Introduction
La prévision et la détection d'anomalies sur des milliards de séries temporelles sont des opérations informatiquement intensives. La plupart des systèmes existants exécutent des prévisions et une détection d'anomalies en tant que tâches par lot (par exemple, des pipelines de risque, des prévisions de trafic, une planification de la demande, etc.). Cela limite fortement le type d'analyse que vous pouvez effectuer en ligne, par exemple pour décider d'envoyer une alerte en fonction d'une augmentation ou d'une diminution soudaine sur un ensemble de dimensions d'événement.
Les principaux objectifs de l'API Timeseries Insights sont les suivants:
- Évoluez à des milliards de séries temporelles créées de manière dynamique à partir d'événements bruts et de leurs propriétés, en fonction des paramètres de requête.
- Fournissez des prévisions et des résultats de détection d'anomalies en temps réel. Autrement dit, en quelques secondes, détecter les tendances et la saisonnalité dans toutes les séries temporelles, et déterminer si des segments enregistrent des pics ou des baisses inattendus.
Fonctionnalités de l'API
- Gérer les ensembles de données
- Indexez et chargez un ensemble de données constitué de plusieurs sources de données stockées sur Cloud Storage. Autoriser l'ajout de nouveaux événements en streaming.
- Décharger un ensemble de données dont vous n'avez plus besoin.
- Demander l'état de traitement d'un ensemble de données.
- Interroger des ensembles de données
- Récupérez la série temporelle correspondant aux valeurs de propriété données. La série temporelle est prévue jusqu'à un horizon temporel spécifié. La série temporelle est également évaluée pour détecter les anomalies.
- Détecter automatiquement les combinaisons de valeurs de propriété pour les anomalies
- Mettre à jour des ensembles de données
- Ingérez les nouveaux événements qui se sont récemment produits et incorporez-les à l'index en temps quasi réel (avec un délai de quelques secondes à quelques minutes).
Reprise après sinistre
L'API Timeseries Insights ne sert pas de sauvegarde pour Cloud Storage et ne renvoie pas de mises à jour brutes en streaming. Les clients sont tenus de stocker et de sauvegarder les données séparément.
Après une panne régionale, le service effectue une récupération au mieux. Les métadonnées (informations sur le jeu de données et l'état opérationnel) et les données utilisateur en streaming mises à jour dans les 24 heures suivant le début de l'indisponibilité ne sont pas toujours récupérables.
Lors de la récupération, les requêtes et les mises à jour par flux des ensembles de données peuvent ne pas être disponibles.
