブを同時に実行する場合は、追加の割り当てをリクエストする必要があります。
次の表は、チューニングを行うために指定したリージョン別に、リクエストする割り当てのタイプと量を示しています。
| リージョン | リソース割り当て | 同時実行ジョブあたりの量 |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
料金
基盤モデルをチューニングまたは抽出する場合は、チューニング パイプラインまたは抽出パイプラインを実行するための費用が発生します。チューニングまたは抽出された基盤モデルを Vertex AI エンドポイントにデプロイする場合、ホスティングは無料です。予測のサービングについては、チューニングされていない基盤モデル(チューニングの場合)または生徒モデル(抽出の場合)を使用して予測のサービングを行う場合と同じ費用が発生します。チューニングと抽出が可能な基盤モデルについては、基盤モデルをご覧ください。料金の詳細については、Vertex AI での生成 AI の料金をご覧ください。
次のステップ
- 教師ありチューニングを使用して基盤モデルをチューニングする方法を学習する。
- RLHF チューニングを使用して基盤モデルをチューニングする方法を学習する。
- コードモデルをチューニングする方法を学ぶ。
- テキストモデルを抽出する方法を学習する。