Données d'entrée
Il est courant que des données numériques et catégorielles soient collectées au fil du temps. Par exemple, la figure suivante montre l'utilisation du processeur, l'utilisation de la mémoire et l'état d'une seule tâche en cours d'exécution dans un centre de données toutes les minutes sur une période donnée. L'utilisation du processeur et de la mémoire sont des valeurs numériques, et l'état est une valeur catégorielle.
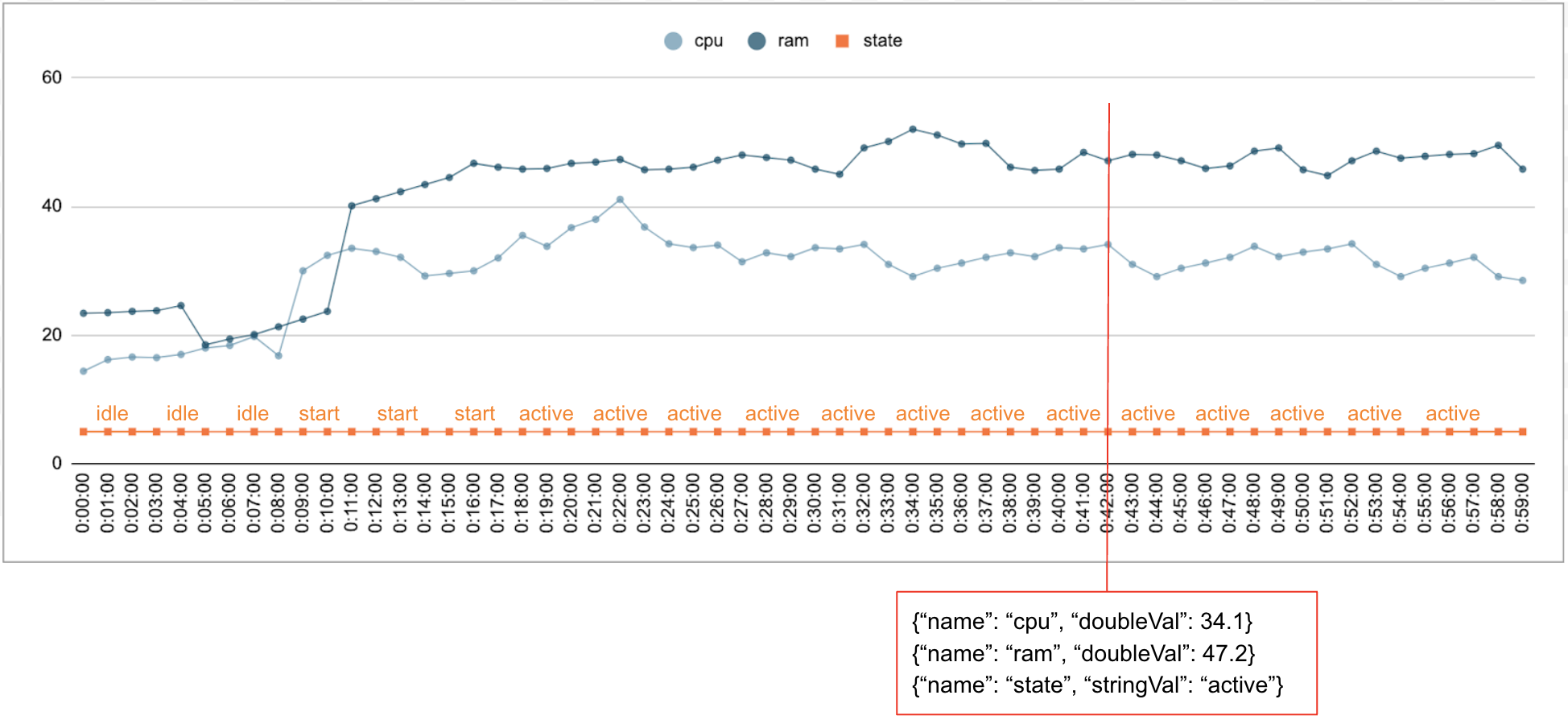
Événement
L'API Timeseries Insights utilise les événements comme entrée de données de base. Chaque événement est associé à un code temporel et à un ensemble de dimensions, c'est-à-dire de paires clé-valeur où la clé correspond au nom de la dimension. Cette représentation simple nous permet de gérer des données à l'échelle de milliards. Par exemple, pour un événement unique, le centre de données, l'utilisateur, les noms de tâche et les numéros de tâche sont inclus. La figure ci-dessus montre une série d'événements enregistrés pour une seule tâche illustrant un sous-ensemble de dimensions.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
Un DataSet est une collection d'événements. Les requêtes sont effectuées dans le même ensemble de données. Chaque projet peut comporter plusieurs ensembles de données.
Un ensemble de données est créé à partir de données par lot et de données par flux. La création de données par lot lit à partir de plusieurs URI Cloud Storage en tant que sources de données. Une fois la compilation par lot terminée, l'ensemble de données peut être mis à jour avec des données en streaming. En utilisant la compilation par lot pour les données historiques, le système peut éviter les problèmes de démarrage à froid.
Un ensemble de données doit être créé ou indexé avant de pouvoir être interrogé ou mis à jour. L'indexation démarre une fois l'ensemble de données créé et prend généralement quelques minutes à plusieurs heures, en fonction de la quantité de données. Plus précisément, les sources de données sont analysées une seule fois lors de l'indexation initiale. Si le contenu des URI Cloud Storage change une fois l'indexation initiale terminée, ces derniers ne sont pas analysés. Utilisez les mises à jour en streaming pour obtenir des données supplémentaires. Les mises à jour en streaming sont indexées presque en temps réel.
Séries temporelles et détection d'anomalies
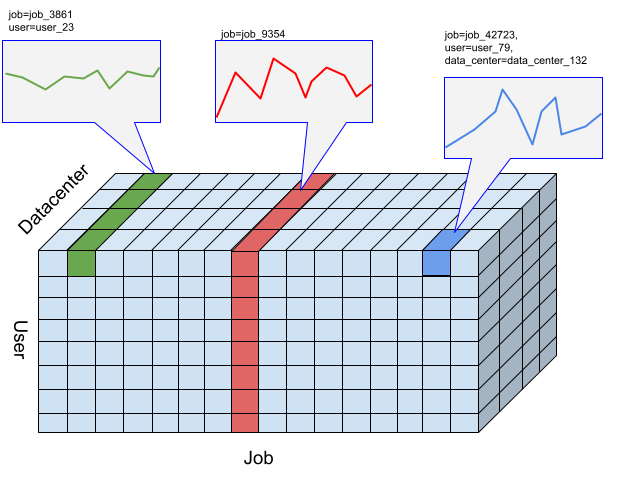
Pour l'API Timeseries Insights, une tranche est une collection d'événements avec une certaine combinaison de valeurs de dimension. Nous voulons connaître la mesure des événements qui se trouvent dans ces tranches au fil du temps.
Pour un certain nombre d'événements, les événements sont agrégés en valeurs numériques par résolution spécifiée par l'utilisateur et qui correspondent aux intervalles de temps spécifiés par la série. La figure précédente illustre différents choix de tranches résultant de différentes combinaisons des dimensions "user", "job" et "data_center".
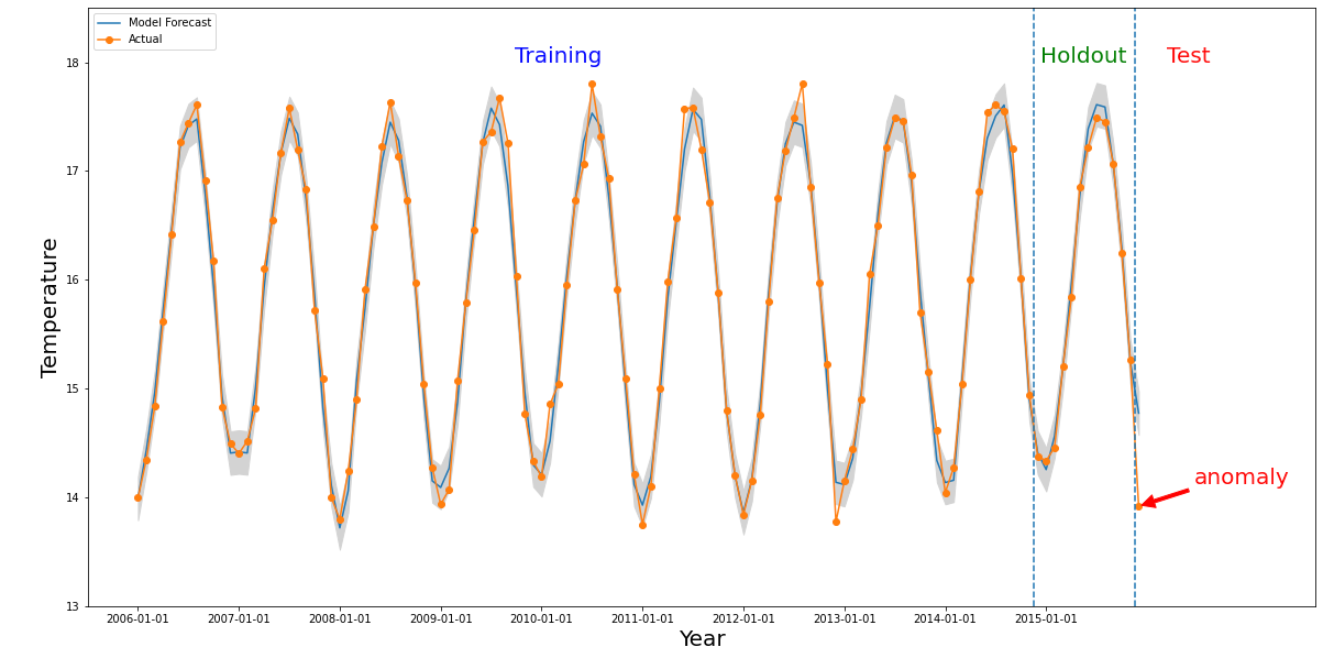
Une anomalie se produit pour une tranche donnée si la valeur numérique de l'intervalle de temps d'intérêt est très différente des valeurs du passé. La figure ci-dessus illustre une série temporelle basée sur les températures mesurées dans le monde entier sur 10 ans. Supposons que nous souhaitons savoir si le dernier mois de 2015 est une anomalie. Une requête adressée au système spécifie l'heure d'intérêt, detectionTime, à "2015/12/01" et granularity à "1 mois". Les séries temporelles récupérées avant que detectionTime ne soient partitionnées en une période de formation antérieure, suivie d'une période de holdout. Le système utilise les données de la période d'entraînement pour entraîner un modèle, et utilise la période de retenue pour vérifier que le modèle peut prédire de manière fiable les valeurs suivantes. Dans cet exemple, la période de retenue est d'un an. L'image montre les données réelles et les valeurs prédites du modèle avec des limites supérieure et inférieure. La température de 2015/12 est indiquée comme étant une anomalie, car la valeur réelle est en dehors des limites de la prédiction.